







基于人脸的常见表情识别
数据获取
数据由项目提供的一个爬虫工具获取
下载后运行python image_downloader_gui.py,选择搜索引擎、关键词和数量就可以自动获取保存搜索出来的图片,如下我们搜索嘟嘴的图片

保存到文件如下所示

数据处理
我们获取的数据可以看到有许多都是不能用的,最基础的就是要确保图片属于人脸,这里我们用到了OpenCV自带的人脸的Haar特征分类器
下面我们加载这个分类器
cascade_path = './Emotion_Recognition_File/face_detect_model/haarcascade_frontalface_default.xml'
cascade = cv2.CascadeClassifier(cascade_path)
使用分类器识别三张测试图片
img_path = './Emotion_Recognition_File/face_det_img/'
for image in os.listdir(img_path):
img = cv2.imread(os.path.join(img_path, image), 1)
face_num = cascade.detectMultiScale(img, 1.3, 5)
print("检测到", len(face_num), "张人脸")
#if len(face_num) == 0:
# cv2.namedWindow('Result', 0)
# cv2.imshow('Result', img)
# print("未检测到人脸")
plt.imshow(img[:, :, ::-1])
plt.show()
可以看到分类器能够检测出人脸的数量

有了这个分类器,我们就可以检测到爬取图片是否属于人脸,接下来就可以进一步确定我们需要的第二个条件,嘴巴
我们利⽤ Opencv+Dlib 算法提取嘴唇区域, Dlib 算法会得到⾯部的 68 个关键点,我们从中得到嘴唇区域,并适当扩⼤。
人脸 68 点位置图如下:

根据这个信息,我们可以调用 cascade.detectMultiScale 人脸检测器和 Dlib 的关键点检测算法 predictor 获得关键点结果landmarks
rects = cascade.detectMultiScale(img, 1.3, 5)
x, y, w, h = rects[0]
rect = dlib.rectangle(int(x), int(y), int(x + w), int(y + h))
np.matrix([[p.x, p.y] for p in predictor(im, rect).parts()])
然后通过landmarks对每张图片进行嘴巴部分的锁定,根据最外围的关键点获取包围嘴唇的最小矩形框,其中嘴巴关键点为:嘴巴外轮廓(48-59)嘴巴内轮廓(60-67)
for i in range(48, 67):
x = landmarks[i, 0]
y = landmarks[i, 1]
if x < xmin:
xmin = x
if x > xmax:
xmax = x
if y < ymin:
ymin = y
if y > ymax:
ymax = y
roiwidth = xmax - xmin
roiheight = ymax - ymin
roi = im[ymin:ymax, xmin:xmax, 0:3]
if roiwidth > roiheight:
dstlen = 1.5 * roiwidth
else:
dstlen = 1.5 * roiheight
diff_xlen = dstlen - roiwidth
diff_ylen = dstlen - roiheight
newx = xmin
newy = ymin
imagerows, imagecols, channel = im.shape
if newx >= diff_xlen / 2 and newx + roiwidth + diff_xlen / 2 < imagecols:
newx = newx - diff_xlen / 2
elif newx < diff_xlen / 2:
newx = 0
else:
newx = imagecols - dstlen
if newy >= diff_ylen / 2 and newy + roiheight + diff_ylen / 2 < imagerows:
newy = newy - diff_ylen / 2
elif newy < diff_ylen / 2:
newy = 0
else:
newy = imagerows - dstlen
roi = im[int(newy):int(newy + dstlen), int(newx):int(newx + dstlen), 0:3]
这样我们就获取到矩形框起来的嘴部图片,(xmin,ymin) (xmax,ymax) 分别代表嘴唇区域在原始图像的位置,即左上角坐标和右下角坐标

