







论文原文:https://arxiv.org/abs/2211.11436
针对问题:
原始的基于Swin-Transformer的超分辨率网络主要会面临一下两方面问题:
- 原始网络其感受野较小。(它使得网络不受到相邻窗口的影响,从而产生失真的图像)
- 原始网络具有较大的计算量。
问题说明:
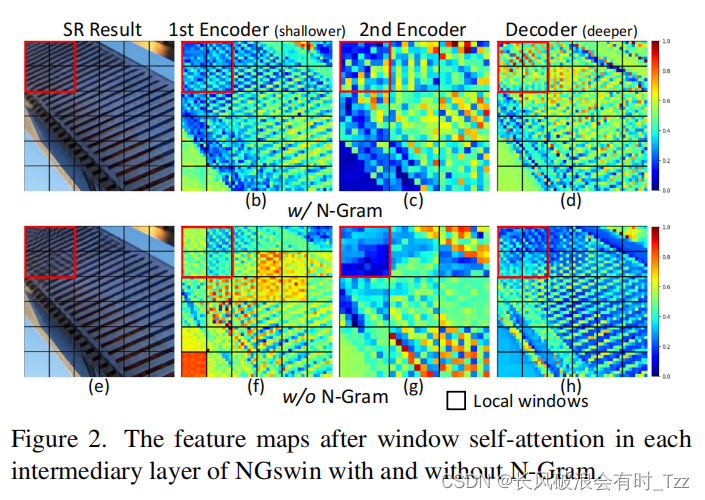
问题A:如图二的h所示,红色方框的特征与邻居特征具有较为明显的不同,从而导致(e)红色方框中出现了失真现象。
问题B:如图(f、g),红色方框与邻居方框色彩有着较为明显的不同,说明网络在推理时没有利用到邻居特征。
N-Gram的定义
N-Gram的概念已经出现在语言模型中,其主要就是将目标词语的前后词语当作辅助信息输入即可。而图像中的N-Gram概念与其类似。

