










文章目录
- (cvpr2020 oral)Polar Mask : Single Shot Instance Segmentation with Polar Representation
- (cvpr2020 oral)AdderNet: Do We Really Need Multiplications in Deep Learning?
- (cvpr2020 oral)BBN: Bilateral-Branch Network with Cumulative Learning
- (cvpr2020)CentripetalNet: Pursuing High-quality Keypoint Pairs for Object Detection
- (cvpr2020)Attention Convolutional Binary Neural Tree for Fine-Grained Visual Categorization
- (cvpr2020)Learning in the Frequency Domain
- (cvpr2020)Single-Stage Semantic Segmentation from Image Labels
- (非CVPR) Scalable Arrow Detection in Biomedical Images
- 参考资料
前言 最近需要分享看过的论文,所以针对目标检测和图像分割两个大的题目,看cvpr2020相关的论文。
(cvpr2020 oral)Polar Mask : Single Shot Instance Segmentation with Polar Representation
论文地址
代码地址
作者本人的解读
摘要 这篇文章提出了一种anchor-box free的single-shot图像分割方法,概念上来说就是进行完全卷积,可以把这个方法嵌入到许多现有的检测方法中。
1. Architecture
下图是Polar Mask的结构图,包含:主干网络,FPN,和针对特定任务的heads. 这篇论文里使用功能的backbone和FPN是与FCOS论文中的相同。
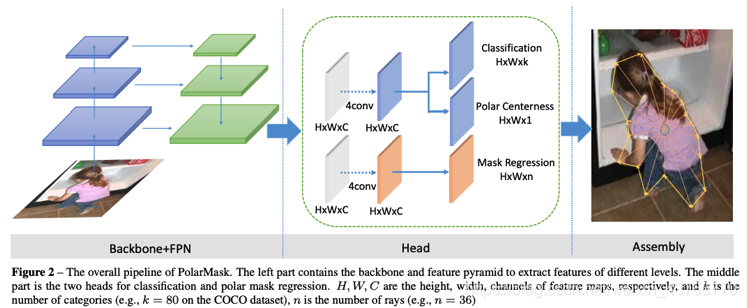
2. Polar Mask Segmentation
- Polar Representation 首先,给定一个实例的轮廓,使用极坐标进行表示,采样一个中心点 ( x c , y c ) (x_c, y_c) (xc,yc)和在轮廓上的点 ( x i , y i ) , i = 1 , 2 , . . . , N (x_i, y_i), i=1,2,...,N (xi,yi),i=1,2,...,N. 从中心点出发均匀等角度间隔的发射 n n n条线段 Δ θ ( n = 36 , Δ θ = 1 0 ∘ ) \Delta \theta (n=36, \Delta \theta=10^\circ) Δθ(n=36,Δθ=10∘),实例的轮廓就是用中心点和 n n n条线段表示出来。角度间隔是实现确定的,所以只需要预测出线段的长度,因此我们可以将图像分割的任务公式化为极坐标下的实例中心点的分类和密度距离回归。
- Mass Center 实例中心的选择有很多,比如框中心和重心,本文通过实验验证了重心更有利,重心落入实例内部的可能性更大,极端情况暂时除外。
- Distance Regression 在进行极坐标表示的过程中包含一些特殊情况,这些像素是影响
- Polar Centerness 由于文章预测出来的中心点是针对框的,但是我们在意的是预测的轮廓,所以论文中引入了Polar Centerness,给定
n
n
n条线段,论文提出了Polar Centerness,给中心点进行重新加权。在结构图中添加了与分类分支平行的一个单层分支,来预测某个位置的Polar Centerness,Polar Centerness的引入能够让网络提高精度。

- Polar IOU Loss 不需要调整权重就可以让mask分支快速且稳定的收敛。
(cvpr2020 oral)AdderNet: Do We Really Need Multiplications in Deep Learning?