获取到嘴部图片后,我们分类保存到四个文件夹,9:1划分训练集和验证集。数据准备就完成了

train+pre
模型这里我们使用torch先建立一个三层卷积神经网络
class simpleconv3(nn.Module):
def __init__(self):
super(simpleconv3,self).__init__()
self.conv1 = nn.Conv2d(3, 12, 3, 2)
self.bn1 = nn.BatchNorm2d(12)
self.conv2 = nn.Conv2d(12, 24, 3, 2)
self.bn2 = nn.BatchNorm2d(24)
self.conv3 = nn.Conv2d(24, 48, 3, 2)
self.bn3 = nn.BatchNorm2d(48)
self.fc1 = nn.Linear(48 * 5 * 5 , 1200)
self.fc2 = nn.Linear(1200 , 128)
self.fc3 = nn.Linear(128 , 4)
def forward(self , x):
x = F.relu(self.bn1(self.conv1(x)))
#print "bn1 shape",x.shape
x = F.relu(self.bn2(self.conv2(x)))
x = F.relu(self.bn3(self.conv3(x)))
x = x.view(-1 , 48 * 5 * 5)
x = F.relu(self.fc1(x))
x = F.relu(self.fc2(x))
x = self.fc3(x)
return x
我们对图片进行随机裁剪,转化成tensor
data_transforms = {
'train': transforms.Compose([
transforms.RandomSizedCrop(48),
transforms.RandomHorizontalFlip(),
transforms.ToTensor(),
transforms.Normalize([0.5,0.5,0.5], [0.5,0.5,0.5])
]),
'val': transforms.Compose([
transforms.Scale(64),
transforms.CenterCrop(48),
transforms.ToTensor(),
transforms.Normalize([0.5,0.5,0.5], [0.5,0.5,0.5])
]),
}
接下来就是数据投入和训练了
data_dir = './Emotion_Recognition_File/train_val_data/' # 数据集所在的位置
image_datasets = {x: datasets.ImageFolder(os.path.join(data_dir, x),
data_transforms[x]) for x in ['train', 'val']}
dataloders = {x: torch.utils.data.DataLoader(image_datasets[x],
batch_size=64,
shuffle=True if x=="train" else False,
num_workers=0) for x in ['train', 'val']}
我们设置一下loss和acc的计算方法
for data in dataloders[phase]:
inputs, labels = data
if use_gpu:
inputs = Variable(inputs.cuda())
labels = Variable(labels.cuda())
else:
inputs, labels = Variable(inputs), Variable(labels)
optimizer.zero_grad()
outputs = model(inputs)
_, preds = torch.max(outputs.data, 1)
loss = criterion(outputs, labels)
if phase == 'train':
loss.backward()
optimizer.step()
running_loss += loss.data.item()
running_corrects += torch.sum(preds == labels).item()
epoch_loss = running_loss / dataset_sizes[phase]
epoch_acc = running_corrects / dataset_sizes[phase]
调成训练模式,设置10个epoch
modelclc = train_model(model=modelclc,
criterion=criterion,
optimizer=optimizer_ft,
scheduler=exp_lr_scheduler,
num_epochs=10)
GPU上很快就跑完了,应该是模型简单,分类起来也没那么复杂
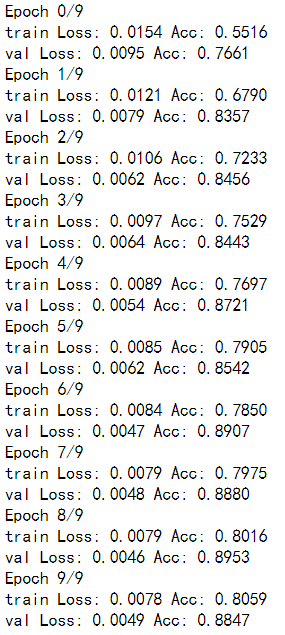
下面对模型进行测试,对测试的图片进行同样的获取嘴部数据,输入到net中得到predict
roi = im[int(newy):int(newy + dstlen), int(newx):int(newx + dstlen), 0:3]
roi = cv2.cvtColor(roi, cv2.COLOR_BGR2RGB)
roiresized = cv2.resize(roi,
(testsize, testsize)).astype(np.float32) / 255.0
imgblob = data_transforms(roiresized).unsqueeze(0)
imgblob.requires_grad = False
imgblob = Variable(imgblob)
torch.no_grad()
predict = F.softmax(net(imgblob))
index = np.argmax(predict.detach().numpy())
这里我们得到的还是tensor格式的结果

转化成arr再提取最大值的索引,便得到了number,根据number和坐标,我们圈出嘴部并在旁边标上对应的label
if index == 0:
cv2.putText(im_show, 'none', (pos_x, pos_y), font, 1.5, (0, 0, 255), 2)




可以看到我们最终预测的结果还是比较准确的
















 1404
1404











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











