







前言
内容来源:
CVPR 2022:Revisiting Weakly Supervised Pre-Training of Visual Perception Models
一、标题 作者

二、摘要
Model pre-training is a cornerstone of modern visual recognition systems. Although fully supervised pre-training on datasets like ImageNet is still the de-facto standard, recent studies suggest that largescale weakly supervised pretraining can outperform fully supervised approaches. This
paper revisits weakly-supervised pre-training of models using hashtag supervision with modern versions of residual networks and the largest-ever dataset of images and corresponding hashtags. We study the performance of the resulting models in various transfer-learning settings including
zero-shot transfer . We also compare our models with those obtained via large-scale self-supervised learning. We find our weakly-supervised models to be very competitive across all settings, and find they substantially outperform their self-supervised counterparts. We also include an investigation into whether our models learned potentially troubling associations or stereotypes. Overall, our results pro-
vide a compelling argument for the use of weakly supervised learning in the development of visual recognition systems.
Our models, Supervised Weakly through hashtAGs (SWAG),are available publicly.
模型预训练是现代视觉识别系统的一个基石。尽管在ImageNet这样的数据集上进行完全监督的预训练仍然是事实上的标准,但最近的研究表明,大规模的弱监督预训练可以胜过完全监督的方法。 本文通过现代版本的残差网络和有史以来最大的图像和相应的标签数据集,重新审视了使用标签监督的弱监督预训练的模型。我们研究了所得到的模型在各种迁移学习设置中的表现,包括zero-shot 迁移。我们还将我们的模型与那些通过大规模自我监督学习获得的模型进行了比较。我们发现我们的弱监督模型在所有的环境中都非常有竞争力,并且发现它们大大超过了自我监督的对应模型。我们还调查了我们的模型是否学到了潜在的存在问题的关联或定型观念。总的来说,我们的结果为在视觉识别系统的发展中使用弱监督学习提供了一个令人信服的论据。
我们的模型,即通过hashtAGs(SWAG)进行监督的弱监督模型,可以公开获得。
三、正文
1. Introduction
大多数现代的视觉识别系统都是基于机器学习模型,这些模型被预先训练来执行与系统要解决的下游任务不同的任务。这种预训练允许系统利用比下游任务可用的数据集大得多的(有注释的)图像或视频数据集。 可以说,最流行的预训练任务是ImageNet和JFT等数据集上的监督图像分类,但最近的研究也探索了预训练的自监督和弱监督任务。
三种类型的预训练之间是有权衡的。全监督预训练得益于每个训练实例的强大语义学习信号,但由于训练数据的手工标注很耗时,所以不能很好地扩展。相比之下,自监督预训练几乎没有收到任何关于训练实例的语义信息,但是可以相对容易地扩展到数十亿的训练实例。弱监督预训练方法介于两者之间:例如,标签或其他与视觉数据相关的文本通常提供一个嘈杂的语义学习信号,但可以相对容易地大规模获得。
在之前的工作成功之后,本文对使用标签监督的弱监督预训练进行了深入研究。我们在有史以来最大的图像和相关标签数据集上对现代图像识别模型进行预训练,并在一系列的迁移学习实验中评估所得到的模型。具体来说,我们将我们的模型转移到各种图像分类任务中,并评估所产生的模型的性能。我们还在zero-shot 迁移和few-shot迁移的设置中评估了这些模型:也就是说,我们评估了这些模型的 “现成性能”,而没有在目标任务中对它们进行微调。我们研究的总体目标是阐明全监督、自监督和弱监督的预训练之间的权衡(Task)。在整个实验中,我们发现弱监督的方法非常有竞争力:尽管采用了相对简单的训练pipeline,我们最好的模型在一系列的视觉感知任务中的表现与最先进的水平相当。
弱监督预训练的一个潜在缺点是模型可能会继承或放大潜在监督信号的有害关联(Challenge)。我们进行了一系列实验,旨在评估这种情况发生的程度。我们的结果没有提供决定性的答案,但它们确实表明所涉及的风险可能不像语言建模那样大 。总的来说,我们相信我们的研究为视觉识别系统的弱监督预训练提供了一个令人信服的论据。
2. Related Work
我们的研究建立在ECCV 2018: Exploring the Limits of Weakly Supervised Pretraining [49] 的基础上,它在数十亿张图像上训练卷积网络来预测相关的标签。与 [49] 相比,我们的研究:(Task)