论文链接
代码链接
论文解读
摘要 这篇文章在发布的时候引起热议,实现一个无乘法的神经网络的同时达到了与乘法神经网络近似的效果。现有的gpu卡无法轻松的安装在移动端设备上,因此有必要在充分利用移动端能够提供的计算资源的基础上研究深度学习网络。
- Adder Network
AdderNet网络几乎不包含乘法,将某中间层的输入定义为X,filter定义为F,输出feature为Y。函数S(…)表示了输出Y与输入的X和F之间的关系,普通的神经网络的 S ( x , y ) = x × y S(x,y)=x\times y S(x,y)=x×y。
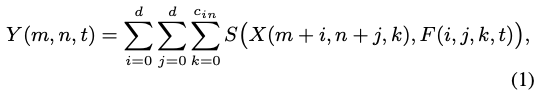
这里我们就可以更换这个度量函数表示滤波器和输入特征之间的关系。只有加法的度量函数比如L1距离,公式可以重新定义: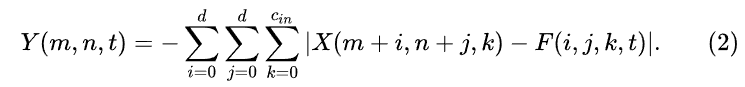
-
Optimization
传统的CNN通过反向传播计算梯度,通过梯度下降的方法优化网络参数,在Adder Net中求导计算为: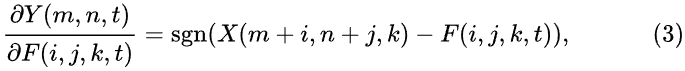
sgn是符号函数,求导结果只有+1,0,-1三个输出,不能很好的描述输入与filter之间的距离关系,所以将符号函数去掉后,但为了防止梯度爆炸,添加了一个HT函数防止梯度爆炸。
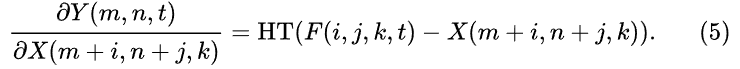
-
Adaptive Learning Rate Scaling
传统CNN中,经常使用BN来让网络的各层输出分布近似,让网络计算更加稳定。假设X和F都是均值为0的标准正态分布,CNN中的方差计算式为(6),在这个公式中如果给卷积核F的方差很小,输出Y的方差就与输入X的方差相近。
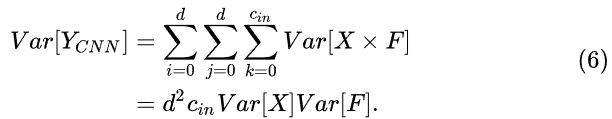
AdderNet中,输出Y的方差表达式为(7),在这个表达式中我们无法给定F一个方差,让输入与输出之间的方差分布近似,输出的量级可能会随着网络的加深爆炸。但
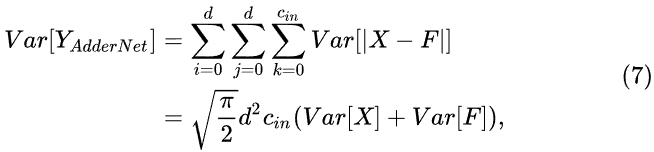
如果对AdderNet使用普通的BN进行归一化, y = γ x − μ β σ β − β y=\gamma \frac{x-\mu_\beta}{\sigma_\beta}-\beta y=γσβx−μβ−β,其中 γ 和 β \gamma和\beta γ和β是可学习的参数, μ 和 σ \mu和\sigma μ和σ是输出特征的均值和方差,反向计算梯度的时候,如公式9。AdderNet的方差很大(分母较大),所以导致梯度很小不利于网络的学习,所以提出了基于归一化的自适应学习率.