网络的整体架构
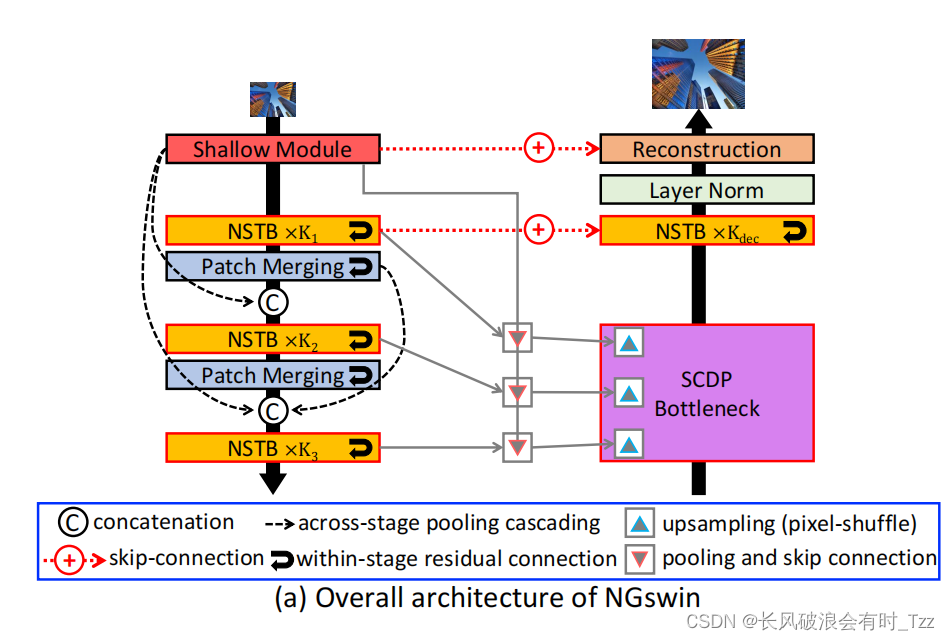
文章的重点主要为NSTB(架构如下)
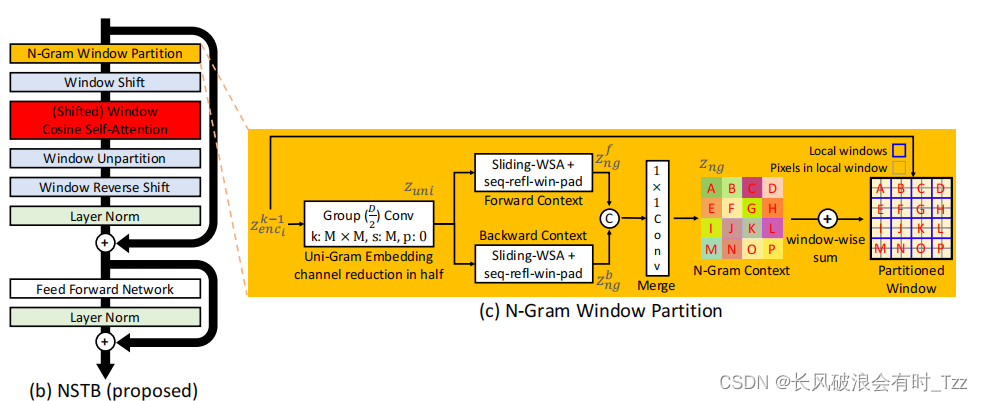
N-Gram Window Partition主要由一下几步构成
- 对图像中的块分别进行特征提取,得到特征块(uni-Gram形式)。
- 对得到的多个特征快分别计算其WSA即得到了Forward-Gram以及Backward-Gram,其中特征的边缘可能出现前后没有特征值的问题。本文避免利用填充0的方案,对于Forward-Gram填充右下角的特征,填充值为填充边缘左边一格特征或者上面一格的特征值。对于Backward-Gram则填充左上角特征,同样填充值为右边一格或者下面一格的特征值。
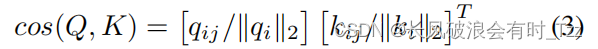
