







pandas 读取文件
pandas读取文件常用方法有:
| 函数 | 说明 |
|---|---|
| read_csv | 读取csv文件,默认分割符号为逗号 |
| read_excel | 读取xlsx文件,默认分割符号为空格 |
| read_table | 可读取常见的各种文本文件,默认分隔符为’\t’ |
| read_clipboard | 从粘贴板上读取数据 |
| 这些命令的用法和R语言上面的风格很相似。 |
pandas读取excel表
首先,我在桌面上自己创建了一个excel表格:
路径为:C:\Users\Chipeyown\Desktop\data.xlsx
内容为:
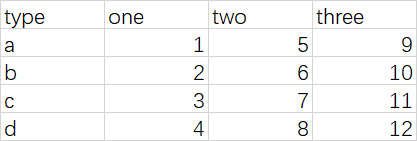
然后,通过read_excel命令读取该excel表格
import pandas as pd
df=pd.read_excel(r'C:\Users\Chipeyown\Desktop\data.xlsx')
print(df)
输出结果为:
type one two three
0 a 1 5 9
1 b 2 6 10
2 c 3 7 11
3 d 4 8 12
发现系统帮忙给建了一个index
我们也可以通过index_col这个参数,自己设定想要的index
df=pd.read_excel(r'C:\Users\Chipeyown\Desktop\data.xlsx',index_col='type')
print(df)
输出结果为:
one two three
type
a 1 5 9
b 2 6 10
c 3 7 11
d 4 8 12
“type”字符可以忽略,它对dataframe没有任何影响
读取文件时常用的各种参数:
| 参数 | 解释 |
|---|---|
| sep=‘’ | 设定分隔符 |
| header= | header=0,即以第一行为表头,header=None,即没有表头 |
| names=[‘one1’,‘one2’,‘one3’] | 重新设定columns的label,结合header=None使用 |
| skiprows = 2 | 跳过文件的前两行,读取后面剩余的行 |
| skiprows=[1,2] | 跳过行号为1,2的两行,即a,b两行 |
| skip_footer=2 | 跳过文件的最后两行,读取后面剩余的行 |
| nrows= 3 | 只读前3行 |
| index_col= [‘type’] | 设定type这一列为index |
| usecols=[‘one’,‘two’] | 只使用‘one’,'two’这两列 |
| na_values= ‘NULL’ | 将数据中的noll值识别为空值 |
| sheet_name= ‘sheet1’ | 读取excel表格中的指定sheet |
| dtype= {‘column1’:str,‘column2’:float} | 指定某列的数据类型 |
pandas写入excel表
写入是通过to_excel命令来完成的
df.to_excel(r'C:\Users\Chipeyown\Desktop\data1.xlsx')
然后就可以在桌面上找到保存下来的excel表格。该表格不需要提前建立。
内容为:
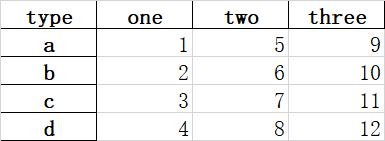
各种参数也和读取时的类似
若要将多个dataframe保存至一个excel的不同sheet,可参照一下脚本:
writer=pd.ExcelWriter('Results.xlsx')
df1.to_excel(writer,sheet_name='sheet1',index=None)
df2.to_excel(writer,sheet_name='sheet2',index=None)
writer.save()

















 8万+
8万+

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









