







参考
实验题目
利用MPI实现并行排序算法PSRS
实验环境
| 操作系统 | 编译器 | 硬件配置 |
|---|---|---|
|
|
|
|
算法设计与分析
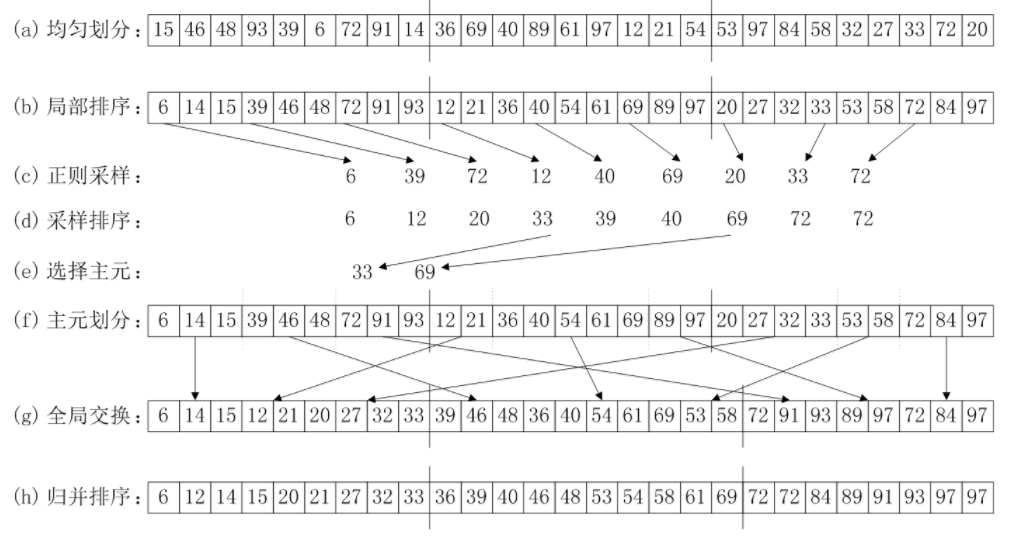
均匀划分 & 局部排序
a为原始数组,n为数组大小,numprocs为线程数,myid为线程号。使用qsort函数进行排序。// 各线程分别进行局部排序
qsort(a+n/numprocs*myid, n/numprocs, sizeof(int), cmp);
正则采样
a1为样本数组。各线程采集完样本后通过广播到其他进程。// 选取样本
int *a1 = (int*)malloc(numprocs*numprocs*sizeof(int));
for(int i = 0; i < numprocs; i++){
a1[numprocs*myid + i] = a[n/numprocs*myid+n/(numprocs*numprocs)*i];
}
MPI_Barrier(MPI_COMM_WORLD);
for(int i = 0; i < numprocs; i++){
MPI_Bcast(a1+numprocs*i, numprocs*sizeof(int), MPI_BYTE, i, MPI_COMM_WORLD);
}
采样排序 & 选择主元
a2为主元数组。在0号线程内对样本数组进行排序,然后选择主元,并广播到其他进程。// 选取主元
int *a2 = (int*)malloc((numprocs - 1)*sizeof(int));
if(myid == 0){
qsort(a1, numprocs*numprocs, sizeof(int), cmp);
for(int i = 0; i < numprocs - 1; i++){
a2[i] = a1[numprocs*(i + 1)];
}
}
// 把主元广播到所有进程
MPI_Bcast(a2, (numprocs-1)*sizeof(int), MPI_BYTE, 0, MPI_COMM_WORLD);
主元划分
各个线程通过数组psize来记录被主元划分的块大小。// 各个进程统计被主元划分的块大小
int *psize = (int*)malloc(numprocs*sizeof(int));
memset(psize, 0, numprocs*sizeof(int));
int index = 0;
for(int i = 0; i < n/numprocs; i++){
if(a[n/numprocs*myid+i] > a2[index]){
index += 1;
}
if(index == numprocs - 1){
psize[numprocs - 1] = n/numprocs - i;
break;
}
psize[index]++;
}
全局交换
各进程通过MPI_Alltoall发送数据长度,数组psize1用来统计要接收的块的大小,数组a3用来接收数据,sendPos和recvPos分别表示发送和接收数据的位置,然后再通过MPI_Alltoallv发送数据。// 各进程统计要接收的块的大小
int* psize1 = (int*)malloc(numprocs*sizeof(int));
MPI_Alltoall(psize, 1, MPI_INT, psize1, 1, MPI_INT, MPI_COMM_WORLD);
int totalSize = 0;
for(int i = 0; i < numprocs; i++){
totalSize += psize1[i];
}
// 全局交换
int *a3 = (int*)malloc(totalSize*sizeof(int));
int *sendPos = (int*)malloc(numprocs*sizeof(int));
int *recvPos = (int*)malloc(numprocs*sizeof(int));
sendPos[0] = 0;
recvPos[0] = 0;
