







 ResNet-18:Train and Test Records文章目录ResNet-18:Train and Test Records一、固定学习率1、LR=0.1 (SGD+M!!!)不同optim1.SGD实验1.1-SGD实验1.2-SGD+M=0.9实验1.3-SGD+M=0.9+weight_decay=1e-3实验1.4-SGD+M=0+Nestrrov=True实验1.5-SGD+M=0.9+Nesterov=True2.Adam实验1.6-Adam3.Adagrad实验1.7-Adagr
ResNet-18:Train and Test Records文章目录ResNet-18:Train and Test Records一、固定学习率1、LR=0.1 (SGD+M!!!)不同optim1.SGD实验1.1-SGD实验1.2-SGD+M=0.9实验1.3-SGD+M=0.9+weight_decay=1e-3实验1.4-SGD+M=0+Nestrrov=True实验1.5-SGD+M=0.9+Nesterov=True2.Adam实验1.6-Adam3.Adagrad实验1.7-Adagr
ResNet-18:Train and Test Records
文章目录
**不变量:**200轮,ResNet18,输入图像大小32(pad=4,randomCrop=32)、batchsize=256
**变量:**学习率,优化器,策略
注:由于实验是在32×32的小图像上,故不应在第二层之前用maxpooling(Thank to tearcher Shi.),但我一开始不知道,所以训练的效果都无法到达90%,修改后可以达到较高准确率,由于本质相同,故我仅做一组实验对比效果(LR=0.1,SGD+M=0.9,CosineAnnealingWarm)。
一、固定学习率
1、LR=0.1 (SGD+M!!!)
不同optim
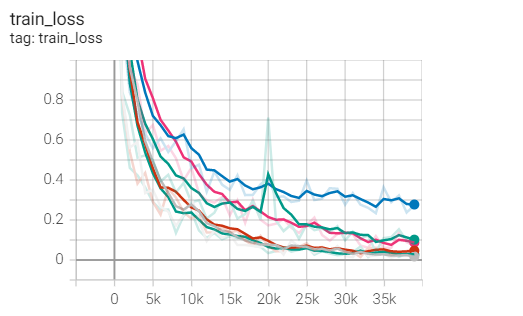

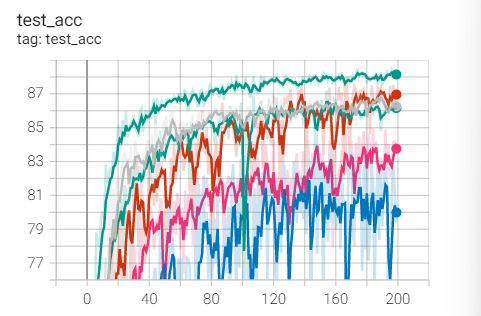
1.SGD
实验1.1-SGD
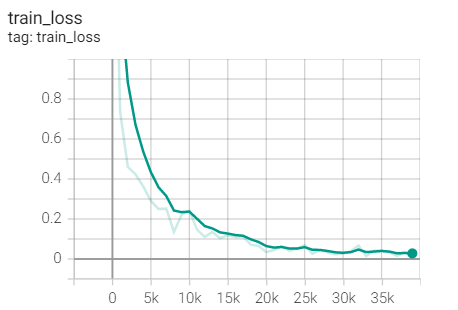
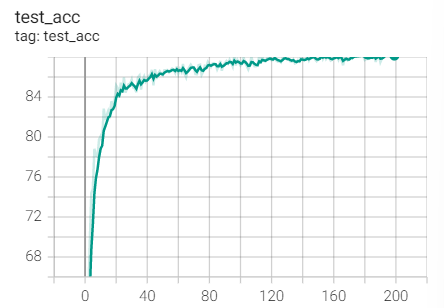
实验1.2-SGD+M=0.9

