import pandas as pd
import numpy as np
import matplotlib.pyplot as plt
from pandas.plotting import scatter_matrix
%matplotlib inline
housing_data = pd.read_csv("datasets/housing/housing.csv")
'''housing_data.hist(bins=50, figsize=(20, 15))
plt.show()'''
attributes = ["median_house_value", "median_income", "total_rooms", "housing_median_age"]
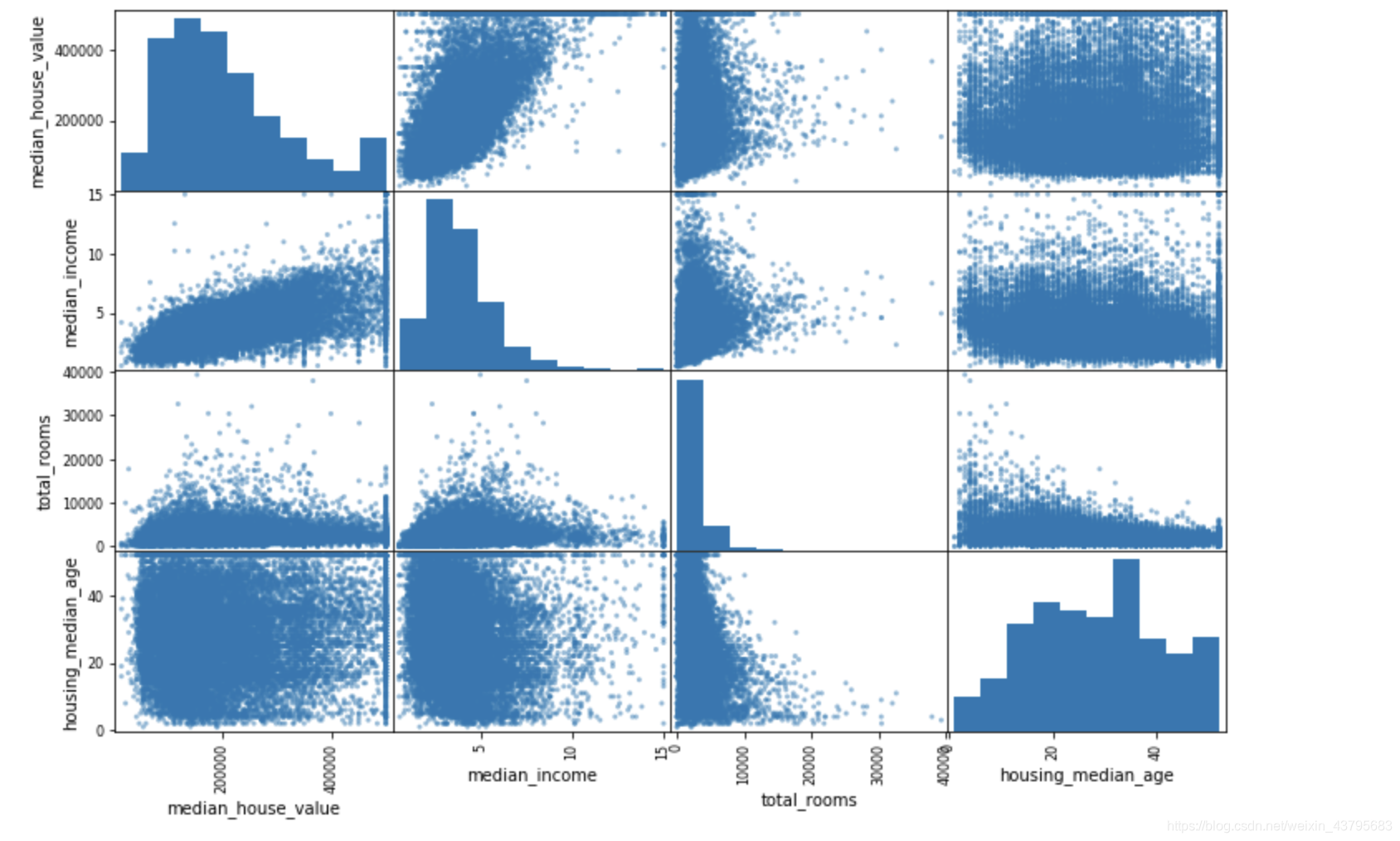
scatter_matrix(housing_data[attributes], figsize=(12, 8))
plt.show()
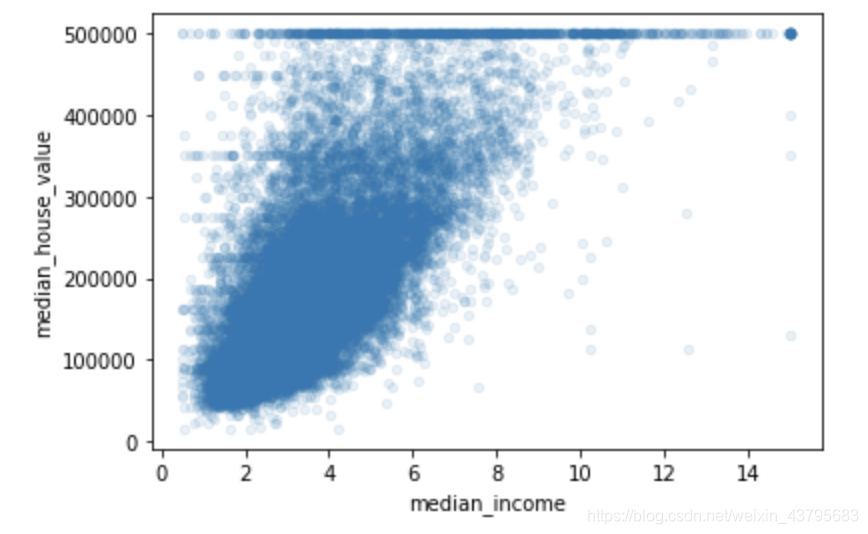
housing_data.plot(kind="scatter",x="median_income",y="median_house_value",alpha=0.1)
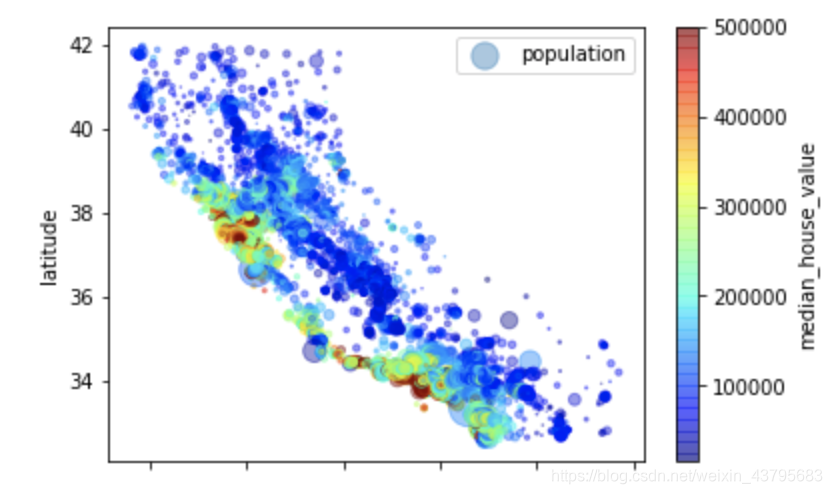
housing_data.plot(kind="scatter", x="longitude", y="latitude", alpha=0.4,
s=housing_data["population"]/100, label="population",
c="median_house_value", cmap=plt.get_cmap("jet"), colorbar=True)
plt.legend()
plt.show()
import numpy as np
from sklearn.model_selection import StratifiedShuffleSplit
housing_data["income_cat"] = np.ceil(housing_data["median_income"]/1.5)
housing_data["income_cat"].where(housing_data["income_cat"] < 5, 5.0, inplace=True)
split = StratifiedShuffleSplit(n_splits=1,test_size=0.2, random_state=42)
for train_index, test_index in split.split(housing_data, housing_data["income_cat"]):
strat_train_set = housing_data.loc[train_index]
strat_test_set = housing_data.loc[test_index]
housing_data = strat_train_set.drop("median_house_value",axis=1)
housing_label = strat_train_set["median_house_value"].copy()
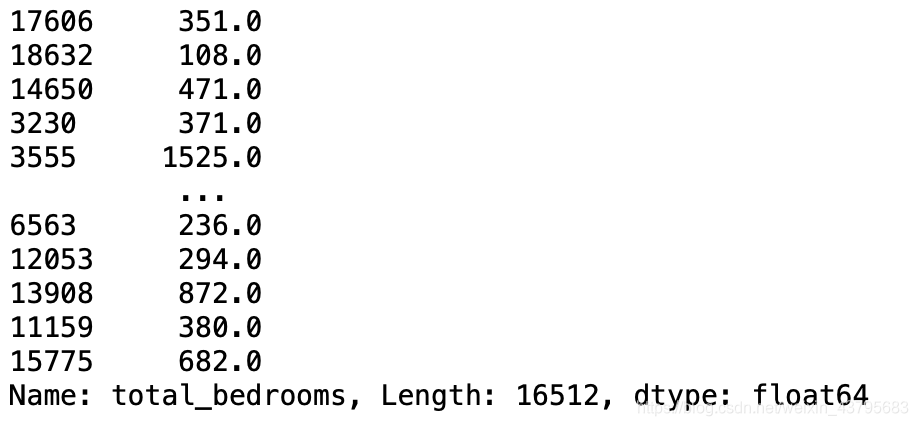
housing.dropna(subset=["total_rooms"])
housing.drop("total_bedrooms",axis=1)
median = housing["total_bedrooms"].median()