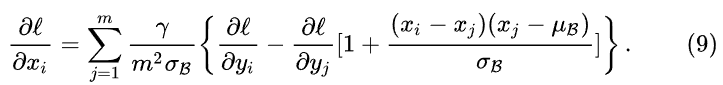
每层的梯度计算公式为 Δ F l = γ × α l × Δ L ( F l ) \Delta F_l=\gamma \times \alpha_l \times \Delta L(F_l) ΔFl=γ×αl×ΔL(Fl),其中 γ \gamma γ为整个网络的全局学习率, Δ L ( F l ) \Delta L(F_l) ΔL(Fl)表示第 l l l层的梯度, α l \alpha_l αl是第 l l l层的学习率。
AdderNet计算滤波器与输入之间差值,量值大小应近似而有利于特征提取,由于每层的特征都进行归一化,量级都一样,所以每层的滤波器量级也应该相似,将每层的学习率计算为:
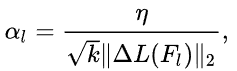
其中k表示 F l F_l Fl中的元素个数, η \eta η表示控制所有adder层的超参数。通过这个方法能相同且以更快的更新速度优化每层的滤波器。 -
分类结果
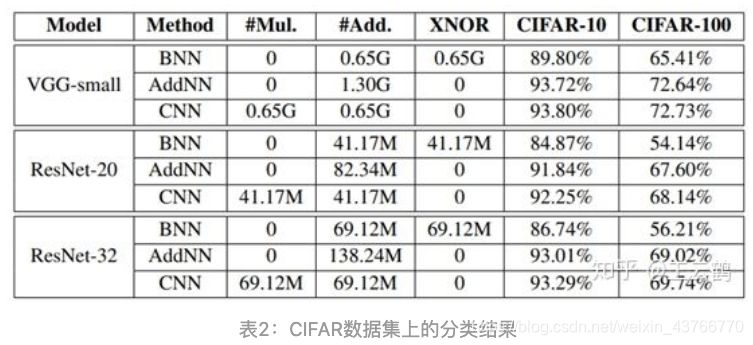
给出在CIFAR数据集上的效果对比:
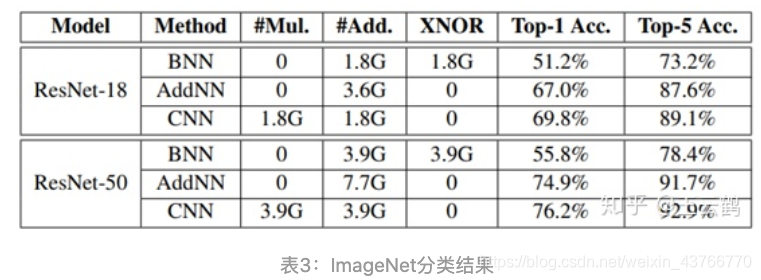
给出在ImageNet上的分类结果:
下图给出了CNN和ANN的滤波器对比图,发现两种网络的梯度计量方式虽然不同,但滤波器的纹理特征都比较明显,可以起到提取特征的作用。

(cvpr2020 oral)BBN: Bilateral-Branch Network with Cumulative Learning
论文链接
代码链接
摘要 这篇论文主要针对的问题是自然界中数据的长尾分布问题,即少数类别占据了大多数据,而大多数类别只有少量的数据,提出的BBN网络能够先学常规的信息,然后学习长尾数据的特征。这篇文章将整个分类模型分成两个阶段:特征提取阶段和分类器学习阶段。
-
How class re-balancing strategies work?
