







男声女声分类之svm
svc
1、支撑向量机SVM是一种非常重要和广泛的机器学习算法,它的算法出发点是尽可能找到最优的决策边界,使得模型的泛化能力尽可能地好,因此SVM对未来数据的预测也是更加准确的。
2、SVM既可以解决分类问题,又可以解决回归问题,原理整体相似,不过也稍有不同。
本次实验属于二分类问题,我们选择svm.SVC模型进行分类预测。
数据
#导入数据
train = pd.read_csv("voice_train.csv")
test = pd.read_csv("voice_test.csv")
train.head(5)
#初步观察得知,数据提供较多特征值,且都是数字化,需要进行male、female二分类
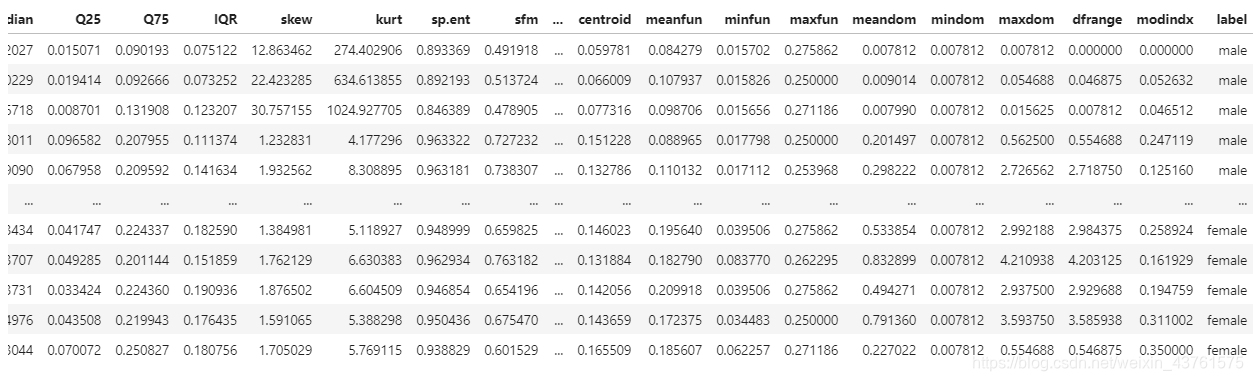
#性别数字化
train['label'] = train['label'].map( {'male': 1, 'female': 0} ).astype(int)
#1为male、0为female
#分出特征值和标签
X = train.drop("label", axis=1)
y = train['label']
#划分训练集和测试集
x_train, x_test, y_train, y_test = train_test_split(X, y, random_state=1, train_size=0.8)
#特征值归一化处理
scaler = StandardScaler()
scaler.fit(x_train)
x_train = scaler.transform(x_train)
scaler.fit(x_test)
x_test = scaler.transform(x_test)
scaler.fit(test)
test = scaler.transform(test)
模型构建预测
#构建模型,调整参数
svc = SVC(kernel='linear', C = 1)
svc.fit(x_train, y_train)
svc_pre = svc.predict(x_test)
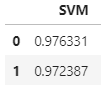
最终SVC在从train分出的训练集和测试集分别达到了0.976和0.972的分数,本文只展示了SVC的使用效果,读者可使用决策树、逻辑回归等多种模型进行实际测试对比效果
源代码:github


















 978
978

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











