







 包装法是一种特征选择方法,结合模型训练,利用目标函数如RFE进行特征重要性评估。RFE通过反复训练模型并剔除最不重要特征,找到最佳特征子集。示例中,RFE在手写数字识别数据集上展示了高效性能,通过学习曲线找到最佳特征数,提升了模型表现。包装法计算量较大,适用于中等规模数据,优于过滤法,与嵌入法效果相当。
包装法是一种特征选择方法,结合模型训练,利用目标函数如RFE进行特征重要性评估。RFE通过反复训练模型并剔除最不重要特征,找到最佳特征子集。示例中,RFE在手写数字识别数据集上展示了高效性能,通过学习曲线找到最佳特征数,提升了模型表现。包装法计算量较大,适用于中等规模数据,优于过滤法,与嵌入法效果相当。
文章目录
包装法概述
包装法,也是一个特征选择和算法训练同时进行的方法,与嵌入法十分相似
它也是依赖于算法自身的选择,比如coef_或feature_importances_属性来完成特征选择
不同的是我们往往使用一个目标函数作为黑盒来帮助我们完成特征选择,而不是我们自己输入某个评估指标或统计量的阈值
包装法在初始训练集上训练我们的评估器,并且通过coef_属性或feature_importances_属性获得每个特征的重要性
然后从当前的一组特征中删除掉一些最不重要的特征,然后在修改后的集合上重复该过程,直到最后剩下的特征是我们规定的数量
注意点:时间复杂度位于过滤法和嵌入法之间
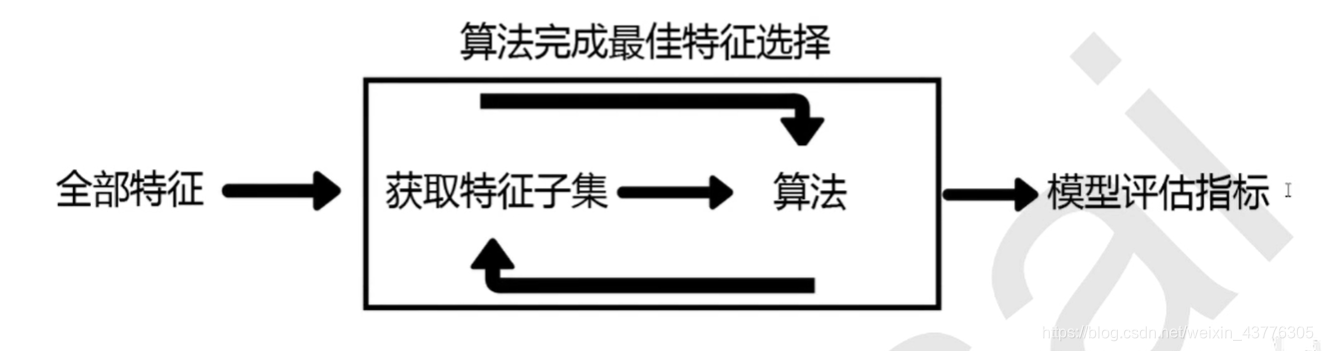
目标函数
最典型的目标函数是递归特征消除法(Recursive feature elimination,简写为RFE)。
它是一种贪婪的优化算法,旨在找到性能最佳的特征子集。
它反复创建模型,并在每次迭代时保留最佳特征或剔除最差特征,
下一次迭代时,它会使用上一次建模中没有被选中的特征来构建下一个模型,直到所有特征都耗尽为止。然后,它根据自己保留或剔除特征的顺序来对所有特征进行排名,最终选出一个最佳子集。
包装法的效果是所有特征选择方法中最利于提升模型表现的,它可以使用很少的特征达到很优秀的效果。
除此之外,在特征数目相同时,包装法和嵌入法的效果能够匹敌,不过它比嵌入法算得更快,
虽然它的计算量也十分庞大,不适用于太大型的数据。但是,包装法任然是最高效的特征选择方法。
feature_selection.RFE简述
重要参数
- estimator:实例化后的评估器
- n_features_to_select:要选择的特征个数
- step:每次迭代中希望删除的特征最大数量。每次删除的特征数量一定是小于等于step值的
重要属性
- support_:返回所有特征最后的选择情况的bool矩阵
- ranking_:特征重要性的排名
示例
导入相关库
import pandas as pd
import numpy as np
import matplotlib.pyplot as plt
from sklearn.ensemble import RandomForestClassifier
from sklearn.feature_selection import RFE # 目标函数
from sklearn.model_selection import cross_val_score
%matplotlib inline
导入数据,分割特征标签
这次使用的仍然是digit-recognizer数据集。原数据下载地址,快捷下载
file_name = "E://anaconda/machine-learning/test1/data/digit-recognizer/train.csv"
df = pd.read_csv(file_name)
X = df.loc[:, df.columns != 'label']
y = df.loc[:, df.columns == 'label'].values.ravel()
X.shape # (42000, 784)
 最低0.47元/天 解锁文章
最低0.47元/天 解锁文章


















 797
797

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