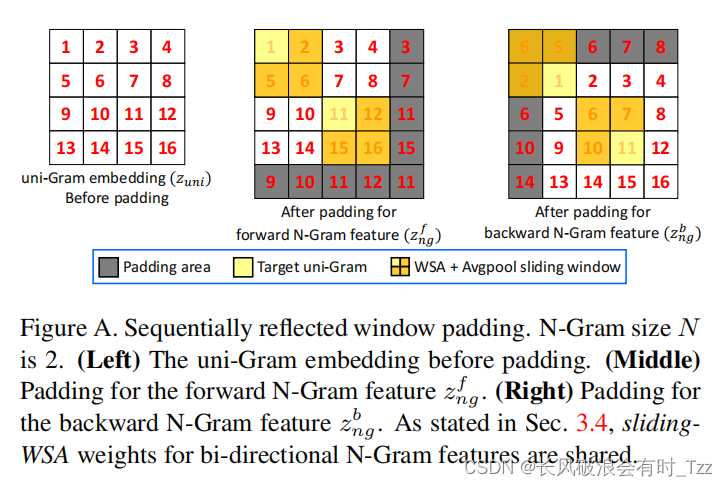
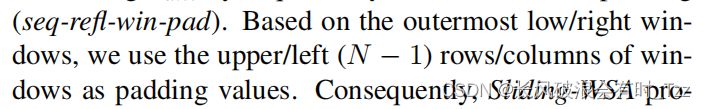
3. 利用一个卷积网络将Forward-Gram与Backward-Gram进行融合。
4. 将融合后的Gram作为偏置项添加到原始输入的特征中。
实验
引入N-Gram的消融实验
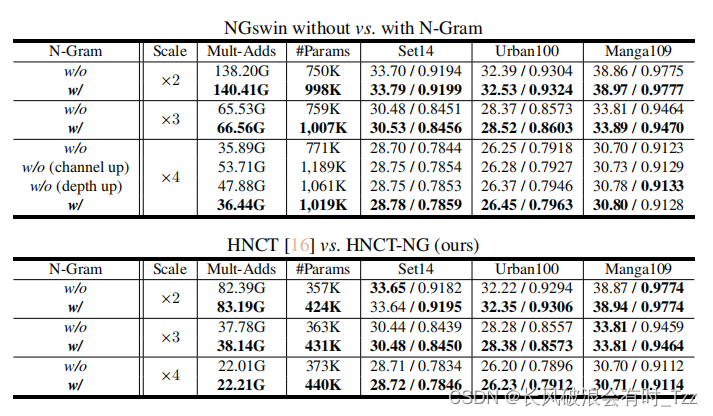
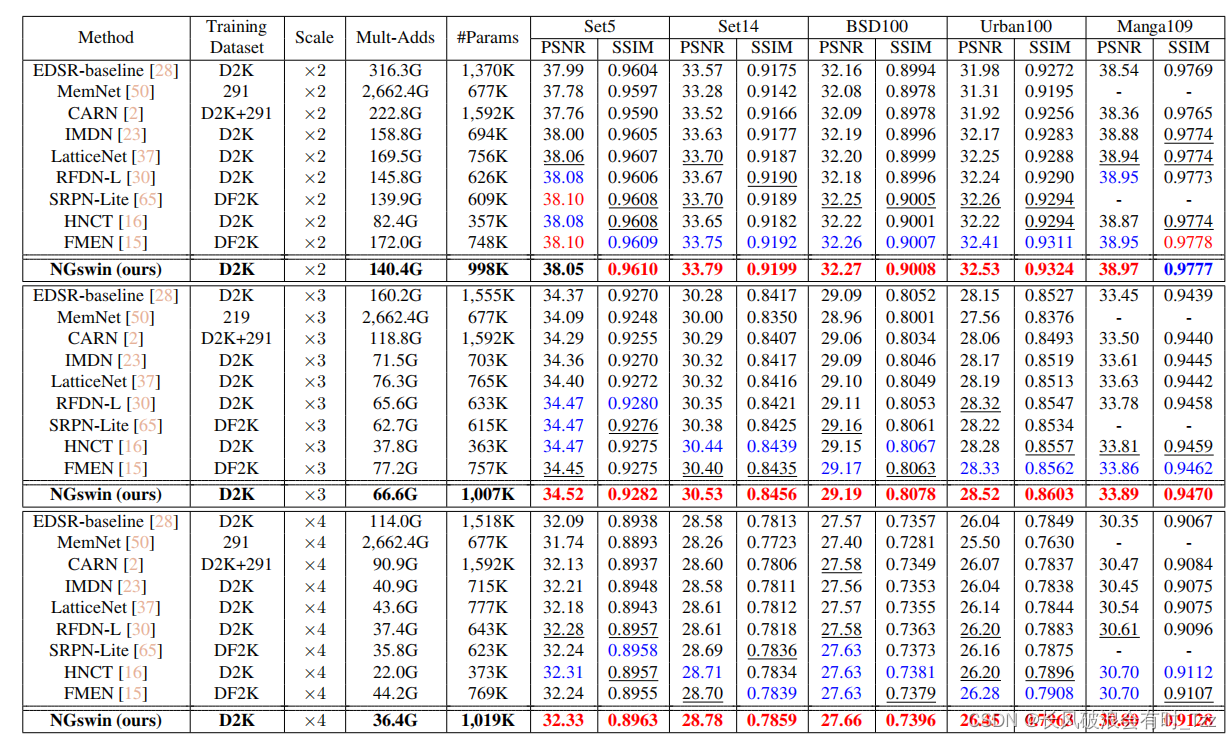
与其他网络的对比实验















 2249
2249











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









