









Five methods of Normalization: BN,LN,IN,GN,SN
1. 介绍
深度网络参数训练时内部存在 协方差偏移(Internal Covariate Shift) 现象:深度网络内部数据分布在训练过程中发生变化的现象。
为什么会带来不好影响: 训练深度网络时,神经网络隐层参数更新会导致网络输出层输出数据的分布发生变化,而且随着层数的增加,根据链式规则,这种偏移现象会逐渐被放大。这对于网络参数学习来说是个问题:因为神经网络本质学习的就是数据分布(representation learning),如果数据分布变化了,神经网络又不得不学习新的分布。
归一化流程
- 计算出均值
- 计算出方差
- 归一化处理到均值为0,方差为1
- 变化重构,恢复出这一层网络所要学到的分布
μ B ← 1 m ∑ i = 1 m x i σ B 2 ← 1 m ∑ i = 1 m ( x i − μ B ) 2 x ^ i ← x i − μ B σ B 2 + ϵ y i ← γ x ^ i + β ≡ B N γ , β ( x i ) \begin{aligned} \mu_{\mathcal{B}} & \leftarrow \frac{1}{m} \sum_{i=1}^{m} x_{i} \\ \sigma_{\mathcal{B}}^{2} & \leftarrow \frac{1}{m} \sum_{i=1}^{m}\left(x_{i}-\mu_{\mathcal{B}}\right)^{2} \\ \widehat{x}_{i} & \leftarrow \frac{x_{i}-\mu_{\mathcal{B}}}{\sqrt{\sigma_{\mathcal{B}}^{2}+\epsilon}} \\ y_{i} & \leftarrow \gamma \widehat{x}_{i}+\beta \equiv \mathrm{BN}_{\gamma, \beta}\left(x_{i}\right) \end{aligned} μBσB2x iyi←m1i=1∑mxi←m1i=1∑m(xi−μB)2←σB2+ϵxi−μB←γx i+β≡BNγ,β(xi)
2. Batch Normalization
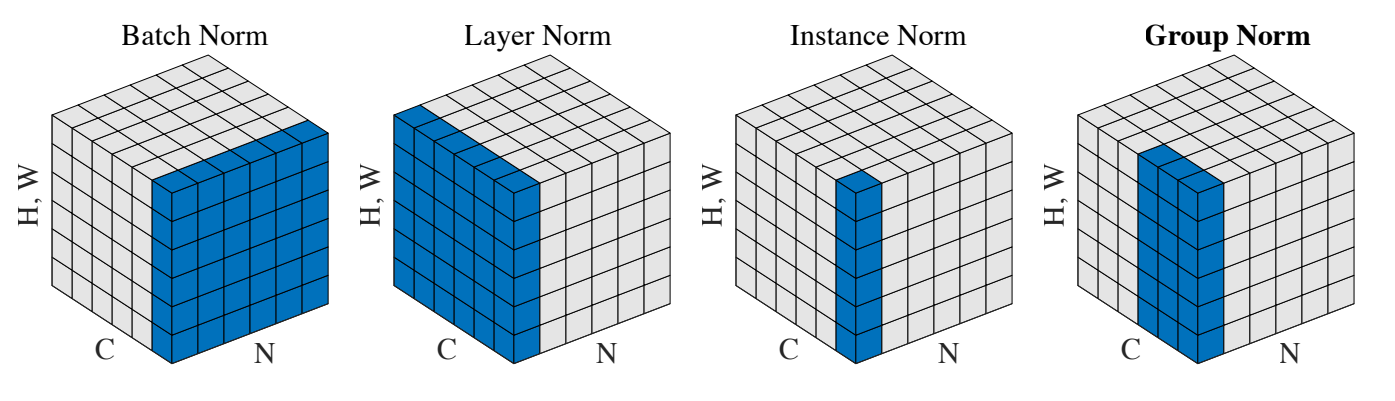
BN对一个Batch所有样本同一个Channel上的feature进行标准化,即对每一个通道的 N × [ H , W ] N\times [H,W] N×[H,W] 进行归一化。- 对于每一个
Channel都有一组参数 γ , β \gamma, \beta γ,β ,所以需要学习的参数为 2 × C 2\times C 2×C 。 - 当
batch size越小,BN的表现效果也越不好,因为计算过程中所得到的均值和方差不能代表全局。
训练的时候,根据输入的每一批数据来计算均值和方差;测试的时候,对于均值来说直接计算所有训练时 batch 均值的平均值,然后对于标准偏差采用每个batch方差的无偏估计。
E
[
x
]
←
E
B
[
μ
B
]
Var
[
x
]
←
m
m
−
1
E
B
[
σ
B
2
]
\begin{aligned} \mathrm{E}[x] & \leftarrow \mathrm{E}_{\mathcal{B}}\left[\mu_{\mathcal{B}}\right] \\ \operatorname{Var}[x] & \leftarrow \frac{m}{m-1} \mathrm{E}_{\mathcal{B}}\left[\sigma_{\mathcal{B}}^{2}\right] \end{aligned}
E[x]Var[x]←EB[μB]←m−1mEB[σB2]
a. BN 的优点
- 加快网络的训练和收敛的速度:在深度神经网络中中,如果每层的数据分布都不一样的话,将会导致网络非常难收敛和训练,而如果把 每层的数据都在转换在均值为零,方差为1 的状态下,这样每层数据的分布都是一样的训练会比较容易收敛。
- 控制梯度爆炸,防止梯度消失:以
sigmoid函数为例,sigmoid函数使得输出在[0,1]之间,实际上当x增加到了一定的大小,sigmoid函数的梯度就会饱和。 - 防止过拟合:在网络的训练中,
BN的使用使得一个batch中所有样本都被关联在了一起,因此网络不会从某一个训练样本中生成确定的结果,即同样一个样本的输出不再仅仅取决于样本的本身,也取决于跟这个样本同属一个batch的其他样本,而每次网络都是随机取batch,这样就会使得整个网络不会朝这一个方向使劲学习。一定程度上避免了过拟合。
b. BN 的缺点
- 高度依赖于
batch的大小,实际使用中会对batch大小进行约束,不适合类似在线学习(batch为1)。 - 不适用于