for(int i = 1; i < numprocs; i++){
sendPos[i] = sendPos[i - 1] + psize[i - 1];
recvPos[i] = recvPos[i - 1] + psize1[i - 1];
}
MPI_Barrier(MPI_COMM_WORLD);
MPI_Alltoallv(a+n/numprocs*myid, psize, sendPos, MPI_INT, a3, psize1, recvPos, MPI_INT, MPI_COMM_WORLD);
归并排序
// 归并排序
merge_sort(a3, 0, numprocs - 1, recvPos, psize1);
// 函数原型
void merge(int a[], int p, int q, int r){
int n1 = q - p + 1;
int n2 = r - q;
int *b = (int*)malloc((n1+1)*sizeof(int));
int *c = (int*)malloc((n2+1)*sizeof(int));
memcpy(b, a + p, n1*sizeof(int));
memcpy(c, a + q + 1, n2*sizeof(int));
b[n1] = INT32_MAX;
c[n2] = INT32_MAX;
int i = 0, j = 0;
for(int k = p; k <= r; k++){
if(b[i] <= c[j]){
a[k] = b[i];
i++;
}
else{
a[k] = c[j];
j++;
}
}
free(b);
free(c);
}
void merge_sort(int a[], int p, int r, int pos[], int size[]){
if(p < r){
int q = (p + r) / 2;
merge_sort(a, p, q, pos, size);
merge_sort(a, q+1, r, pos, size);
merge(a, pos[p], pos[q] + size[q] - 1, pos[r] + size[r] - 1);
}
}
统一结果
最后把结果统一存放在数组a中。// 各进程把排序后的数组发送给根进程
int *listSize = (int*)malloc(numprocs*sizeof(int));
MPI_Gather(&totalSize, 1, MPI_INT, listSize, 1, MPI_INT, 0, MPI_COMM_WORLD);
if(myid == 0){
recvPos[0] = 0;
for(int i = 1; i < numprocs; i++){
recvPos[i] = recvPos[i - 1] + listSize[i - 1];
}
}
MPI_Gatherv(a3, totalSize, MPI_INT, a, listSize, recvPos, MPI_INT, 0, MPI_COMM_WORLD);
结果统计
运行时间(s)
| 规模/线程数 | 1 | 2 | 4 | 8 |
|---|---|---|---|---|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
加速比
| 规模/线程数 | 1 | 2 | 4 | 8 |
|---|---|---|---|---|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
分析与总结
-
当数据比较小时,进程的创建和同步等因多进程而导致的开销导致并行计算的优点无法体现出来。
-
当数据较大时,线程数超过2后,加速比逐渐降低,部分原因是多线程导致的额外开销随着线程数增加而增加,更重要的原因在于当线程数超过CPU核数时(本实验为双核)CPU占有率会达到极限,很难再有提升。















 7677
7677

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