- 在更大的数据集上使用更高效的卷积和transformer架构训练更大的模型
- 除了标准的迁移学习实验之外,还研究了zero-shot迁移设置中所得模型的性能
- 将我们的模型与最先进的自我监督学习进行比较
- 深入研究模型可能从他们接受的弱监督中采用的潜在有害关联
尽管我们的方法在概念上有相似之处,但我们最好的模型实现了 ImageNet-1K 验证精度,比 [49] 中报告的精度高 3% 以上。
3. Pre-Training using Hashtag Supervision
我们的弱监督预训练方法基于标签监督。我们训练图像识别模型来预测发布图像的人分配给图像的标签。标签预测作为预训练任务具有巨大潜力,因为标签被分配给图像以使其可搜索,即它们倾向于描述图像的一些显著语义方面。虽然主题标签预测在概念上类似于图像分类,但它在几个关键方面有所不同: (Challenge)
-
标签监督本质上是嘈杂的。 虽然一些主题标签描述了图像中的视觉内容(例如,#cat),但其他主题标签可能与视觉内容无关(例如,#repost)。可以使用不同的主题标签来描述相同的视觉内容,或者可以使用相同的标签来描述不同的视觉内容。重要的是,标签通常不提供图像视觉内容的全面注释,即往往存在许多假阴性。
-
标签的使用遵循 Zipfian 分布; 参见图 1。这意味着学习信号遵循的分布与 ImageNet [63] 等图像识别数据集中常见的分布非常不同,后者往往具有或多或少均匀的类分布。

图1 Instagram图片的标签分发。左:美国用户发布的公开图片中所有标签出现的频率。右:来自所有国家的用户在公共图像中过滤和规范化标签出现的频率。我们将头部[^1] 定义为与5000多张图片相关联的规范标签集;剩下的标签组成了尾巴[^2] 。 -
标签监督本质上是多标签的: 一张图片通常有多个与之关联的标签,它们都作为正分类目标。
我们的数据预处理和模型预训练程序旨在(部分)解决这些问题。我们分别在第 3.1 节和第 3.2 节中更详细地描述了它们。
3.1. Hashtag Dataset Collection
我们跟随[49]构建了一个公开Instagram照片和相关标签的数据集。我们采用以下四个步骤来构建预训练数据集:
(Method)
-
通过选择常用的标签并将其规范化来构建一个标签词汇表。
-
收集标有至少一个所选标签的公开可用图像。
-
将生成的图像和相关的标签组合成可用于预训练的标记示例。
-
重新对结果示例进行采样,以获得所需的标签分布。
接下来,我们将详细描述这些步骤。
标签词汇。 我们选择美国用户在Instagram公开帖子中使用过一次以上的标签。接下来,我们使用WordNet同义词集过滤并规范化标签。关于这个过程的更多细节见附录A。
这将产生一个标签集
C
C
C,其中包含约27k个标准标签,对应于一组约75k个原始标签,其中多个标签可以映射到单个标准标签(例如,#dog和#canine)。当“规范”限定词在上下文中很明显时[^3],我们就省略它。由于数据集中的确切图像可能随着时间而变化,因此在整个实验中,规范标签的数量在27k到28k之间变化。标签选择和规范化减少了监控信号中的一些固有噪声。
图像收集和标记。 我们收集所有公开的Instagram图片,这些图片至少有一个标签来自我们的词汇表。这些图片经过一系列自动过滤器过滤,以去除潜在的冒犯性内容。虽然这当然不是完美的,但这大大减少了困扰其他大型图像数据集的问题。通过将所有标签转换为相应的规范目标(注意,单个图像可能有多个标签),我们使用这些图像构建了一个多标签数据集。
重采样。 我们采用类似于[49]的重采样过程来生成我们最终的预训练示例。重采样过程的目的是在训练前任务中降低频繁标签的权重,同时提高不频繁标签的权重。我们通过根据标签频率的平方根倒数重新采样来做到这一点。与[49]不同的是,我们额外对至少有一个不常见标签的图像的长尾进行采样(替换)~ 100×。在这里,我们将不经常出现的标签定义为图像少于5000张的标签(见图1)。结果重新采样的数据集包括30%的尾部图像和70%的头部图像(详见附录A)。
不在词汇表中的标签将被丢弃。
我们注意到,这意味着在单个训练epoch,每个唯一的尾图像出现多次(重采样的原因)。这意味着在一个epoch中唯一图像的数量与该epoch中处理的总样本数量之间存在差异。我们根据数据集中唯一图像的数量来标记数据集:我们的IG-3.6B数据集有大约36亿张唯一图像。然而,由于我们的重新采样过程,该数据集上的单个训练周期处理了约50亿个样本。这与我们比较的其他数据集(例如JFT-300M)不同,其中图像的唯一数量等于在一个epoch中处理的总样本。
We note that this means that in a single training epoch, each unique tail image appears multiple times. This implies there is a discrepancy between the number of unique images in an epoch and the number of total samples processed in that epoch. We label our dataset by the number of unique images in the dataset: our IG-3.6B dataset has ∼3.6 billion unique images. However, a single training epoch over that dataset processes ∼5 billion samples due to our re-sampling procedure. This is different from other datasets we compare with (e.g., JFT-300M) in which the unique number of images equals the total samples processed in an epoch.
