







针对问题:
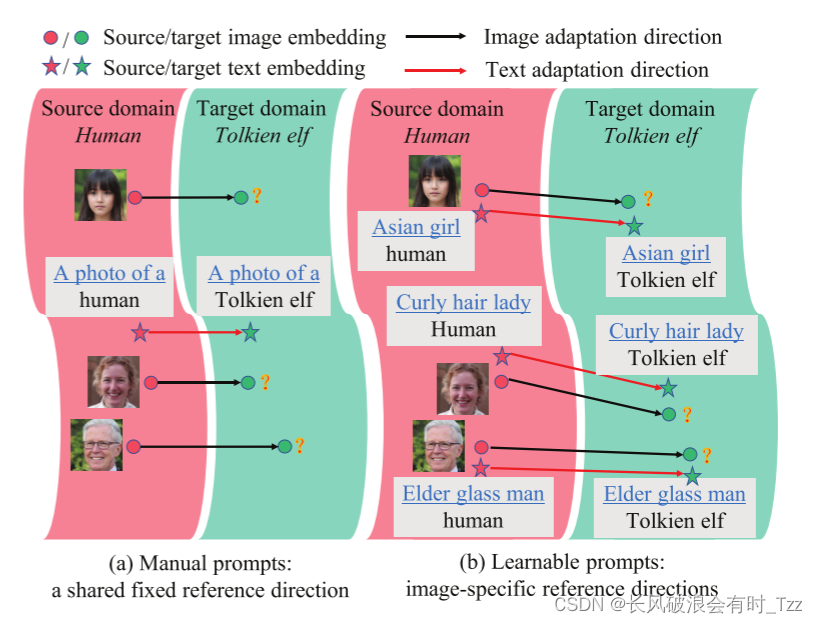
现有的基于CLIP引导的图像生成方法容易出现模型崩塌。论文将其归因于固定了跨域方向(即Prompt)对于所有的跨域图像对。
解决方法:
作者认为,以往的方法,正是因为采用了相同的Prompt,所以其降低了网络的多样性,应此容易出现模式崩塌。
本论文提出针对每张图像设置自适应Prompt,即每张图像具有各自独有的Prompt。
本文是个根据StyleGAN-NADA进行改进,以往的方法通过人为设置Prompt,其对于多张图像存在相同的Prompt,而所提出的方法,可针对不同图像设置了不同的Prompt。
方法:
本文的整体框架图如下图所示,其主要分为两个阶段。
第一阶段,训练输入的隐向量到Prompt的投影网络F
第二阶段,利用训练好的投影网络实现对目标域生成网络的训练。
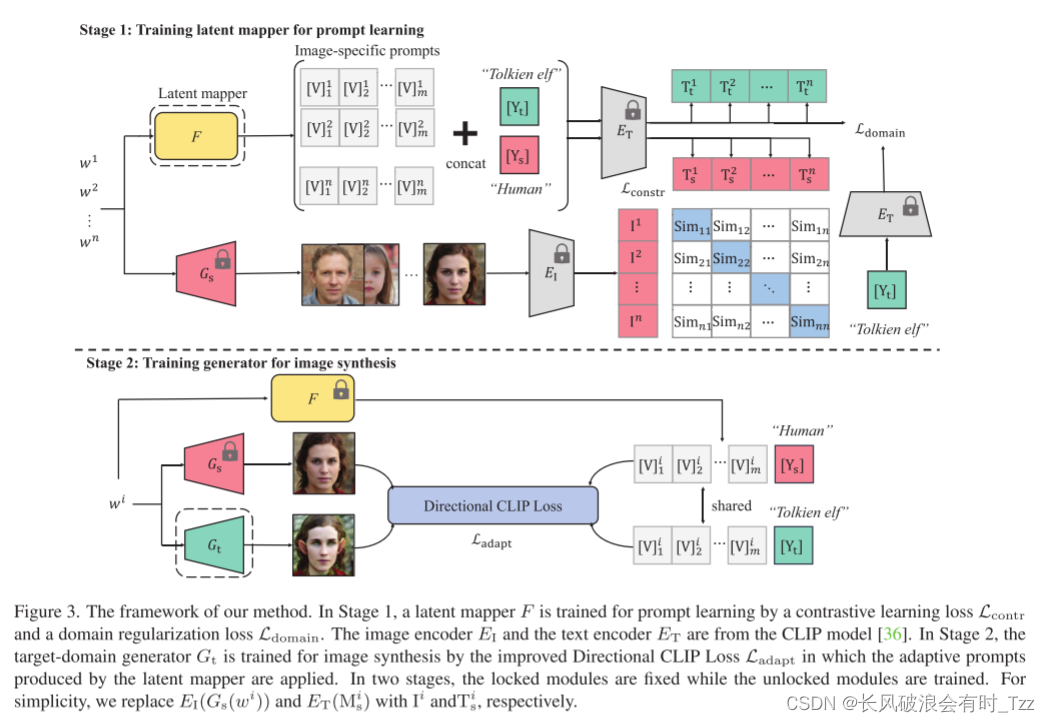
第一阶段:对投影网络F的训练
上面分支,第i个潜向量W_i首先利用F网络生成Prompt向量{V_1,V_2,V_3,…,Vm},然后在结合一个域标签Y_s生成最终的Prompt M_i
下面分支,G_s即是Clip网络,其利用W_i向量生成对应的图片I^i。(这一部分可以参考StyleGAN-NADA)
训练过程:网络采用对比学习的思想,即一个Batch中存在多张图片,即第i章图片通过上面分支,输出M_i向量,经过下面分支生成I^i,可以将两者当作是一对正样本,然后将其他的图像-向量对当作是负样本,训练,这是要求正样本余弦相似度越大,负样本余弦相似度越小,损失函数如下:
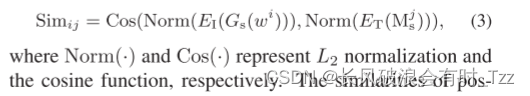

