







简介
K最近邻(k-Nearest Neighbor,KNN)分类算法,是一个理论上比较成熟的方法,也是最简单的机器学习算法之一。该方法的思路是:如果一个样本在特征空间中的k个最相似(即特征空间中最邻近)的样本中的大多数属于某一个类别,则该样本也属于这个类别。
如下图所示,有两类不同的样本数据,分别用蓝色的小正方形和红色的小三角形表示,而图正中间的那个绿色的圆所标示的数据则是待分类的数据。也就是说,现在, 我们不知道中间那个绿色的数据是从属于哪一类(蓝色小正方形or红色小三角形),下面,我们就要解决这个问题:给这个绿色的圆分类。
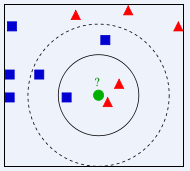
我们常说,物以类聚,人以群分,判别一个人是一个什么样品质特征的人,常常可以从他/她身边的朋友入手,所谓观其友,而识其人。我们不是要判别上图中那个绿色的圆是属于哪一类数据么,好说,从它的邻居下手。但一次性看多少个邻居呢?从上图中,你还能看到:
- 如果K=3,绿色圆点的最近的3个邻居是2个红色小三角形和1个蓝色小正方形,少数从属于多数,基于统计的方法,判定绿色的这个待分类点属于红色的三角形一类。
- 如果K=5,绿色圆点的最近的5个邻居是2个红色三角形和3个蓝色的正方形,还是少数从属于多数,基于统计的方法,判定绿色的这个待分类点属于蓝色的正方形一类。
于此我们看到,当无法判定当前待分类点是从属于已知分类中的哪一类时,我们可以依据统计学的理论看它所处的位置特征,衡量它周围邻居的权重,而把它归为(或分配)到权重更大的那一类。这就是K近邻算法的核心思想。
K 值的选择会对算法的结果产生重大影响。K值较小意味着只有与输入实例较近的训练实例才会对预测结果起作用,但容易发生过拟合;如果 K 值较大,优点是可以减少学习的估计误差,但缺点是学习的近似误差增大,这时与输入实例较远的训练实例也会对预测起作用,使预测发生错误。在实际应用中,K 值一般选择一个较小的数值,通常采用交叉验证的方法来选择最优的 K 值。
问题引出
本文将利用K最近邻算法对经典的鸢尾花(Iris)数据集进行分类,该数据已经集成在Scikit-learn的数据集中,下面我们先看一下数据吧:
from sklearn import datasets
iris = datasets.load_iris()
print(iris.data.shape) #OUTPUT:(150, 4)
#查看数据的描述是一个好习惯
print(iris.DESCR)

代码示例
from sklearn import datasets
from sklearn.model_selection import train_test_split
from sklearn.preprocessing import StandardScaler
from sklearn.neighbors import KNeighborsClassifier
from sklearn.metrics import classification_report
#读取数据并查看数据情况
iris = datasets.load_iris()
print(iris.data.shape) #OUTPUT:(150, 4)
print(iris.DESCR) #查看数据的描述是一个好习惯
#分割数据为训练集和测试集,随机种子不同,预测结果也略微不同
X_train, X_test, y_train, y_test = train_test_split(iris.data, iris.target,
test_size=0.25, random_state=3)
#将数据标准化
ss = StandardScaler()
X_train = ss.fit_transform(X_train)
X_test = ss.fit_transform(X_test)
#初始化K近邻分类器后进行学习和预测
knn = KNeighborsClassifier()
knn.fit(X_train, y_train)
y_predict = knn.predict(X_test)
#输出预测结果
print('The Accuracy of KNN is:', knn.score(X_test, y_test))
print(classification_report(y_test, y_predict, target_names=iris.target_names))

小结
从结果可以看出,K近邻分类器测试准确性为94.73%,在运算过程中,由于样本数量太少,取不同的随机数种子时,预测准确率差别很大,有的甚至到70%多。
- K近邻算法与其他模型最大的不同在于:该模型没有参数训练过程。也就是说,我们并没有通过任何学习算法分析训练数据,而只是根据测试样本在训练数据的分布直接作出分类决策。因此,K近邻属于无参数模型中非常简单的一种。
- 正是由于这样的决策算法,导致了其非常高的计算复杂度和内存消耗。因为该模型每处理一个测试样本,都需要计算其与所有训练样本的距离,然后选择最相似的K个,从而做出分类决策。
- 距离度量一般采用 Lp 距离,当p=2时,即为欧氏距离,在度量之前,应该将每个属性的值规范化,这样有助于防止具有较大初始值域的属性比具有较小初始值域的属性的权重过大。
- KNN算法不仅可以用于分类,还可以用于回归。通过找出一个样本的k个最近邻居,将这些邻居的属性的平均值赋给该样本,就可以得到该样本的属性。更有用的方法是将不同距离的邻居对该样本产生的影响给予不同的权值(weight),如权值与距离成反比。















 1807
1807











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