个人理解:
由于重采样,开始的时候本来唯一的尾部图像会在一个epoch里面多次出现
所以我们改变策略,把这些唯一的图像进行标注,得到36亿张图像
由于我们已经做了标注,避免一张图片多次出现的问题,然后再进行重新的采样,得到50亿张图像,现在数据集中每张图片都是唯一的。
3.2. Pre-Training Procedure
在初步实验(附录 C.1)中,我们研究了图像识别模型,包括 ResNeXt、RegNetY、DenseNet、EfficientNet和 ViT。我们发现 RegNetY 和 ViT 模型最具竞争力。
在预训练期间,我们为我们的模型配备了 ∣ C ∣ |C| ∣C∣ 上的输出线性分类器 ≈ 27k 类。对于 ViT,我们使用一个额外的线性层,输出维度等于输入维度。在 [49] 之后,我们使用 softmax 激活并训练模型以最小化预测概率和目标分布之间的交叉熵。每个目标条目是 1 / K 1/K 1/K 或 0 0 0,具体取决于相应的标签是否存在,其中 K K K 是该图像的标签数。
4. Experiments
我们进行了一系列实验来测试我们基于标签的预训练策略的有效性。我们将迁移学习实验中的弱监督模型与现代监督模型(第4.2节)和自监督模型(第4.3节)进行了比较,并与zero-shot迁移中的其他弱监督模型(第4.4节)进行了比较。
4.1. Experimental Setup
在我们的实验中,我们专注于不同类型的迁移学习到图像分类任务。 具体来说,我们研究:
- 使用线性分类器的迁移学习
- 使用微调的迁移学习
- zero-shot迁移学习
- few-shot迁移学习
我们将我们的预训练策略的效果与完全监督 (4.2) 和 自我监督 (4.3) 预训练策略的效果进行了比较。
数据集。 我们在 ImageNet-1k(128 万张训练图像、50,000 张验证图像、1,000 个类别)和 ImageNet-5k(657 万张训练图像、250,000 张验证图像、5,000 个类别)上执行将模型转移到 ImageNet 分类的实验,如定义。我们还进行实验,将预训练模型转移到其他常用的图像分类基准,包括 iNaturalist 2018、Places365-Standard和 Caltech-UCSD Birds-200-2011 (CUB-2011)数据集。
微调。 我们按照为下游任务微调我们的预训练模型。我们使用批量大小为 512 的 SGD 和半余弦学习率计划 对模型进行微调。通过网格搜索分别为每个模型任务组合调整初始值。
我们在微调期间没有使用权重衰减。我们使用 384 × 384 的图像分辨率对 RegNetY 和 ViT B/16 模型进行微调,ViT L/16 和 H/14 模型分别具有更大的 512 × 512 和 518 × 518 分辨率——更高的分辨率对这些模型有显着帮助。对于 EfficientNets,我们使用预训练分辨率进行微调。对于“大型”迁移数据集(定义为具有 N > 500,000 个示例的数据集),我们微调了 20,000 个参数更新;对于“中等”数据集(20,000 < N ≤ 500,000 个示例),我们微调 10,000 步;对于“小”数据集(N ≤ 20,000 个示例),我们微调 500 步。
提分细节
在对所有数据集进行微调期间,我们使用 α = 0.1 的混合。我们使用了跨 GPU 的同步批量归一化,因为它提高了迁移性能(见附录)。
对于 ImageNet-1k 微调,我们还计算了训练期间参数的指数移动平均值 (EMA),衰减率为 10−4,并使用平均权重进行推理。我们发现这将我们最好的 RegNetY 和 ViT 模型的 top1 精度提高了 0.2%。