实验1.3-SGD+M=0.9+weight_decay=1e-3
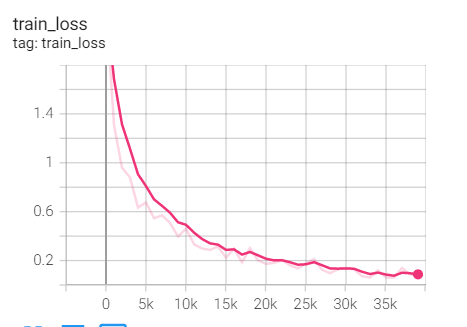

实验1.4-SGD+M=0+Nestrrov=True
实验1.5-SGD+M=0.9+Nesterov=True
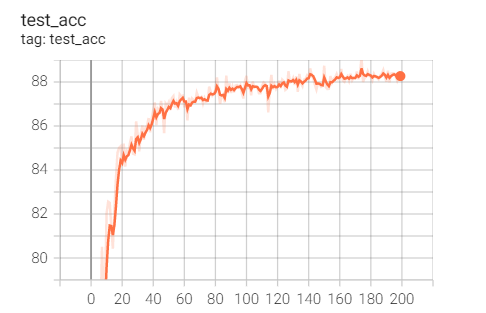
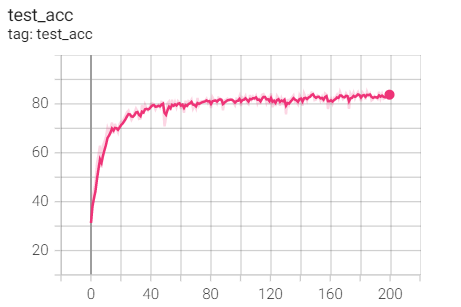
2.Adam
实验1.6-Adam
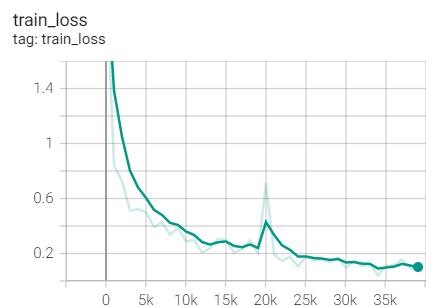

3.Adagrad
实验1.7-Adagrad
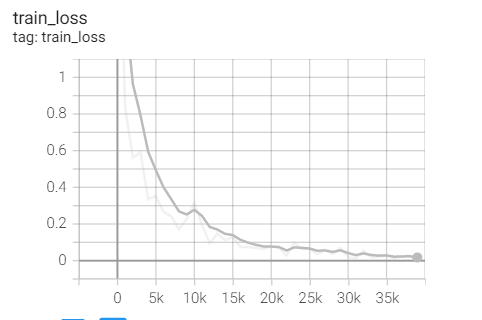
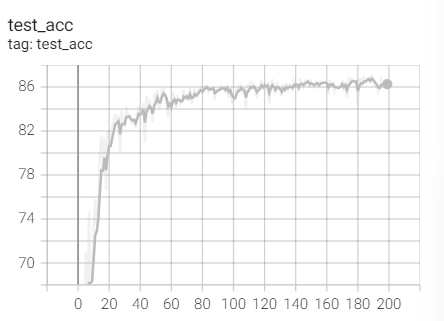
4.RMSprop
实验1.8-RMSprop
2、LR=1e-2 (SGD+M!!!)
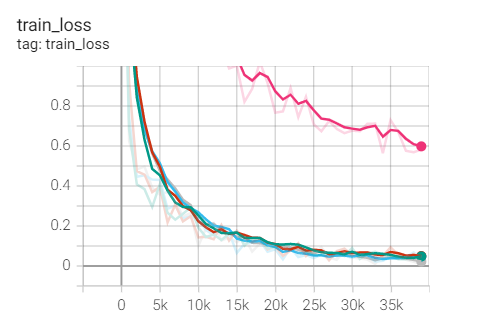