但是论文中提到一个问题(我也不是特别理解,欢迎在评论区一同讨论)(该问题已经解决,就好比“人”域而言,”腿部长短“属性是合适的,但是对于”蛇“域而言,”腿部长短“属性这是不合适的,因为蛇根本就不会出现腿,应此便会出现冲突)
对于缺乏先验知识的目标域而言,其可以贡献原域与目标域学习到的Prompt,但是这样会导致一个问题,即有些在原始域中适合的属性,但是在目标域中不那么适合,即对于“Human”域 “round ear”属性是合适的,但是对于“Tolkien elf”是较为不合适的。因此,本文引入了一个正则化项,其可以使得Prompt与目标域标签Y_t角度尽量减少,从而避免其冲突。
正则化项如下所示,整体损失如6所示

第二阶段,目标域生成器的训练
目标域生成器的训练与前面提到的StyleGAN-NADA类似,除了将原始手动设置的Prompt替换为自动生成的Prompt。具体内容可以参考StyleGAN-NADA,等两天也会出论文阅读记录。
该损失函数的具体思想,通俗的讲,就是使得方法,域迁移在文字与图像上迁移方向保持一致。


实验
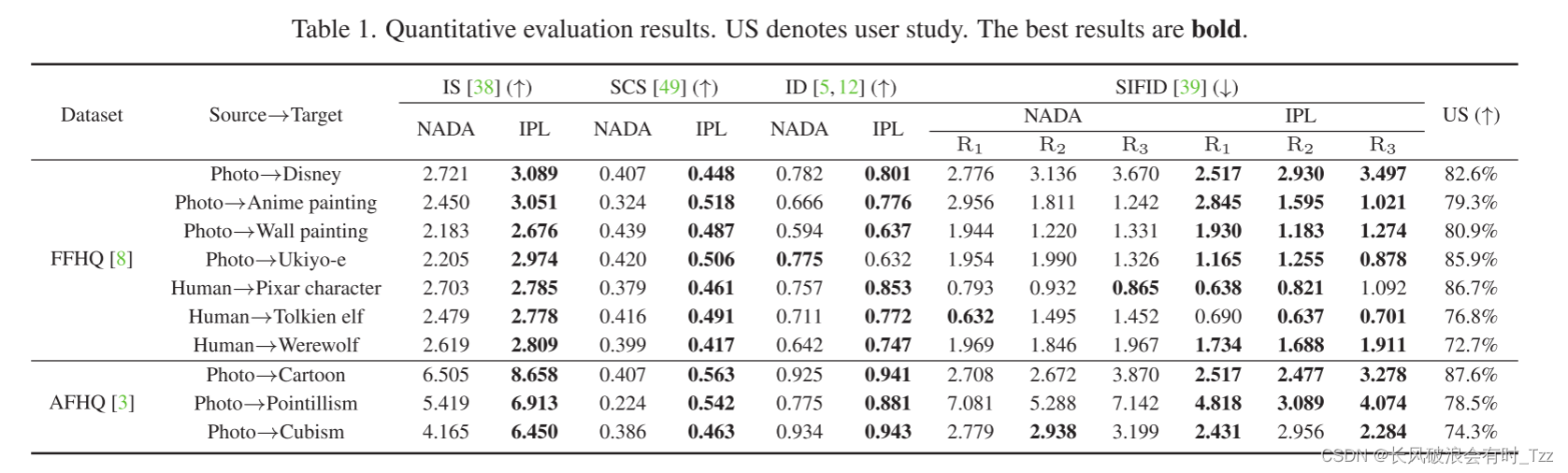
与其他方法的性能对比














 7748
7748











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