最后,我们在 ImageNet-1k 上微调了 28 个 epoch 的 ViT,因为更长的时间表有助于提高性能。
在评估期间,我们将图像较小的一侧调整为最终分辨率,然后采用相同尺寸的中心裁剪(例如,将较小的一侧调整为 224,然后将中心裁剪为 224 × 224)。这不同于标准做法,但在 ImageNet-1k 数据集上提高了 0.1% 到 0.5%。
4.2. Comparison with Supervised Pre-Training
我们在五个数据集的迁移学习实验中将我们的弱监督 RegNetY 和 ViT 模型与最先进的监督 EfficientNets 和 ViTs 进行了比较: (1) ImageNet-1k,(2) ImageNet-5k、(3) iNaturalist、(4) Places365 和 (5) CUB-2011。我们在传输数据集的训练拆分上微调所有模型(参见 4.1),并测量微调模型在验证或测试拆分上的分类准确性。
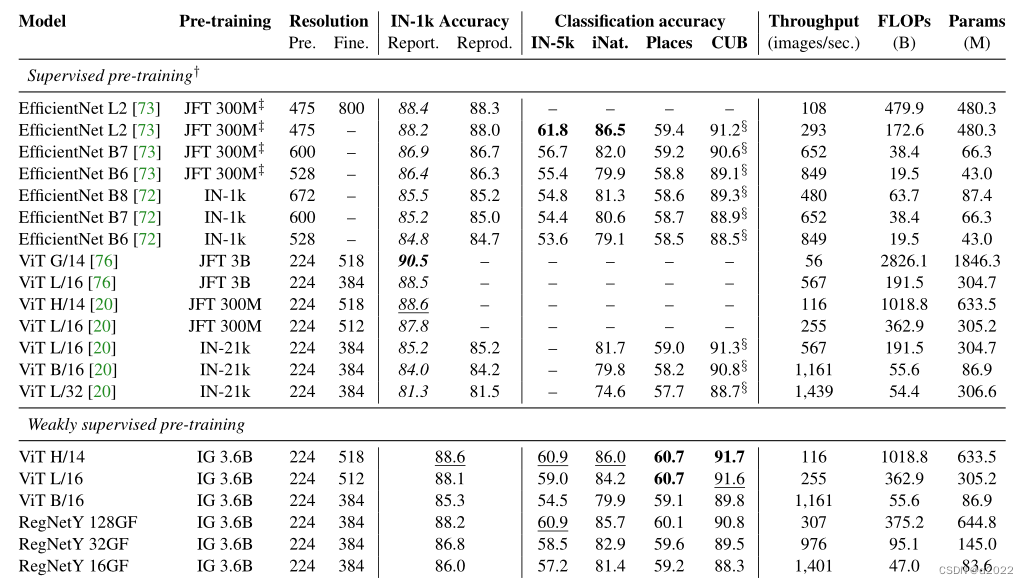
表 1 概述了这些实验的结果。对于每个模型,该表显示了使用的预训练数据集、预训练和微调期间使用的图像分辨率、模型的推理吞吐量、微调模型中的 FLOPs 和参数的数量,以及传输上的测试精度数据集。当预训练模型和预训练数据集不公开时,我们不会报告方法的结果。在表中,我们从原始论文中采用的准确度用斜体表示。对于 ImageNet-1k 数据集,我们报告了原始论文中报告的结果和我们在重现模型时获得的结果。我们将最好的结果加粗,并在每个数据集的次佳结果下划线。 表 1 将模型分为监督和弱监督。在这个分组中,我们认为对 JFT 数据集的预训练是有监督的预训练,但我们承认对如何收集这些数据集知之甚少:将 JFT-3B 数据集称为“弱标记”和“嘈杂” ”,但[76]也指出使用了半自动注释来收集它。这表明 JFT 数据集是人工管理和注释的,这就是我们将它们视为受监督的原因。
表 1 中的结果表明我们的弱监督模型非常有竞争力:它们在所有五个传输数据集上都达到了最好或第二好的精度。我们注意到,在 IN-1k 数据集上预训练的模型在预训练期间观察到 5% 的 CUB 测试数据 [49],因此它们的性能被高估了。这使得我们的弱监督模型(做在训练期间看不到测试数据)特别值得注意。
为了更深入地了解分类精度和吞吐量权衡,我们在图 2 中绘制了一个作为另一个的函数。比较在同一 IG-3.6B 数据集上训练的 ViT 和 RegNetY 模型,我们观察到ViT获得最高分类精度。在准确性与吞吐量的权衡方面,RegNetYs 在中小型模型上表现出色。 RegNetY 128GF 模型在准确性和吞吐量方面的表现与半监督 EfficientNet L2 模型非常相似,但在较小的规模下,RegNetYs 提供了更好的权衡。

图 2. 迁移学习准确性与在五个数据集上微调的预训练模型吞吐量的函数关系(完整结果请参阅表 1)。 ViTs 和 EfficientNets 达到了最高的准确度,但 RegNetY 模型在高吞吐量条件下表现更好
4.3. Comparison with Self-Supervised Pre-Training
到目前为止,我们的实验表明,将弱监督预训练扩展到数十亿张图像的能力可以抵消每个训练示例获得的较少学习信号量。这就提出了一个问题,即我们是否需要弱监督,或者现代自我监督学习者是否足够。自我监督学习比弱监督学习更容易扩展,之前的工作已经证明了自我监督预训练的潜力。
