







 本文介绍了一种优化翻译网站输入体验的方法,通过JavaScript代码自动去除文本输入中的换行符,适用于百度翻译、有道翻译等多款在线翻译工具。提供V1.0和V2.0两个版本的代码实现,V2.0版本更通用,直接作用于textarea元素,无需特定ID。
本文介绍了一种优化翻译网站输入体验的方法,通过JavaScript代码自动去除文本输入中的换行符,适用于百度翻译、有道翻译等多款在线翻译工具。提供V1.0和V2.0两个版本的代码实现,V2.0版本更通用,直接作用于textarea元素,无需特定ID。
V2.0
通用代码
新增:直接用 getElementsByTagName 检查 textarea 位置,该方法适用于更多网站
亲测适用:百度翻译,有道翻译,谷歌翻译,新秀翻译网站 DeepL,腾讯翻译君,必应翻译
如果你想用的翻译网站无效,可使用V1.0方法
英文输入去回车(回车替换为一个空格)
javascript: document.getElementsByTagName('textarea')[0].addEventListener('input',
function () {
var txt = "";
txt = document.getElementsByTagName('textarea')[0].value;
for (var i = 0; i < txt.length; i++) {
if (txt.indexOf("\n"))
txt = txt.replace("\n", " ");
}
document.getElementsByTagName('textarea')[0].value = txt;
}
);
中文输入去回车(删除回车)
javascript: document.getElementsByTagName('textarea')[0].addEventListener('input',
function () {
var txt = "";
txt = document.getElementsByTagName('textarea')[0].value;
for (var i = 0; i < txt.length; i++) {
if (txt.indexOf("\n"))
txt = txt.replace("\n", "");
}
document.getElementsByTagName('textarea')[0].value = txt;
}
);
使用方法
以百度翻译为例:
- 复制前面的代码
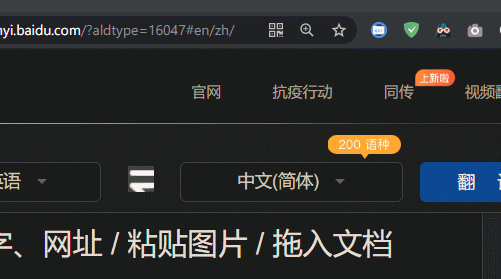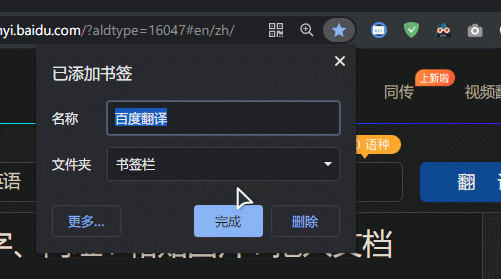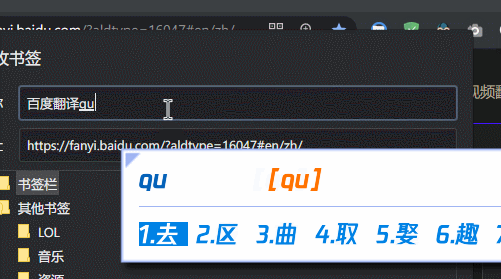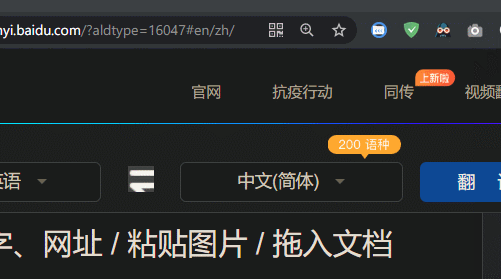