当采用类别数据均衡的测略进行训练能够让模型更加注意长尾分布数据,提高模型分类性能。对此现象作出一个猜想,这种类别均衡策略能够极大的提升分类器的性能,但可能破坏了原始数据分布损害模型的通用性。为了证明这一猜想,作者采用了一个two-stage的训练方式,首先,采用cross-entropy、re-balancing 或re-weight方法训练能够得到多个特征提取器,然后固定特征提取部分的参数,采用不同的训练方式来训练第二阶段的分类器。Cross-Entropy(CE):使用原始不均衡数据集、交叉熵损失函数进行普通训练;Re-Sampling (RS): 在原始数据基础上进行采样,均衡后进行模型的训练;Re-Weighting(RW):按照样本数量多少的倒数对样本进行加权。
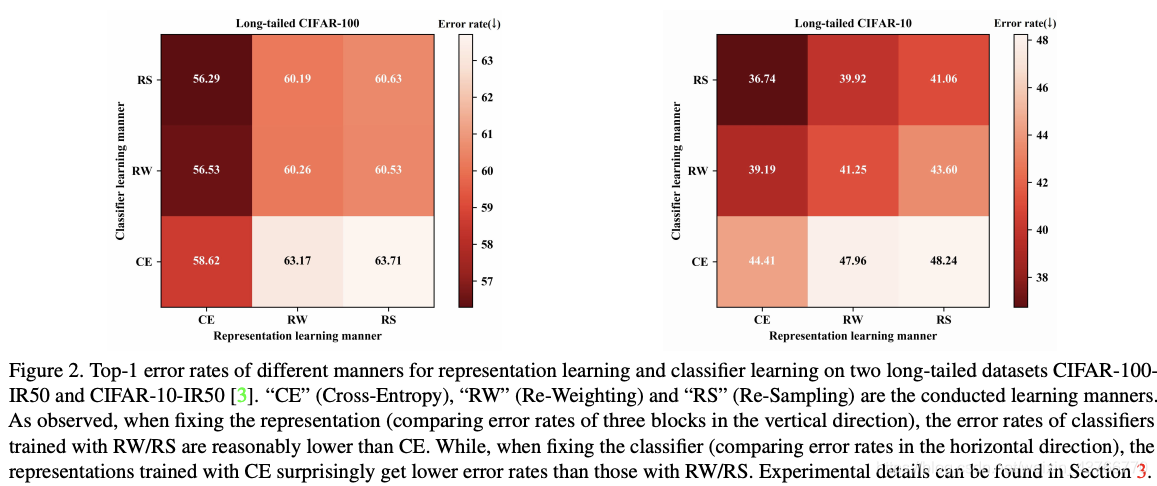
从垂直的方向上看,在进行了RS或RW操作后的分类器性能是有所提升的;从水平方向上看,进行了RS或RW操作后降低了特征提取器的分辨能力。 -
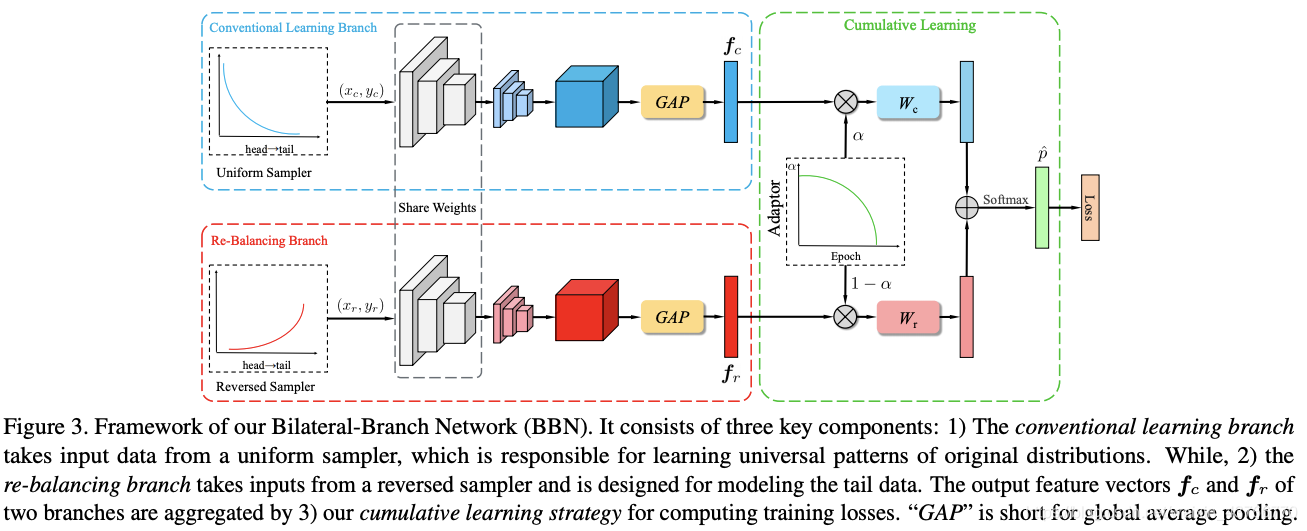
Overall Framework
BBN包括三部分:包含特征学习和分类器学习的Conventional Learning Branch和Re-balancing branch,两个分支共享除了最后一个残差块之外的残差网络参数。将训练样本经过各自分支的处理之后输入到各个分支网络中,得到了 f c f_c fc和 f r f_r fr,继而设计一个累积学习策略,最终的类别通过softmax函数得到,最终的训练仍然是端到端的形式。
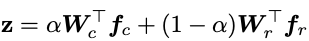
-
Proposed bilateral-branch structure
描述了两个细节:数据采样和两个分支的权值共享,权值共享有两个好处:conventional分支的良好学习也有利于re-balancing分支的学习;共享权值也能够降低计算的复杂度。 -
Proposed cumulative learning strategy
提出了comulative 学习策略来调整两个网络学习的重点,这个策略让模型的学习中点从关注普遍特征到关注长尾分布的数据,就是公式中 α \alpha α, α \alpha α的值是随着训练的epoch数变化的。 -
Inference phase
在infer阶段,由于两个分支同等重要所以将自适应 α \alpha α设置为0.5。 -
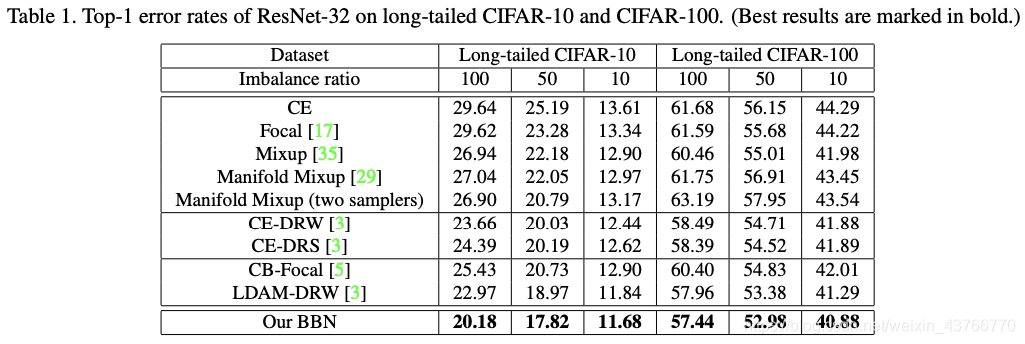
Results
(cvpr2020)CentripetalNet: Pursuing High-quality Keypoint Pairs for Object Detection
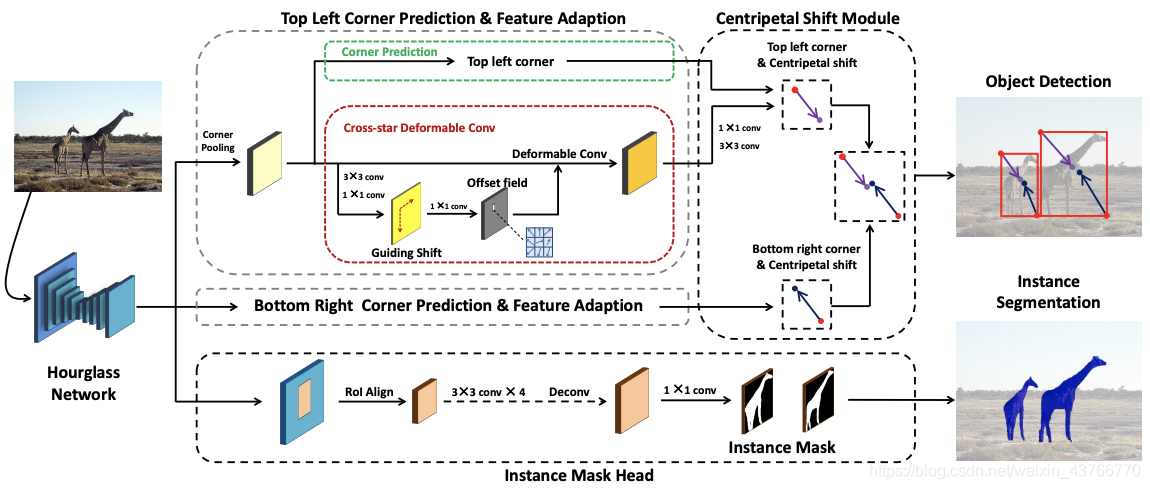