housing["total_bedrooms"].fillna(median)
from sklearn.impute import SimpleImputer
SimpleImputer = SimpleImputer(strategy = "median")
housing_sum=housing_data.drop(["ocean_proximity"],axis=1)
SimpleImputer.fit(housing_sum)
SimpleImputer.statistics_
X = SimpleImputer.transform(housing_sum)
housing_tr=pd.DataFrame(X,columns=housing_sum.columns)
from sklearn.preprocessing import LabelEncoder
from sklearn.preprocessing import LabelBinarizer
encoder = LabelBinarizer(sparse_output=True)
housing_cat = housing_data["ocean_proximity"]
housing_cat_1hot = encoder.fit_transform(housing_cat)
housing_cat_1hot
from sklearn.base import BaseEstimator,TransformerMixin
rooms_ix,bedrooms_ix,population_ix,household_ix = 3,4,5,6
class CombinedAttributesAdder(BaseEstimator,TransformerMixin):
def __init__(self,add_bedrooms_per_room=True):
self.add_bedrooms_per_room=add_bedrooms_per_room
def fit(self,X,y=None):
return self
def transform(self,X,y=None):
rooms_per_household=X[:,rooms_ix]/X[:,household_ix]
population_per_household=X[:,population_ix]/X[:,household_ix]
if self.add_bedrooms_per_room:
bedrooms_per_room=X[:,bedrooms_ix]/X[:,rooms_ix]
return np.c_[X,rooms_per_household,population_per_household,bedrooms_per_room]
else:
return np.c_[X,rooms_per_household,population_per_household]
attr_adder = CombinedAttributesAdder(add_bedrooms_per_room=False)
housing_extra_attribs=attr_adder.transform(housing_data.values)
from sklearn.pipeline import Pipeline
from sklearn.preprocessing import StandardScaler
from sklearn.base import BaseEstimator,TransformerMixin
class DataFrameSelector(BaseEstimator,TransformerMixin):
def __init__(self,attribute_names):