RNN网络中normalize操作,BN实际使用时需要计算并且保存某一层神经网络batch的均值和方差等统计信息,对于对一个固定深度的前向神经网络(DNN,CNN)使用BN,很方便;但对于RNN来说,sequence的长度是不一致的,换句话说RNN的深度不是固定的,不同的time-step需要保存不同的statics特征,可能存在一个特殊sequence比其的sequence长很多,这样training时,计算很麻烦。
3. Layer Normalization
LN对同一个样本的所有Channel上的feature进行标准化,即对同一个样本的 C × [ H , W ] C\times [H,W] C×[H,W] 进行归一化。- 常用在 RNN,Transformer 网络,但如果输入的特征区别很大,那么就不建议使用它做归一化处理。
a. LN 的优点
LN得到的模型更稳定;LN有正则化的作用,得到的模型更不容易过拟合。
4. Instance Normalization
- IN 对每个 [ H , W ] [H,W] [H,W] 单独进行归一化处理,不受 channel 和 batch size 的影响。
- 常用在风格化迁移,但如果特征图可以用到通道之间的相关性,那么就不建议使用它做归一化处理。
a. IN 的优点
- 在图片视频分类等特征提取网络中大多数情况
BN效果优于IN,在生成式类任务中的网络IN优于BN。
5. Group Normalization
-
GN的计算就是把先把通道C分成G组,然后把每个 g × [ H , W ] g\times [H,W] g×[H,W] 单独拿出来归一化处理,最后把G组归一化之后的数据合并成 C × [ H , W ] C\times [H,W] C×[H,W] 。 -
GN介于LN和IN之间,当然可以说LN和IN就是GN的特列,比如G的大小为1或者为C。 -
Vision Transformer的Hybrid Model中的ResNet用的就是Group Normalization。
a. GN 的优点
GN的归一化方式避开了batch size对模型的影响,特征的group归一化同样可以解决 I n t e r n a l Internal Internal C o v a r i a t e Covariate Covariate S h i f t Shift Shift的问题,并取得较好的效果。
6. Switchable Normalization
1.将 BN、LN、IN 结合,赋予权重,让网络自己去学习归一化层应该使用什么方法 。
2.集万千宠爱于一身,但训练复杂 。
7. Weight Normalization
Weight Normalization is a normalization method for training neural networks. It is inspired by batch normalization, but it is a deterministic method that does not share batch normalization’s property of adding noise to the gradients. It reparameterizes each weight vector
w
\mathbf{w}
w in terms of a parameter vector
v
\mathbf{v}
v and a scalar parameter
g
g
g and to perform stochastic gradient descent with respect to those parameters instead. Weight vectors are expressed in terms of the new parameters using:
w
=
g
∥
v
∥
v
\mathbf{w}=\frac{g}{\|\mathbf{v}\|} \mathbf{v}
w=∥v∥gv
where
v
\mathbf{v}
v is a
k
k
k-dimensional vector,
g
g
g is a scalar, and
∥
v
∥
\|\mathbf{v}\|
∥v∥ denotes the Euclidean norm of
v
\mathbf{v}
v. This reparameterization has the effect of fixing the Euclidean norm of the weight vector w: we now have
∥
w
∥
=
g
\|\mathbf{w}\|=g
∥w∥=g, independent of the parameters
v
\mathbf{v}
v.
更多的 Normalization 方法可以查看 papers with code 的专题。
参考资料














 2154
2154











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