摘要 这篇文章提出了CentripetalNet,此网络预测corners的位置和向心位移,并根据位移对齐找到匹配的corners。在这里我将corners理解成为拐点。此外还设计了一个cross-star deformable卷积网络来进行特征自适应。Furthermore,通过在anchor-free 的探测器上equip一个轮廓预测模块来研究实例分割。
基于关键点的检测器取得了不错的效果,但是错误的关键点匹配也极大影响了检测器的性能。本文提出的CentripetalNet通过向心位移来匹配拐点,预测拐点的位置和向心位移,匹配位移结果对齐的拐点。由于结合了位置信息,本文所提的方法比传统的嵌入式方法准确率更高。corner pooling将边界框内部的信息提取到了border上,所以设计了cross-star deformable卷积网络进行特征自适应。此外在网络中的添加轮廓预测模块来进行anchor-free的实例分割。
-
CentripetalNet
CentripetalNet包含四个部分:拐点预测模块、向心偏移模块、cross-start deformable卷积模块和instance 轮廓head。首先通过CornerNet pipeline产生候选拐点,对所有的候选拐点,通过向心偏移程序得到高质量的拐点对并预测出bounding boxes。然后,提出了一个corss-star deformable convolution,其偏移场是通过拐点到其对应中心的偏移处学习的,目的是进行特征自适应来丰富拐点位置的视觉特征,这对于提高centripetal shift module的准确性非常重要。最终,增加了instance mask module来进一步的提升detector的表现,同时将我们的方法扩展到instance segmentation领域。本文的方法可以将预测bounding boxes的centripetalNet shift module看作是region proposals,使用ROIAlign来提取区域特征,并采用卷积网络预测segmentation mask. CentripetalNet通过端到端的方式进行训练。 -
Corner Matching
属于同一边界框的一对角应该共享该框的中心。我们可以通过预测出来的拐点的位置和向心位移确定出边界框的中心,这样就比较容易的比较一对corners的中心是否足够接近,是否与拐点对组成边界框的中心足够接近。 -
Cross-star Deformable Convolution
由于corner pooling,在feature maps上就会出现一些’cross stars’, 'cross stars’的边界保留了object的上下文信息,因为corner pooling使用max和sum操作将物体的位置信息可扩展到拐点。我们发现cross star的形状与bouding box的形状有关,要了解cross star的几何结构,可以在网络中采用相应物体的尺寸来显示的给offset field提供信息。但我们发现如图4,cross star的左上角部分应该得到较少的关注,因为在物体外有比较多的无效信息,针对这种情况,我们在offset field branch前面嵌入guiding shift,guiding shift中包含了形状和方向信息。