我们在 ImageNet1k 上执行迁移学习实验,将我们的弱监督学习器与 SimCLR v2、SEER和 BEiT进行比较。与 SEER 的比较特别有趣:因为它是在类似的 Instagram 图像集合上训练的,我们可以很容易地在同一数据分布上比较两种学习范式。我们在两种迁移学习设置中进行实验:(1) 一种设置,其中线性分类器附加在预训练模型之上,并对生成的完整模型进行微调;(2) 在微调整个模型之前使用第 4.4 节中描述的zero-shot迁移方法(没有 Platt 缩放)初始化此线性分类器的设置。根据之前的工作,我们将用于微调的标记 ImageNet 示例的数量改变为原始 ImageNet-1k 训练集的 1%、10% 和 100%。我们使用大小为 224×224 像素的图像报告结果。
表2:

我们的实验结果如表 2 所示。
SimCLRv2、SEER 和 BEiT 的结果取自;实验设置可能存在细微差异。我们的结果表明,弱监督学习大大优于当前的自我监督学习者,特别是在low-shot迁移设置中,这可能是因为我们的弱监督学习模型从每个样本接收到更多的学习信号。此外,我们的结果表明,弱监督学习受益于low-shot迁移设置中的zero-shot初始化。我们注意到,如果进一步扩大自我监督学习模型的规模,我们的观察结果可能会发生变化。
4.4. Zero-Shot Transfer
弱监督模型的另一个潜在优势是它们在预训练期间观察到大量不同的训练目标。这可能有助于他们快速地识别新的视觉概念。我们测试了我们的模型在zero-shot迁移学习设置中快速学习和识别新视觉概念的能力。在这个设置中,我们直接使用预训练模型的输出层,没有任何微调。 我们之所以能够做到这一点,是因为我们对从WordNet派生的 27k 个主题标签进行了训练,允许我们为数据集定义标签和类标签之间的映射,例如 ImageNet-1k,它也是基于 WordNet 构建的。我们使用与预训练相同的图像分辨率,即 224 × 224 像素。
普拉特缩放。 在我们的zero-shot迁移实验中,我们考虑了一个转导学习设置,其中所有测试示例在测试时同时可用。这使我们能够在测试数据上训练 Platt 缩放器,以纠正标签分布(Zipfian)和目标任务中类分布的差异。 Platt定标器被训练成最小化P‘的测试分布和C类上的均匀分布之间的交叉熵损失。请注意,这不使用测试标签;它只鼓励预测在类中保持一致。
从标签到ImageNet类的映射。 由于ImageNet和IG-3.6B数据集中的目标都是英语名词,因此我们可以在Instagram标签和ImageNet类之间构建多对多映射。 为此,我们首先将标签和ImageNet类映射到WordNet同义词集,然后根据它们在WordNet中的相似性将标签映射到ImageNet类。我们使用标签和类之间的多对多映射来聚合ImageNet类上的标签预测分数。我们试验了三种不同的聚合方法,并使用我们发现最适合每个模型的方法;有关详细信息,请参阅附录。
结果。 我们的zero-shot迁移结果显示在表3中。该表列出了我们的模型在使用和不使用普拉特缩放的情况下,在四个类ImageNet测试集上的TOP-1分类精度。我们将我们的模型与CLIP和Align的性能进行了比较。这些实验是系统级的比较,其中许多因素是不同的:例如,CLIP被训练在一个包含4亿张图片和字幕的数据集,看起来比我们的更精致,它在更高的分辨率下进行了微调,它通过提示工程执行zero-shot迁移,这是众所周知的提高识别精度。Align使用不同的图像识别模型(即EfficientNet),并对10亿对网络图像和相应的替代文本进行了训练。
表3:

