







数据准备
数据来源:kaggle链接
官方提供的数据集,来源自链家网站2011-2017年的交易信息
数据清洗
#首先将数据导入,因为格式的问题,此处选择encoding = 'iso-8859-1'
train = pd.read_csv('beijing_house_train.csv', encoding = 'iso-8859-1')#训练集
test = pd.read_csv('beijing_house_test.csv', encoding = 'iso-8859-1')#测试集
#观察数据
train.head(5)
print('The data size is : {} '.format(train.shape))

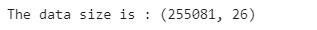
从数据中可以看到25k+条的数据集中,每条包括26个特征值,大致归类如下
url 网址
id 交易编号
Lng 经度
Lat 纬度
Cid 小区编号
tradeTime 成交时间
DOM 上架时间-从委托出售到成交的时间
followers 关注度
totalPrice 成交总价
price 成交单价
square 面积
livingRoom 卧室数量
drawingRoom 客厅数量
kitchen 厨房数量
bathRoom 卫生间数
floor 所在楼层
buildingType 建筑类型,包括塔楼,平房,板塔结合,板楼 constructionTime 建造时间
renovationCondition 装修情况,包括其他,毛坯,简装,精装
buildingStructure 建筑结构类型,包括不确定,混合,砖木,砖混,钢
ladderRatio 户梯比例,电梯数量除以住户数量
elevator 有无电梯
fiveYearsProperty 是否满五年
subway 是否地铁沿线
district 所在行政区
communityAverage 本小区均价
train.dtypes
#观察特征值类型,tradeTime应当是int
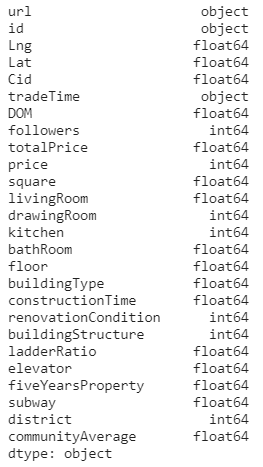
train.isnull().sum().sort_values(ascending=False)
#统计缺省值
有DOM、constructionTime、buildingType、communityAverage、elevator、fiveYearsProperty、floor、livingRoom、subway、bathRoom存在缺失情况
#大量缺失的DOM用均值填充
train['DOM'].fillna(train['DOM'].dropna().mean(0), inplace=True)
test['DOM'].fillna(test['DOM'].dropna().mean(0), inplace=True)
#test数据集也需进行相关处理
#tradeTime是2000/01/01格式的,先转化成datatime即2000-01-01格式,再分别提出数字的三个部分构成年月日
train['tradeyear'] = train['tradeTime'].astype('datetime64[ns]').astype(str).str[0:4].astype('int64')
train['trademon'] = train['tradeTime'].astype('datetime64[ns]').astype(str).str[5:7].astype('int64')
train['tradeday'] = train['tradeTime'].astype('datetime64[ns]').astype(str).str[8:].astype('int64')
train = train.drop('tradeTime', axis = 1)#最后将已处理的tradeTime去除
train['constructionTime'] = train['constructionTime'].fillna(train['tradeyear'] - train['DOM']/365)
train['constructionTime'] = train['constructionTime'].astype('int64')
#用售出的年份减去上架的时间当做建造时间
train['bathRoom'] = train['bathRoom'].fillna(0)
train['subway'] = train['subway'].fillna(0)
train['fiveYearsProperty'] = train['fiveYearsProperty'].fillna(0)
train['elevator'] = train['elevator'].fillna(0)
train['livingRoom'] = train['livingRoom'].fillna(0)
#房间等特征值的缺失就当做没有,用0填充
train['buildingType'] = train['buildingType'].fillna(train['buildingType'].mode().iloc[0])
train['communityAverage'] = train['communityAverage'].fillna(train['communityAverage'].median())
train['floor'] = train['floor'].fillna(train['floor'].median())
#buildingType用众数填充,floor和communityAverage用中间值填充
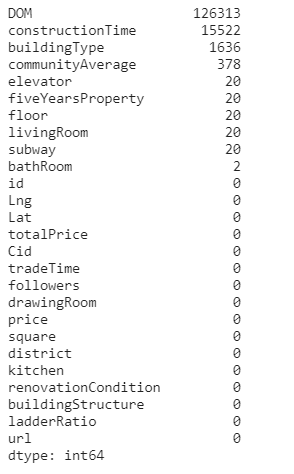
train.isnull().sum().sort_values(ascending=False)
