






C++实现K-Means算法
该算法的原理主要是随机选取 K 个数据作为初始数据,之后不断经行迭代更新数据直到最终结果不变为止,数据集用的是python的鸢尾花数据集这里直接给出算法的伪代码:

这个伪代码就是机器学习西瓜书里的那个伪代码,我也是按照这个伪代码来写的,接下来就直接给上c++代码。
#include<iostream>
#include<vector>
#include<algorithm>
#include<string>
#include<sstream>
#include<fstream>
#include<map>
#include <numeric>
#include <windows.h>
#include <istream>
#include <algorithm>
#include <random>
#include <chrono>
#include<windows.h>
using namespace std;
//模板函数,将string类型的字符串转化为数字
template <class Type>
Type stringToNum(const string& str)
{
istringstream iss(str);
Type num;
iss >> num;
return num;
}
//K-means均值算法
class KMeans
{
public:
KMeans() {};
~KMeans() {};
void GetData(); //获取数据
void keamsstart(int K); //启动函数
vector<double> GetAvg(vector<vector<double>> v);
double GetDistance(const vector<double> &a, const vector<double> &b); //二范数距离
bool Compare(vector<vector<double>> Judge_Data, vector<vector<double>> Judge_Data2);
private:
map<vector<double>, string>::iterator iter;
map<vector<double>, string> All_data; //保存所有提取出来的数据
map<vector<double>, string>Rand_data;//保存随机选取的数据
vector<vector<double>> Judge_Data; //保存计算结果的二维向量
vector<vector<double>> Judge_Data2;//保存计算结果的二维向量
map<int, map<vector<double>, string>> Result; //保存分类结果的map
};
//从CSV文件里提取数据
void KMeans::GetData()
{
ifstream file;
string line;
file.open("iris.csv", ios::in);
if (file.fail()) {
cout << "文件打开失败" << endl;
return;
}
while (getline(file, line))
{
stringstream ss(line);
string str;
vector<string>v;
vector<double> d;
//cout << line << endl;
while (getline(ss, str, ','))
{
//cout << str << endl;
v.push_back(str);
}
for (int i = 1; i < 5; i++)
{
d.push_back(stringToNum<double>(v[i]));
}
All_data[d] = v[5];
}
}
//获得两个向量之间的二范数
double KMeans::GetDistance(const vector<double> &a, const vector<double> &b)
{
double sum = 0;
for (int i = 0; i < a.size(); i++)
{
sum += (a[i] - b[i])*(a[i] - b[i]);
}
return sqrt(sum);
}
//计算均值
vector<double> KMeans::GetAvg(vector<vector<double>> v)
{
vector<double> temp;
for (int i = 0; i < 4; i++)
{
double sum = 0;
for (int j = 0; j < v.size(); j++)
{
sum += v[j][i];
}
temp.push_back(sum / v.size());
}
return temp;
}
//判断聚类结果是否一致如果是一致的表明迭代结束返回False
bool KMeans::Compare(vector<vector<double>> Judge_Data, vector<vector<double>> Judge_Data2)
{
for (int i = 0; i < Judge_Data.size(); i++)
{
for (int j = 0; j < Judge_Data[i].size(); j++)
{
if (Judge_Data[i][j] != Judge_Data2[i][j])
{
return true;
break;
}
}
}
return false;
}
void KMeans::keamsstart(int K)
{
vector<int>numbers;
int flag = 0;
int flag1 = 0;
//打乱序列,取随机向量