表3给出了我们在四个类ImageNet数据集上进行零激发传输的结果。结果表明,我们的弱监督模型开箱即用性能非常好:在没有看到ImageNet图像的情况下,我们最好的模型达到了ImageNet TOP-1的75.3%的准确率。结果还表明,Platt Scaling对于我们的模型获得良好的zero-shot迁移性能是必不可少的,因为它纠正了标签和ImageNet类分布的差异。最后,我们发现我们的VIT模型在zero-shot迁移设置下的表现逊于我们的RegNetY模型。考虑到VITS在图像分辨率为224×224像素的ImageNet-1k微调上的表现也逊于RegNetY,这并不令人惊讶。
将我们的模型与CLIP进行比较,我们观察到CLIP VIT L/14模型在向IN-1K数据集的zero-shot迁移方面略优于我们的模型;而较小的RN50×64 CLIP模型的性能则逊于它。在某些数据集上,Align模型的性能甚至略好一些。然而,结果并不完全一致:我们的模型在ImageNet-v2数据集上确实获得了最佳性能。
由于这些实验执行的是系统级别的比较,因此很难阐明是什么导致了这些性能差异。尽管如此,我们的结果提供了进一步的证据,表明像我们的、CLIP和ALIGN这样的弱监督方法提供了一条通往开放世界视觉识别模型发展的有希望的道路。
5. Broader Impact
在未经整理的网络数据上对模型进行弱监督训练的一个潜在缺点是,它们可能会学习到反映冒犯性刻板印象的有害关联。
此外,这些模型对于不同的数据集可能效果不一样;例如,它们在非英语国家效果不佳,因为我们使用英语标签作为训练模型的基础。我们进行了一系列实验以更好地理解:(1) 我们的标签预测模型与具有不同特征的人的照片之间的关联,以及 (2) 这些模型对在非英语国家拍摄的照片的表现如何。我们在这里总结了这些实验的结果,并参考附录了解更多详情。
分析标签预测中的关联。 我们进行了实验,分析了我们的 RegNetY 128GF 主题标签预测模型为包含具有不同明显肤色、明显年龄、明显性别和明显种族的人的照片所做的关联。
实验使用以下方法进行:(1) 包含 178,448 张 Instagram 照片的专有数据集,这些照片使用 Fitzpatrick 肤色量表和 (2) UTK Faces 数据集进行了注释,该数据集提供了表观年龄、表观性别和表观种族标签 。
我们发现该模型已经了解了标签和肤色之间的几种关联;详见附件。例如,#redhead 更常被预测为肤色较浅的人的照片,而#black 更常被预测为肤色较深的人。同样,一些标签预测与照片中人物的表观年龄相关;详见附件。例如,我们的模型更常预测包含 1-10 岁人群的照片#baby 或#kid,更常预测 80-90 岁年龄组的#elder。在分析我们的性别刻板印象模型时,我们发现我们模型的主题标签预测更频繁地将男性与#football 和#basketball 相关联。相比之下,我们的模型更频繁地将包含女性的照片与#makeup 和#bikini 相关联;详见附件。
我们观察到的最令人不安的关联源于对包含不同明显种族的人的照片的模型预测分析。特别是,我们的一些实验表明,我们的模型可能更频繁地将包含黑人的照片与#mugshot 和#prison 相关联;见附录。但是,尚不清楚这些观察结果是否是由于我们的模型对评估数据集中照片的不正确或有偏见的预测所致, 或者它们是否归因于评估数据集包含有问题的有偏见的图像分布。 (不知道是我们的模型出现问题还是数据本身出现问题) 尤其是,更详细的分析揭示了评估数据集(而不是我们的模型)中存在令人不安的偏差:我们发现在UTK Faces数据集中,有很多逮捕照片的图像,其中黑人个体的数量比例相对较高。