- 随便打开一个浏览器标签,收藏为书签,修改书签名字(请忽略图中的命名。由于代码通用,可命名为翻译网站去回车),把书签地址改成前面复制的代码,保存:
- 每次先打开百度翻译,再打开刚才新建的书签,再键入需要翻译的内容即可。
V1.0
经 StrongerL 的博客 谷歌翻译自动去除换行 启发,发现只要翻译网站 HTML 代码里 textarea 标签有 id,可复用此代码。
查找id
以谷歌浏览器为例,在翻译网站按下 F12,按图操作(左键单击图标 ,再单击输入框)
,再单击输入框)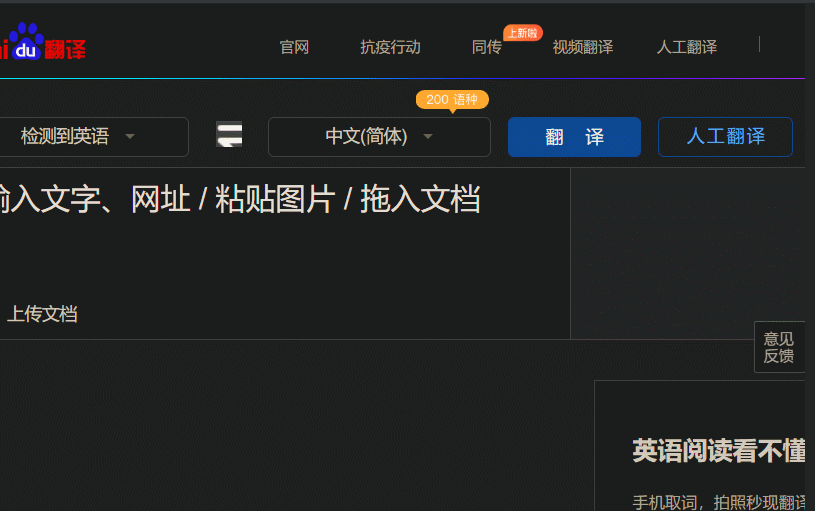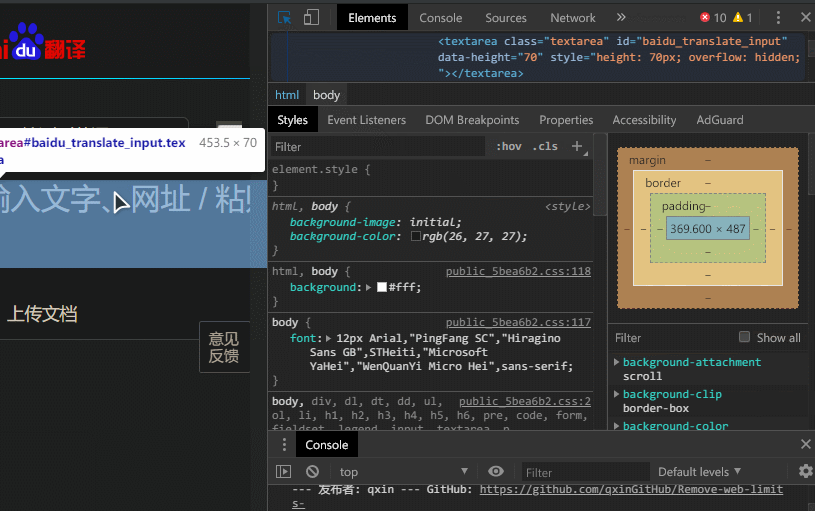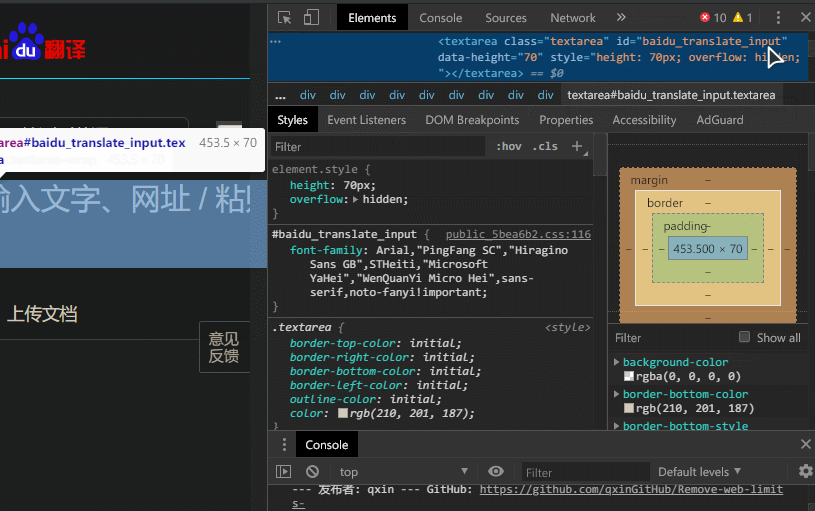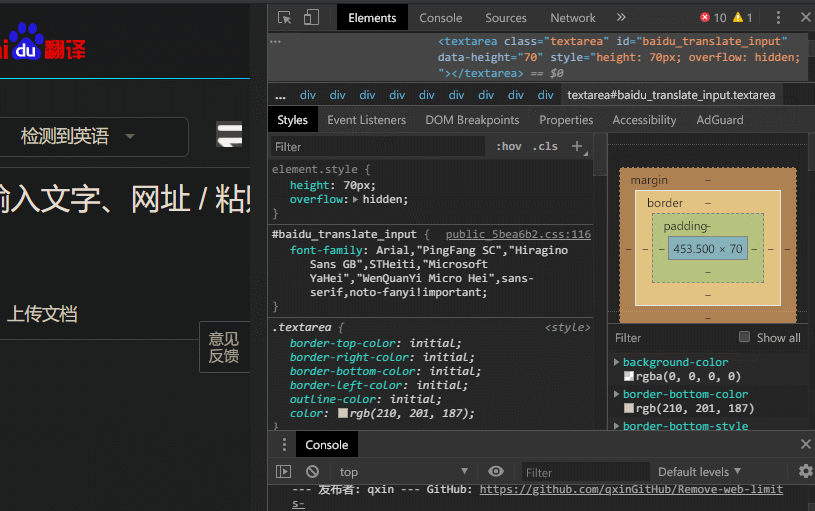
图中鼠标最后所指的即为 id(baidu_translate_input)
翻译网站代码
有道翻译代码:
javascript: document.getElementById('inputOriginal').addEventListener('input',
function () {
var txt = "";
txt = document.getElementById('inputOriginal').value;
for (var i = 0; i < txt.length; i++) {
if (txt.indexOf("\n"))
txt = txt.replace("\n", " ");
}
document.getElementById('inputOriginal').value = txt;
}
);
谷歌翻译代码:
javascript: document.getElementById('source').addEventListener('input',
function () {
var txt = "";
txt = document.getElementById('source').value;
for (var i = 0; i < txt.length; i++) {
if (txt.indexOf("\n"))
txt = txt.replace("\n", " ");
}
document.getElementById('source').value = txt;
}
);
规律已经很明显了,如果你想用的翻译网站也有 id 的话,可以自己改代码。

















 3684
3684

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









