







利用级联Softmax和广义大边缘损失训练的改进DCNNs进行细粒度图像分类
Abstract:
我们使用一般的深度卷积神经网络(DCNN)来开发一个细粒度的图像分类器。我们从以下两个方面来提高DCNN模型的细粒度图像分类精度。首先,对给定训练数据集中包含的细粒度图像类的h级层次标签结构进行更好的建模,我们引入h全连通(fc)层来代替给定DCNN模型的顶层fc层,并用级联的softmax损失训练它们。其次,我们提出了一个新的损失函数,即广义大边际损失(GLM),为了使给定的DCNN模型显式地探索细粒度图像类的层次标签结构和相似规律。GLM损失显式地减少了类间相似性和类内方差同时也使得在特征空间中属于同一粗糙类的子类比属于不同粗糙类的子类更加相似。此外,所提出的细粒度图像分类框架是独立的,可以应用于任何DCNN结构。几种通用DCNN模型的综合实验评价(AlexNet、GoogLeNet和VGG)使用三个基准数据集(Stanford car, fine-grained visual classification-aircraft, and CUB-200-2011) 针对精细图像分类任务,验证了该方法的有效性。
1. INTRODUCTION
细粒度图像分类的目的是识别某些基类的下属类,如不同型号的汽车等。细粒度图像分类的挑战主要来自以下两个方面:类间相似性和类内方差,一方面,不同细粒度类之间的视觉差异可能非常小和微妙,另一方面,由于位置、视角、姿势、光照条件等的不同,属于同一细粒度类的实例可能具有明显不同的外观。
对于细粒度图像分类任务,文献中已经提出了许多基于零件的方法[17]-[20]。这些方法首先检测目标对象的不同部分,然后对局部部分的外观进行建模,以增加类间的区分度,同时减少类内的方差。例如,对于细粒度的鸟类分类,Zhang等人[18]提出学习头部、喙部、身体等部位的外观模型,并加强它们之间的几何约束。然而,基于部件的方法依赖于准确的部件检测,这是另一个具有挑战性的问题,可能会在遮挡和较大的视点/姿态变化时失败。此外,零件的检测器通常是在监督的方式下进行训练,这需要足够数量的训练样本。显然,与分配细粒度图像标签相比,对对象部件进行注释要困难得多,成本也高得多。
许多最近的研究工作[4]、[21]-[25]采用新的损失函数训练的深度卷积神经网络(deep convolutional neural networks, DCNNs),如contrastive loss [26]、[27]、triplet
loss [23]等,来学习能够最小化类内方差同时最大化类间距离的特征。然而,当从给定的训练集中构成样本对或样本三个一组时,contrastive和triplet损失的数据急剧膨胀。此外,有报道称,训练样本的成对或三个一组的构成方式会对DCNN模型的性能准确性产生几个百分点的影响,如[23]、[28]。因此,使用这样的损失可能导致模型收敛更慢、计算成本更高、训练复杂性增加和不确定性。
已经有研究工作提出了新的损失函数或专门的CNN架构来利用不同细粒度类之间的标签关系[4], [5],[28], [29] 或探索输入图像的不同部分之间的相关性[11]. 这些方法在各种细粒度图像分类基准数据集上取得了最先进的分类精度。
在本文中,我们使用一个通用的DCNN来开发一个细粒度的图像分类器。我们尝试从以下两个方面来提高DCNN模型的细粒度图像分类精度。首先,为了更好地建模细粒度图像类的h级分级标签结构,我们将给定DCNN模型的顶层全连接(fc)层替换为h级fc层,每个fc层对应于分层标签结构的相应层次。每个h fc层都是其底层和特征输出层的fc,并使用来自相应标签层次结构的标签的softmax loss进行训练。本文将用于训练hfc层的hsoftmax losses称为级联softmax losses。其次,我们提出了一个新的损失函数,即广义大边缘损失(GLM),它明确地探索了细粒度图像类的层次标签结构和相似规律。更具体地说,对于每个给定的细粒度类c,我们将其余的细粒度类分为两组SP©和-SP©,这两组细粒度类分别由与c共享和不共享同一粗粒度(父)类的细粒度类组成。提议的GLM损失明确地实施了这一点:在SP©中,c与最近的细粒度类之间的距离要比c的类内方差大一个预定义的范围,在-SP©中,c与其最近的细粒度类之间的距离要比SP©中c与其最远的细粒度类之间的距离大一个预定义的范围。GLM损失的第一部分旨在使DCNN模型学习能够同时减少类内方差和最大化类间距离的特征,而第二部分则是基于一个常识,即属于同一粗糙类的子类之间应该比属于不同粗糙类的子类之间更相似。由于GLM损耗是可微的,因此可以用标准的反向传播(BP)算法来训练DCNNs。此外,所提出的细粒度图像分类框架是独立的,可以应用于任何DCNN结构。
主要贡献:
- 我们引入了h- fc层来代替给定DCNN模型的顶层fc层,并使用级联的softmax损耗对其进行训练,从而更好地对细粒度图像类的h-level分级标签结构进行建模。
- 我们提出GLM损失,使给定的DCNN模型显式地探索细粒度图像类的层次标签结构和相似规律。
- 使用三个基准数据集对几个通用的DCNN模型进行了综合实验评估,验证了该框架的有效性。