-
Instant Mask Head
如果想要得到实例的分割轮廓,首先,预训练CentripetalNet几个epoch,选择得到较高的k个proposals,进行RoIAlign后得到feature maps,经过4个3x3的卷积层后,使用一个transposed 卷积层上采样到28x28的mask map。
(cvpr2020)Attention Convolutional Binary Neural Tree for Fine-Grained Visual Categorization
摘要细粒度分类(Fine-Grained Visual Categorization, FGVC)是图片分类的一个分支,由于类别间的相似性非常大,一般人比较难区分,所以是个很有研究意义的领域。受神经树研究的启发,论文设计了结合注意力卷积的二叉神经树结构(attention convolutional binary neural tree architecture, ACNet)用于弱监督的细粒度分类,在树结构的边上结合了注意力卷积操作,在每个节点使用路由函数来定义从根节点到叶节点的计算路径。这样的结构让算法有类似神经网络的表达能力,能够从粗到细的层级学习特征,不同的分支专注不同的局部区域,最后结合所有叶子结点的预测值进行最终的预测。添加了attention transformer模块来加强网络获取关键特征的能力来进行准确分类。

ACNet包含四个模块,分别是主干网络(backbone network)、分支路由(branch routing)、attention transformer和标签预测(label prediction)。
-
Backbone network module
由于细粒度的关键特征都是高度局部化的,需要相对较小的感受域来进行特征提取,这里的backbone采用了预训练的截断VGG16,输入改为448*448; -
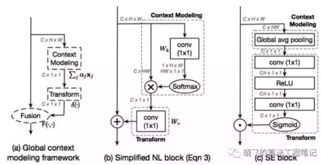
Branch routing module分支路由
使用分支路由确定将样本分配到哪一个叶节点上。k-th层的i-th路由模块由1x1卷积和global context block组成,context modeling和fusion步骤使用了simplified NL block,在transform中使用了SE block,这个模块能够很好的结合上下文悉信息进行特征提取,最后使用global average pooling、element-wise square-root 、L2正则化以及simoid激活的全连接层输出。