for (int i = 0; i < All_data.size(); i++)
{
numbers.push_back(i);
}
unsigned seed = std::chrono::system_clock::now().time_since_epoch().count();
shuffle(numbers.begin(), numbers.end(), std::default_random_engine(seed));
sort(numbers.begin(), numbers.begin() + K);
for (iter=All_data.begin();iter!=All_data.end();iter++)
{
if (flag == numbers[flag1])
{
flag1++;
Rand_data[iter->first] = iter->second;
if (flag1 == K) break;
}
flag++;
}
vector<double> xData;
for (map<vector<double>, string>::iterator iter2 = Rand_data.begin(); iter2 != Rand_data.end(); iter2++)
{
xData = iter2->first;
Judge_Data.push_back(xData);
}
for (; ;) //比较均值向量前后是否相等
{
vector<double> dis, Sample;
//计算样本与各初始向量之间的距离,并进行分组
for (iter = All_data.begin(); iter != All_data.end(); iter++)
{
Sample = iter->first;
for (int i = 0; i < Judge_Data.size(); i++)
{
double distance = GetDistance(Sample, Judge_Data[i]);
dis.push_back(distance);
}
int minPosition = min_element(dis.begin(), dis.end()) - dis.begin();
Result[minPosition][Sample] = iter->second;
dis.clear();
}
//计算分组后的均值
for (int i = 0; i < K; i++)
{
vector<double> temp;
vector<vector<double>> t;
for (iter = Result[i].begin(); iter != Result[i].end(); iter++)
{
temp = iter->first;
t.push_back(temp);
}
temp.clear();
temp = GetAvg(t);
Judge_Data2.push_back(temp);
}
if (!Compare(Judge_Data, Judge_Data2)) break;
Judge_Data = Judge_Data2; //为下次判断做准备
Judge_Data2.clear();
Result.clear();
}
//打印我们的数据,查看分类结果
for (int i = 0; i < K; i++)
{
cout << "第" << i << "聚类 : " << endl;
for (iter = Result[i].begin(); iter != Result[i].end(); iter++)
{
vector<double> test = iter->first;
for (int j = 0; j < test.size(); j++)
{
cout << test[j] << " ";
}
cout << iter->second << endl;
}
}
}
int main()
{
//计算程序所用时间 结果大概在2ms - 4ms
double run_time;
_LARGE_INTEGER time_start; //开始时间
_LARGE_INTEGER time_over; //结束时间
double dqFreq; //计时器频率
LARGE_INTEGER f; //计时器频率
QueryPerformanceFrequency(&f);
dqFreq = (double)f.QuadPart;
QueryPerformanceCounter(&time_start); //计时开始
KMeans k;
k.GetData();
k.keamsstart(3);
QueryPerformanceCounter(&time_over); //计时结束
run_time = 1000000 * (time_over.QuadPart - time_start.QuadPart) / dqFreq;
//乘以1000000把单位由秒化为微秒,精度为1000 000/(cpu主频)微秒
printf("\nrun_time:%fus\n", run_time);
return 0;
}
来看一下最终的结果:
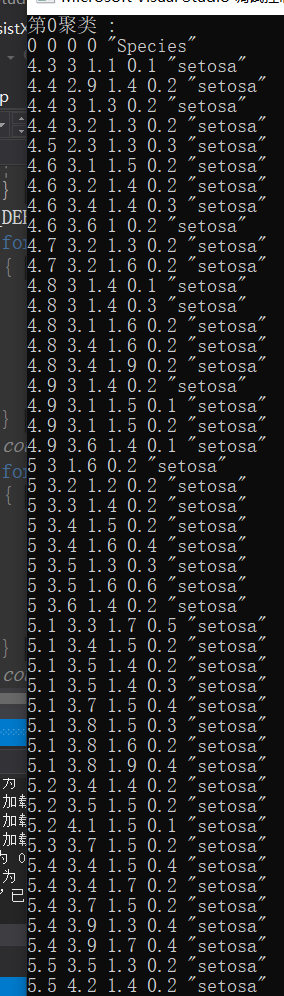
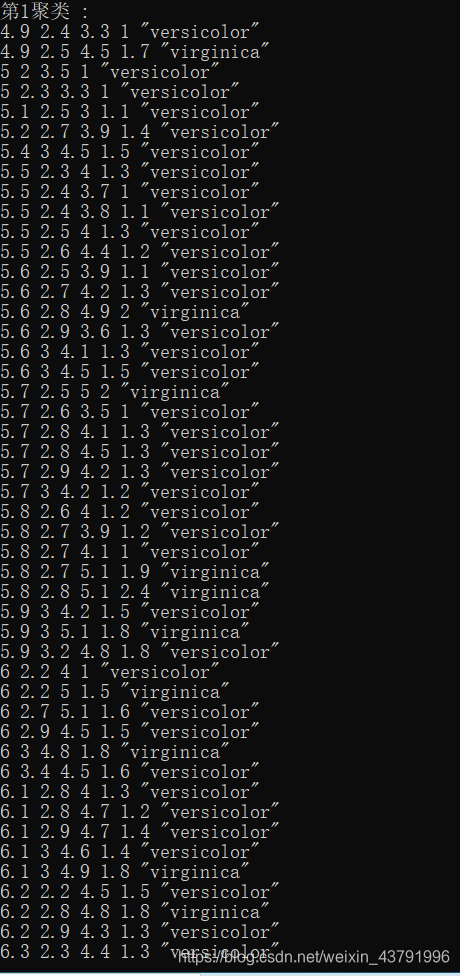
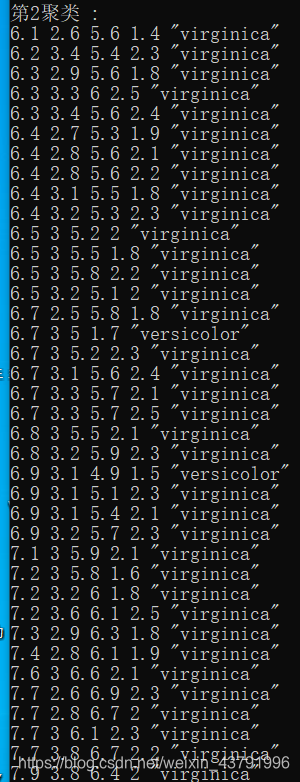

最终时间是42ms,这是包含了打印数据的时间,实际时间大约在1ms-2ms,因为数据具有随机性,所以用时也会不同。与python的sklearn库自带的kmans算法相比,快10倍左右。














 1769
1769











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