实验1.9 SGD

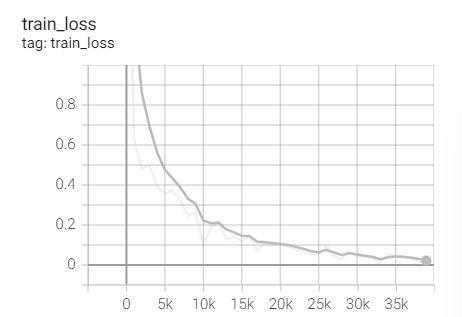
实验1.10 SGD+M


实验1.11 Adam


实验1.12 Adagrad

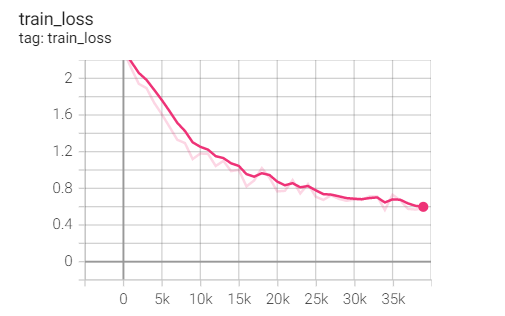
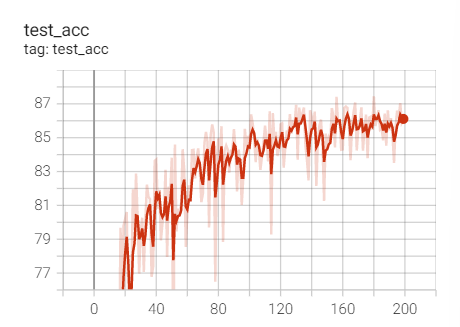
实验1.13-RMSprop

3、LR=1e-3
实验1.14-SGD
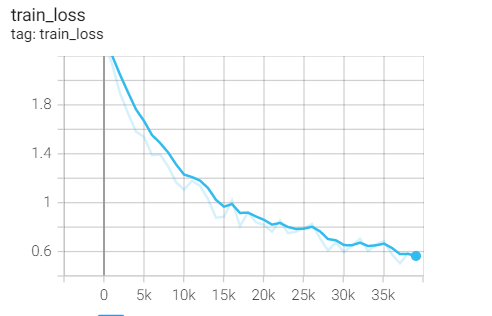
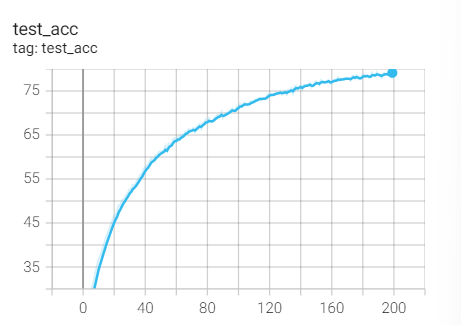
二、学习率变化
1、余弦模拟退火
T_max=25,即半周期为25个epoch,全周期为50,那么在200轮中会有4个周期。
不同optim
1.SGD+Momentum
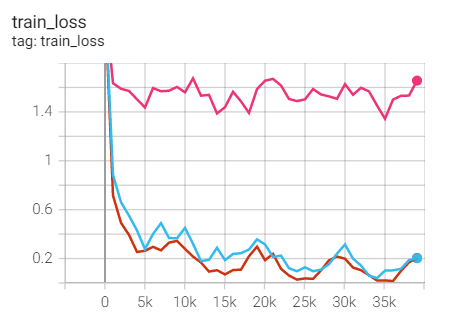
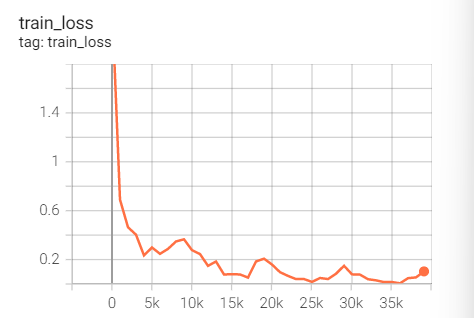
实验2.1:LR=0.1,M=0.9,no weight decay
初始学习率0.1,带动量(0.9)的SGD优化器,no weight decay
optimizer = optim.SGD(net.parameters(),lr=args.lr,
momentum=0.9)
scheduler = torch.optim.lr_scheduler.CosineAnnealingLR(optimizer,T_max=20)
 最低0.47元/天 解锁文章
最低0.47元/天 解锁文章
















 1834
1834











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