-
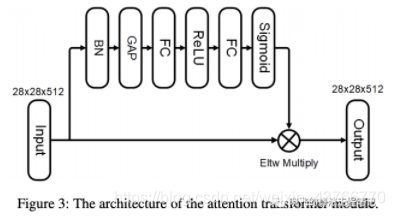
Attention transformer
Attention transformer模块用于加强网络获取关键特征的能力,在卷积层后面添加如图的结构,该模块的旁路输出一个大小为CX1X1的channel attention map对输入特征进行加权。
-
Label Prediction 通过求和所有叶子节点的预测结果和路径累计概率的乘积作为最终的预测结果,最终的预测结果加和为1.
-
Loss function损失函数由两部分组成,叶节点预测产生的损失和最最终结果产生的损失。
(cvpr2020)Learning in the Frequency Domain
摘要 现有的神经网络主要在固定输入大小的空间域中运行,在实际应用中,通常图像较大,所以需要将图像降采样为神经网络的固定输入大小,下采样会导致部分信息丢失从而使得网络精度下降。受到数字信号理论的启发,从频域的角度分析频谱偏差,提出一种基于学习的频率选择方法,来识别可以去除但无损精度的频率分量。本文所提的频域学习方法利用了熟知的神经网络结构,如:ResNet50、Mobilenet-V2和mask R-CNN,同时接受频域信息作为输入。通过实验表明频域学习方法比传统的下采样方法精度更高,同时还可以进一步减小输入数据量。
本文中建议在频域中重塑高分辨率图像,而不是在空间调整图像大小,并将reshape后的DCT系数输入到CNN中进行inference。本文的方法几乎不需要修改现存的以RGB图像作为输入的CNN模型,它可作为常规的数据预处理流程的替代品,实验证明与输入数据大小相等或者更小的RGB方法相比,我们的方法在图像分类、检测和分割任务中有更高的准确性。所提的方法能够使得所需芯片通信带宽的减少。
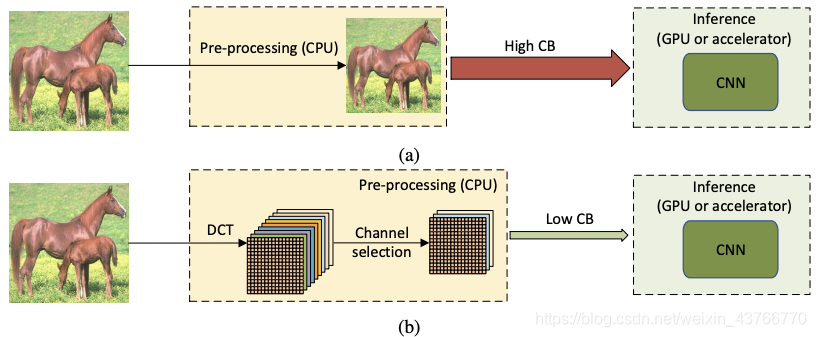
传统的方法中,通常在CPU上对高分辨率RGB图像进行预处理,然后将其传输到GPU/AI加速器来进行实时推理。RGB格式的未压缩图像通常较大,因此CPU与GPU之间的通信带宽要求通常很高,这种带宽可能成为系统性能的瓶颈。为了降低计算成本和通信带宽的要求,将图片下采样为较小的图片会导致信息丢失从而降低精度。在本文的方法中,高分辨率RGB图像仍然在CPU上进行处理,但首先将图像转换到YCbCr颜色空间,然后转移到频域,相同频率的分量被分到同一个通道中,形成了多个频道。在进行传输过程中,保留最重要的频道传输到GPU上进行infer,这种方法的精度更高。
在实际应用中,只需要删除输入的CNN层,保留剩下的模块,修改输入的通道数量来适应图片DCT系数输入的尺寸,这样修改后的模型可以保持与原模型相似的参数和计算复杂度。
- Data Pre-processing in Frequency Domain