#查看缺省值填充后的情况,已经没有空缺了
可视化
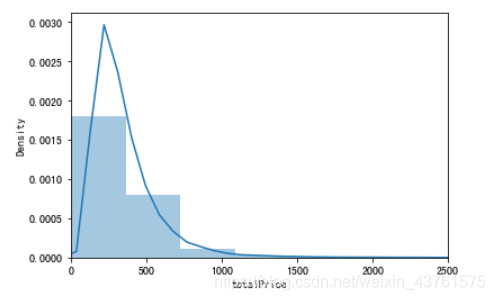
plt.xlim([-0.5, 2500])
sns.distplot(train['totalPrice'])
#观察总价,一套房子普遍在500w以下
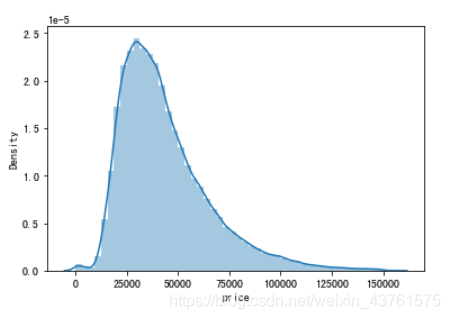
sns.distplot(train['price'])
#观察每平米单价分布,从0-15w都有分布,主要集中在2w-7w左右
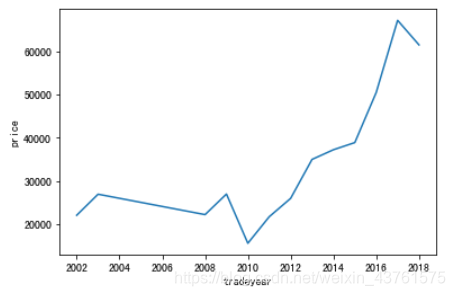
price_by_year = train.groupby('tradeyear').price.mean()
sns.lineplot(data = price_by_year)
#根据年份列出房价均值,10年前房价处于平稳阶段,经过10年的下跌后就一直处于飞速增长的趋势
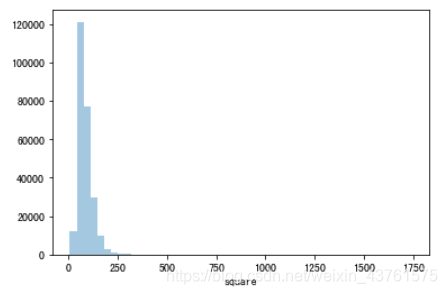
sns.distplot(a = train['square'],kde=False)
#观察所有房子面积分布情况,主要集中在50-200平之间,符合正常房型的面积
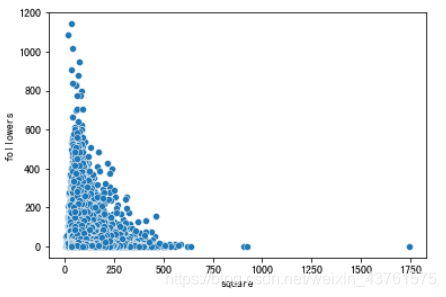
sns.scatterplot(x = train['square'], y = train['followers'])
#观察followers侧重多大的房子,绝大多数都是在关注250平以下的房子,在100平以下出现了极高值,这说明对于绝大多数人还是只能承受一套较小的房子
plt.figure(figsize=(5,5))
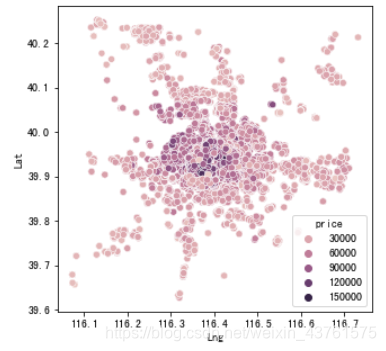
sns.scatterplot(x = train['Lng'], y = train['Lat'], hue = train['price'])
#绘制房价分布的地理图,市中心房价极高,从天安门向外递减飞快
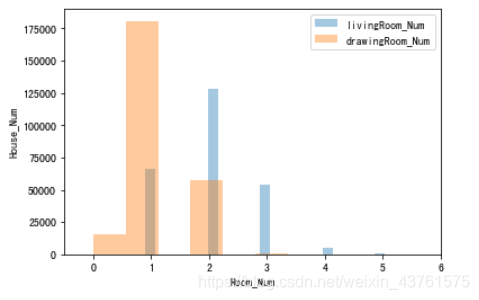
sns.distplot(a = train['livingRoom'], kde=False, label='livingRoom_Num')
sns.distplot(a = train['drawingRoom'], kde=False, label='drawingRoom_Num')
plt.xlim(-0.5, 6)
plt.xlabel('Room_Num')
plt.ylabel('House_Num')
plt.legend()
#观察房子的客厅卧室数量情况,大致还是以两室一厅为主,存在多卧的情况,但是不会有多客厅
f,ax = plt.subplots(figsize=(25, 25))
sns.heatmap(train.corr(), annot = True, linewidth = .5, fmt = ".3f",ax = ax)
plt.show()
#绘制所有特征值的相关性图,挑选与总价关系较大的因素
train = train.drop(['url', 'id', 'Cid', 'Lng', 'Lat', 'kitchen', 'bathRoom',
'buildingType', 'constructionTime', 'ladderRatio',
'fiveYearsProperty', 'district', 'trademon', 'tradeday'], axis=1)
#去除无关因素,剩余followers、renovationCondition 、subway 、communityAverage、tradeyear
构建模型并预测
#将准备好的train数据4:1划分成训练集和测试集
X = train.drop(['totalPrice'], axis = 1)
y = train['totalPrice']
from sklearn.model_selection import train_test_split
X_train, X_test, y_train, y_test = train_test_split(X, y, test_size=0.2, random_state=7)
from sklearn.linear_model import LinearRegression
lin_reg = LinearRegression(normalize=True)
lin_reg.fit(X_train,y_train)
pred = lin_reg.predict(X_test)
results = append_results("Linear Regression", LinearRegression(), results, y_test, pred)
results#在划分的训练集上进行拟合并测试

pre_results = pd.DataFrame()
model = LinearRegression(normalize=True)
model.fit(X, y)
pred = model.predict(test)
pre_results = pre_append_results("Linear Regression", LinearRegression(), pre_results, pre_y, pred)
pre_results#通过训练train对test进行预测,test的真实价格可以通过单价*面积得到

本文展示代码只用了线性回归,使用时可以选择多种方式进行预测,通过对比不同方式的效果选择最合适的model,最终房价预测误差在6k+左右


















 2516
2516

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