本文的其余部分组织如下。第二部分为相关工作回顾。第三部分介绍了该方法,包括层次标签结构、DCNN修改和级联的softmax损失、GLM损失,以及我们的框架的优化。第四部分为实验评价,第五部分为结论。
III. METHODOLOGY
A. 分级标签结构
在用于细粒度图像分类的典型基准数据集中,根据类标签的语义将它们分组到一个树结构中。图2描述了斯坦福car数据集[1]的两级标签结构,其中叶节点和根节点分别对应细粒度和粗粒度类标签。
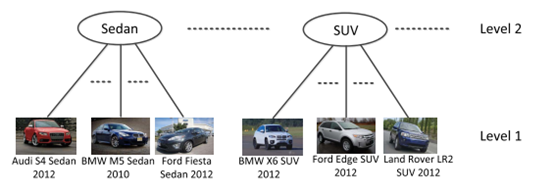
细粒度的类标签表示来自某些汽车制造商的特定模型(如2012年奥迪S4轿车,2010年宝马M5轿车,宝马X6 SUV 2012等),根据体型分为粗类标签。
具有分层标签结构的图像数据集可以用数学方法定义如下。表示由
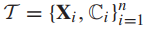 训练样本集,其中
训练样本集,其中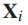 为第i个样本图像,n为训练样本总数。每个示例图像 都与类标签
为第i个样本图像,n为训练样本总数。每个示例图像 都与类标签 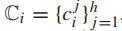 的层次结构相关联,
的层次结构相关联,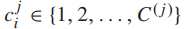 是第j级的类标签,
是第j级的类标签, 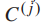 是j级的类数,h是层次标签集合中的层次数。假设细粒度的类标签是第一级类标签,
是j级的类数,h是层次标签集合中的层次数。假设细粒度的类标签是第一级类标签, 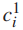 是样本
是样本 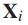 的细粒度类标签,
的细粒度类标签, 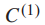 是细粒度类的数量。对于图像
是细粒度类的数量。对于图像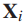 ,我们用
,我们用 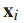 表示DCNN倒数第二层的输出,把
表示DCNN倒数第二层的输出,把 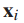 看作是网络提取的
看作是网络提取的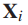 的特征向量。
的特征向量。
提出的细粒度图像分类框架由以下两个主要组件组成:1)修改给定DCNN的网络结构,用级联softmax loss训练它2)开发GLM损失。第II-B-II-D节详细描述了这两个组件。
B. DCNN Modification and Cascaded Softmax Loss
对于带有h级类标签的细粒度图像分类问题,我们修改了给定的DCNN模型,将其顶层fc层替换为h fc层,并使用级联的softmax损耗函数对其进行训练。为了便于解释,同时又不失一般性,我们描述了使用AlexNet[38]对具有两级类标签的图像数据集进行分类的方法。对于其他的细粒度图像分类问题,可以通过类比得到DCNN的修改。
原AlexNet由5个卷积(conv)层(conv1-5)和3个fc层(fc6-8)组成,分别以fc7和fc8作为特征输出层和顶层fc层。对于两层类标签的图像分类,我们将fc8替换为fc8’和fc9,将fc9与fc7和fc8’完全连接起来。我们将从fc7到fc9的连接称为跳过连接见下图:
 将fc8’和fc9中的神经元数量设置为
将fc8’和fc9中的神经元数量设置为 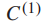 和
和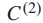 ,给定一个输入图像
,给定一个输入图像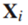 , fc8’和fc9输出所有叶细粒度类标签
, fc8’和fc9输出所有叶细粒度类标签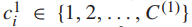 的概率得分
的概率得分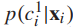 。所有粗类标签
。所有粗类标签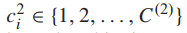 的概率得分
的概率得分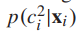 。
。
我们引入了skipping connection (fc7 fc9)来提供粗级别分类层(fc9),该层可以访问所有输入图像Xi细粒度类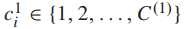 ( fc8’的输出)的学习特性(fc7的输出)和预测概率得分
