










 本文介绍了L-Softmax损失函数,这是一种改进的Softmax损失函数,能够引导卷积神经网络学习到更具区分性的特征。文章详细阐述了L-Softmax的工作原理,包括如何通过增加间隔来提高特征的类间距离并减小类内距离,进而提升分类性能。
本文介绍了L-Softmax损失函数,这是一种改进的Softmax损失函数,能够引导卷积神经网络学习到更具区分性的特征。文章详细阐述了L-Softmax的工作原理,包括如何通过增加间隔来提高特征的类间距离并减小类内距离,进而提升分类性能。
参考文献: Liu W, Wen Y, Yu Z, et al. Large-Margin Softmax Loss for Convolutional Neural Networks[C]//Proceedings of The 33rd International Conference on Machine Learning. 2016: 507-516.
摘要
Softmax Loss 函数经常在卷积神经网络被用到,较为简单实用,但是它并不能够明确引导网络学习区分性较高的特征。这篇文章提出了large-marin softmax (L-Softmax) loss, 能够有效地引导网络学习使得类内距离较小、类间距离较大的特征。同时,L-Softmax不但能够调节不同的间隔(margin),而且能够防止过拟合。可以使用随机梯度下降法推算出它的前向和后向反馈,实验证明L-Softmax学习出的特征更加有可区分性,并且在分类和验证任务上均取得比softmax更好的效果。
算法介绍
1. Softmax Loss回顾
在介绍L-Softmax之前,我们先来回顾下softmax loss。当定义第
i
个输入特征
其中 fj 表示最终全连接层的类别输出向量 f 的第 j 个元素,
其中 0≤θj≤π 。 虽然softmax在深度卷积神经网络中有着广泛的应用,但是这种形式并不能够有效地学习得到使得类内较为紧凑、类间较离散的特征。
2. 动机
初始的softmax的目的是使得
WT1x>WT2x
,即
∥W1∥∥x∥cos(θ1)>∥W2∥∥x∥cos(θ2)
,从而得到
x
(来自类别1)正确的分类结果。作者提出large-magrin softmax loss的动机是希望通过增加一个正整数变量
m
,从而产生一个决策余量,能够更加严格地约束上述不等式,即:
其中 0≤θ1<πm 。如果 W1 和 W2 能够满足 ∥W1∥∥x∥cos(mθ1)>∥W2∥∥x∥cos(θ2) ,那么就必然满足 ∥W1∥∥x∥cos(θ1)>∥W2∥∥x∥cos(θ2) 。这样的约束对学习 W1 和 W2 的过程提出了更高的要求,从而使得1类和2类有了更宽的分类决策边界。
(其实说白了,基于softmax loss学习同类和不同类样本时,都用的是同一种格式,因此学习到的特征的类内和类间的可区分性不强。而这篇论文是在学习同类样本时,特意增强了同类学习的难度,这个难度要比不同类的难度要大些。这样的区别对待使得特征的可区分性增强。感觉就像是管孩子,对自己家的孩子严一些,对别人家的孩子宽容些,哈哈)
Large-Margin Softmax Loss
按照上节的思路,L-Softmax loss可写为:
在这里,
ψ(θ)
可以表示为:
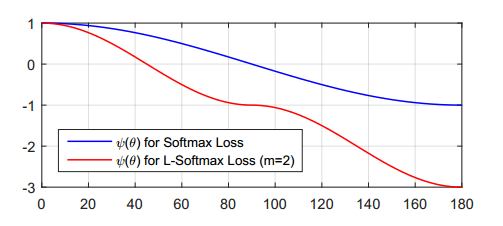
当 m 越大时,分类的边界越大,学习难度当然就越高。同时,公式中的
作者为了能够简化前向和后向传播,构建了这样一种函数形式
ψ(θ)
:
其中 k 是一个整数且
再使用
WTjxi∥Wj∥∥xi∥
替代
cos(θj)
, 以及将
cos(mθyi)
替换为
cos(θyi)
和
m
的函数(论文中已交待,太长,我就不敲上去了),这样,最终的L-Softmax loss 函数就可以分别对
简单分析
为了简单明了地表明L-Softmax Loss的有效性,作者讨论了一个二分类问题,只包含 W1 和 W2 。分析结果如下图所示。
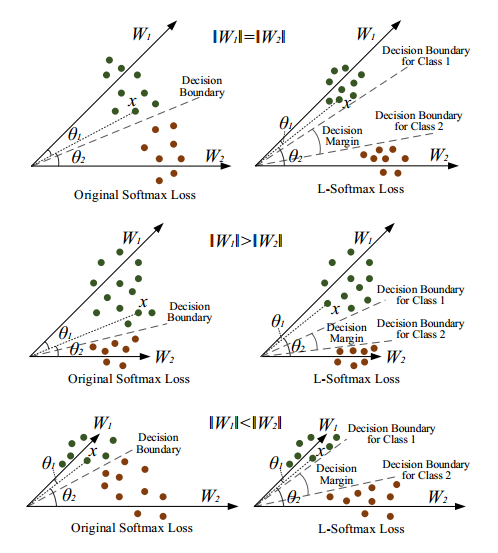
在训练过程中,当 W1=W2 时,softmax loss 要求 θ1<θ2 , 而 L-Softmax则要求 mθ1<θ2 ,我们从图中可以看到L-Softmax得到了一个更严格的分类标准。当 W1>W2 和 W1<W2 时,虽然情况会复杂些,但是同样可以看到L-Softmax会产生一个较大的决策余量。
实验结果
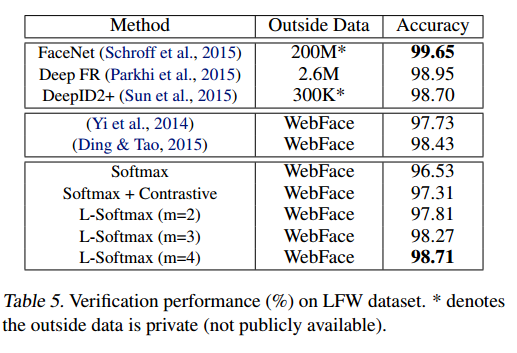
作者分别使用分类和人脸验证对softmax loss 和L-Softmax Loss进行了对比。在分类问题中,采用了MNIST, CIFAR10以及CIFAR100三个数据集进行评测,而人脸验证则采用了LFW进行验证。
最后的结果是L-Softmax Loss均取得了更好的效果,而且当
m
越大时,最终的结果会越好。特别值得一提的是,作者仅使用了 WebFace的人脸数据作为训练集和一个较小的卷积网络,就在LFW上达到了98.71%的正确率。
总结
L-Softmax Loss有一个清楚的几何解释,并且能够通过设置
PS: 有同学已经开始使用L-Softmax Loss,不过反映训练难度比较大,需要反复调参。等有空了我也来试试。深度学习的东西我研究的时间也不是很长,一些东西没有理解到位。错误在所难免,欢迎拍砖。

















 413
413

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