self.attribute_names=attribute_names
def fit(self,X,y=None):
return self
def transform(self,X):
return X[self.attribute_names].values
from sklearn.pipeline import FeatureUnion
from sklearn.impute import SimpleImputer
from sklearn.base import TransformerMixin
class MyLabelBinarizer(TransformerMixin):
def __init__(self, *args, **kwargs):
self.encoder = LabelBinarizer(*args, **kwargs)
def fit(self, x, y=0):
self.encoder.fit(x)
return self
def transform(self, x, y=0):
return self.encoder.transform(x)
num_attribs = list(housing_sum)
cat_attribs = ["ocean_proximity"]
num_pipeline = Pipeline([
('selector',DataFrameSelector(num_attribs)),
('imputer', SimpleImputer(strategy="median")),
('attribs_adder',CombinedAttributesAdder()),
('std_scaler',StandardScaler())
])
cat_pipeline = Pipeline([
('selector',DataFrameSelector(cat_attribs)),
('label_binarizer',MyLabelBinarizer()),
])
full_pipeline=FeatureUnion(transformer_list=[
("num_pipeline",num_pipeline),
("cat_pipeline",cat_pipeline),
])
housing_prepared = full_pipeline.fit_transform(housing_data)
from sklearn.ensemble import RandomForestRegressor
forest_reg = RandomForestRegressor()
forest_reg.fit(housing_prepared,housing_label)
from sklearn.metrics import mean_squared_error
housing_predictions = forest_reg.predict(housing_prepared)
forest_mse=mean_squared_error(housing_label,housing_predictions)
forest_rmse=np.sqrt(forest_mse)
forest_rmse
from sklearn.model_selection import cross_val_score
scores = cross_val_score(forest_reg,housing_prepared,housing_label,scoring="neg_mean_squared_error",cv=10)
rmse_scores=np.sqrt(-scores)
def display_scores(scores):