( fc8’的输出)的学习特性(fc7的输出)和预测概率得分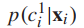 。直观地说,使用上述两种类型的信息进行粗级别分类要优于只使用细粒度级别分类结果的分类,因为前者同时探索这两种语义(即。训练样本的层次标签结构。) 。另一方面,在迭代训练过程中,fc9的预测误差被反向传播到fc8’、fc7以及网络的低层,从而逐步提高了fc8’的预测精度。针对上述修改后的AlexNet,我们将级联的softmax损失应用于训练过程中的fc8’和fc9,定义为
。直观地说,使用上述两种类型的信息进行粗级别分类要优于只使用细粒度级别分类结果的分类,因为前者同时探索这两种语义(即。训练样本的层次标签结构。) 。另一方面,在迭代训练过程中,fc9的预测误差被反向传播到fc8’、fc7以及网络的低层,从而逐步提高了fc8’的预测精度。针对上述修改后的AlexNet,我们将级联的softmax损失应用于训练过程中的fc8’和fc9,定义为
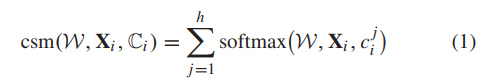
其中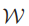 为整个网络的权值参数集。若要用两层类别标签来分类图像,
为整个网络的权值参数集。若要用两层类别标签来分类图像, 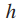 =2,
=2,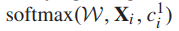 和
和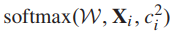 分别应用于fc8’和fc9。应用级联softmax损失可以看作是一种多任务学习,其中一个任务是细粒度的层次分类,另一个任务是粗粒度的层次分类。通过共享这两个任务之间的特征表示,在联合训练[39]的过程中,它们可以逐步互相改进。
分别应用于fc8’和fc9。应用级联softmax损失可以看作是一种多任务学习,其中一个任务是细粒度的层次分类,另一个任务是粗粒度的层次分类。通过共享这两个任务之间的特征表示,在联合训练[39]的过程中,它们可以逐步互相改进。
将修正后的DCNN模型的训练总体目标函数定义为:
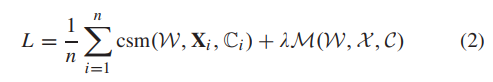
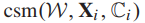 为式(1)中定义的级联softmax损失,
为式(1)中定义的级联softmax损失,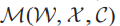 表示要应用到网络特征输出层的GLM损耗(AlexNet的fc7)。
表示要应用到网络特征输出层的GLM损耗(AlexNet的fc7)。
C. Generalized Large-Margin Loss
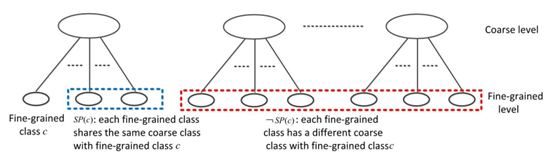
为了简单起见,我们首先推导了2级标签结构的GLM损失,然后将其推广到多个层次。对于每个给定的细粒度类c,我们将其余的细粒度类分为两组SP©和-SP©,这两组细粒度类分别由与c共享和不共享同一父粗粒度类的细粒度类组成。如图5,提出的GLM损失明确地实施了1) 在SP©中最近的细粒度类与c之间的距离要比c的类内距离大一个预定义的margin 2)在 -SP©中,c与其最近的细粒度类之间的距离要比SP©中c与其最远的细粒度类之间的距离大一个预定义的margin。在本节接下来的部分中,我们将首先定义类内方差和类间距离,然后使用这些定义推导出GLM损失。
D. Optimization

算法1我们的框架训练算法如图3所示:
| 输入:训练集T, 超参数λ,α1α2,最大迭代次数 ,计数器iter = 0。 |
|---|
| 输出: |
| 1:从T中选择一个mini-batch。 |
| 2:对每个样本进行正向传播,计算所有层的激活情况。 |
| 3:根据softmax loss (对于粗类)计算fc9的错误流。然后分别通过反向传播计算fc9层的fc7和fc8 '层的误差流。 |
| 4:从softmax loss (用于细粒度类)计算fc8’的错误流。 |
| 5:计算fc8’的总错误流,它是fc9和softmax损失(对于细粒度类)的总和。然后利用BP算法从fc8 '层计算fc7层的误差流。 |
| 6:计算误差流层fc7根据情商GLM的损失。(19)和比例因子λ。 |
| 7:计算fc7层的总误差流,它是fc8’、fc9、GLM损耗的总和。 |
| 8:将fc7层反向传播到conv1层,利用BP算法依次计算各层的误差流。 |
| 9:根据各层的激活和错误流,用BP算法计算 。 |
| 10:用梯度下降算法更新 。 |
| 11: iter←iter + 1。如果 ,执行步骤1。 |
论文连接
DCNNs Trained by Cascaded Softmax and Generalized Large-Margin Losses
















 3万+
3万+











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