总的来说,我们的结果表明,虽然我们的标签预测模型似乎比语言模型做出更少麻烦的预测,但在我们模型的主题标签预测可以用于现实场景之前,需要仔细的分析和调整。受此观察的启发,作为本研究的一部分,我们不会发布模型的最终主题标签预测层。
分析标签预测的公平性。 我们还分析了我们的主题标签预测模型对在世界各地拍摄的照片的处理效果。我们在 Dollar Street 数据集上重复了 [17] 的分析,并对包含数百万张已知原产国图像的专有数据集进行了分析。类似于 [17],我们观察到我们的模型在来自不同国家的 Dollar Street 照片上存在很大的准确性差异。我们对更大、更仔细收集的专有数据集的分析证实了这一结果,但表明效果大小比 [17] 中报告的要小得多;详见附件。具体来说,我们发现每个国家/地区的准确度范围在 ~5% 的相对狭窄范围内,即我们的模型对数据集中所有 15 个国家/地区的每个国家/地区识别准确度都在 65% 到 70% 之间。总的来说,我们的结果表明需要做更多的工作来训练在全球范围内表现平等的模型。在未来的工作中,我们计划训练多语言主题标签模型 [64],因为这可能会导致模型在不同国家/地区实现相同的识别准确度。
6. Discussion
在本文中,我们对图像识别的全监督、自监督和弱监督预训练进行了深入研究。结合相关工作,我们的结果为在视觉感知系统开发中使用弱监督预训练提供了令人信服的论据。然而,我们的研究也揭示了这一研究领域的局限性。
特别是,我们发现越来越难以进行系统的、可控的实验来比较不同的方法和技术。 造成这种情况的原因有很多,包括使用通过不透明流程收集的专有数据、使用的模型架构的多样性、训练方法的复杂性、所使用的硬件和软件平台的异质性、所需的大量计算资源以及并非所有研究都发布预训练模型的事实。 总之,这创造了一种环境,在这种环境中,研究人员无法进行对照研究来测试一个变量的影响,同时保持所有其他变量不变。相反,他们只能进行系统级比较,正如我们在本研究中所做的那样。这种比较提供了各种方法潜力的信号,但它们不会产生决定性的结果。由于我们正在测量的信号很小,在常用的评估数据集上,视觉系统的识别准确率已经达到了一个极限,无法进一步提高。这一事实加剧了这个问题。因此,研究者可能尝试使用各种不同的方法来提高识别准确率,但难以显著地证明一种方法比另一种方法更好。为了创建一个专注于视觉系统大规模学习的繁荣研究社区,我们必须解决这些问题。
这一研究方向的第二个局限性是将识别准确性和推理速度作为主要衡量指标。 虽然识别准确度和推理速度显然很重要,但它们并不是影响视觉感知系统质量的唯一指标。其他衡量标准包括不同用户群体所经历的识别准确性以及强化有害刻板印象的预测的普遍性。 我们在第 5 节中介绍了对此类措施的初步研究,但这种尝试并不完全是决定性的或充分的。特别是,我们发现没有完善的评估数据集和实验方案来促进严格的分析。更糟糕的是,在一些常用的视觉数据集中存在有害的刻板印象(例如我们在 UTK Faces 数据集 [78] 中发现的黑人和被捕照片之间的关联)似乎是未知的。为了让像我们这样的标签预测系统为现实世界的部署做好准备,我们必须提高分析的质量, 并解决这些分析可能出现的任何问题。
最后,我们强调我们仍然相信弱监督学习方法的潜力。如果我们解决了上述问题,我们相信这些方法可以改进视觉感知系统,就像大规模语言模型改进自然语言理解、机器翻译和语音识别一样。















 695
695











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