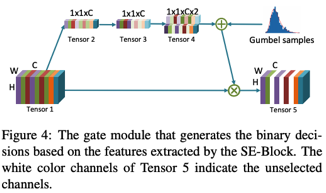
数据预处理流程如图2所示。我们遵循空间域中的预处理和扩充流程,包括图像大小调整,裁剪和翻转(图2中的空间调整大小和裁剪)。 然后将图像转换到YCbCr颜色空间并转换到频域(图2中的DCT转换)。 将相同频率的二维DCT系数分组到一个通道中,以形成三维DCT立方体(图2中的DCT整形。 选择有影响力的频道的子集(图2中的DCT频道选择)。 YCbCr颜色空间中的选定通道串联在一起形成一个张量(图2中串联的DCT)。最后,通过从训练数据集计算出的均值和方差对每个频道进行归一化。从大小为448x448x3的输入图像转换为DCT,在空间域上保留的信息比224x224x3对应的信息多四倍,代价是输入特征尺寸的四倍。 - Learning-based Frequency Channel Selection
输入的尺寸为W × H × C,通过average pooling转化成tensor2,然后通过一个卷积层变为tensor3,tensor3分别乘上两个可训练参数变为tensor4,最后一唯的两个参数分别表示每个channel打开和关闭的概率。通过通道筛选后得到tensor5,某个频率是否使用是通过伯努利分布进行采样来决定,伯努利分布的p是通过1×1×C×2张量中的最后一唯数据计算得出的。ti
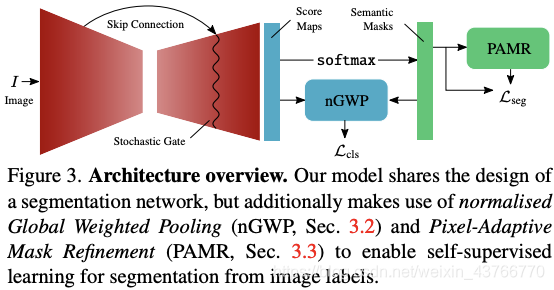
(cvpr2020)Single-Stage Semantic Segmentation from Image Labels
摘要 弱监督的情况下提升语义分割的准确性是以增加模型的复杂度或进行复杂的多阶段训练为代价的。在这篇文章中,首先定义了弱监督方法的三个理想属性:局部一致性、语义保真性和完整性。基于以上属性,这篇文章提出了基于分割的网络模型和自我监督的训练方案,在one-stage中训练来自图像级注释的语义mask。尽管提出的方法较为简单,但我们方法取得的结果与更复杂的网络相比更有优势。
这篇文章有些晦涩,读了一部分之后有些读不下去了,就先搁置了
提出了三个新颖的组件:一个新的类别的聚合函数、局部轮廓细化模块和随机门(a new class aggregation function, a local mask refinement module, and a stochastic gate)。
(非CVPR) Scalable Arrow Detection in Biomedical Images
摘要 这篇文章提出了在生物医学影像中检测出箭头的方法,提出一种signature,通过对比候选区域signature和理论signature进行对比,判断是否含有箭头。















 334
334











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