print("Scores",scores)
print("Mean:",scores.mean())
print("Standard deviation:",scores.std())
display_scores(rmse_scores)

from sklearn.model_selection import GridSearchCV
param_grid = [
{'n_estimators':[3,10,30],'max_features':[2,4,6,8]},
{'bootstrap':[False],'n_estimators':[3,10],'max_features':[2,3,4]},
]
forest_reg=RandomForestRegressor()
grid_search=GridSearchCV(forest_reg,param_grid,cv=5,scoring='neg_mean_squared_error')
grid_search.fit(housing_prepared,housing_label)
grid_search.best_params_
grid_search.best_estimator_
cvres=grid_search.cv_results_
for mean_score,params in zip(cvres["mean_test_score"],cvres["params"]):
print(np.sqrt(-mean_score),params)
feature_importances = grid_search.best_estimator_.feature_importances_
feature_importances
extra_attribs=["room_per_hhold","pop_per_hhold","bedrooms_per_room"]
cat_one_hot_attribs = list(encoder.classes_)
attributes = num_attribs + extra_attribs + cat_one_hot_attribs
sorted(zip(feature_importances,attributes),reverse=True)
final_model = grid_search.best_estimator_
X_test = strat_test_set.drop("median_house_value",axis=1)
Y_test = strat_test_set["median_house_value"].copy()
X_test_prepared=full_pipeline.transform(X_test)
final_predictions=final_model.predict(X_test_prepared)
final_mse=mean_squared_error(Y_test,final_predictions)
final_rmse=np.sqrt(final_mse)
final_rmse








 本文通过使用随机森林回归模型对房价进行预测,详细介绍了数据预处理、特征工程和模型训练的过程。通过对数据集的深入分析,采用特征组合、缺失值处理和标准化等手段,提高了模型的预测准确性。
本文通过使用随机森林回归模型对房价进行预测,详细介绍了数据预处理、特征工程和模型训练的过程。通过对数据集的深入分析,采用特征组合、缺失值处理和标准化等手段,提高了模型的预测准确性。


















 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









