







目录
2.1快速入门
pandas是Python的核心数据分析库,强大,灵活,可以支持任何语言的开源数据包。简单直观的处理关系型和标记型数据。pandas速度很快,很多底层的算法都是用Cython优化过的。pandas处理以下类型的数据:
- 与 SQL 或 Excel 表类似的,含异构列的表格数据;
- 有序和无序(非固定频率)的时间序列数据;
- 带行列标签的矩阵数据,包括同构或异构型数据;
- 任意其它形式的观测、统计数据集, 数据转入 Pandas 数据结构时不必事先标记。
pandas主要的数据结构是Series和DataFrame,这两种数据结构足以处理金融,统计和社会科学以及工程等领域里的大多数典型用例。适用于:
- 可以处理SQL,Excel类似的表格数据
- 有序和无序的时间 序列数据
- 带标签的矩阵数据
导包方式
from pandas import Series,DataFrame
import pandas as pd
import numpy as npPandas和SQL的比较:
- selec---切片
- from---join、merge、concat、append
- where---query
- group by--groupby
- having---apply()、transform、max等
- order by--sort——values()、sort_index()
2.2 Series
2.2.1基本知识
Series就是一个定长的有序字典,通过shape、size、index、value等得到相关属性。
2.2.1.1属性:
- s.size:获取大小
- s.shape:获取形状
- s.index:获取索引
- s.values:获取值
- s.name:对象的名字
2.2.1.2方法
- s.head() # 获取前5个数据
- s.tail() # 获取后5个数据
2.2.1.3缺失值的检测
当索引没有对应的值时,可能出现缺失数据的情况,显示NaN.Python自带检测方式:
- s.isnull()
- s.notnull()
检测是否有缺失值,pandas自带的
- pd.isnull(s)
- pd.notnull(s)
2.2.2Series的创建
2.2.2.1列表方式的创建
pd1=pd.Series(
data=['关羽','张飞','赵云','韩信'],
index=list('abcd'),
name='三国',
)2.2.2.2字典方式创建
df1=pd.Series({'name':'Marry','age':22,'gender':'male'})2.2.3切片和索引
2.2.3.1索引
- s.loc['index']根据索引进行获取,与s['索引']具有相同的功能.
- s.iloc[行号]根据行号进行获取,与s[0]具有相同的功能
2.2.3.2切片
- s.loc['a':'c']根据index进行的切片,与s['a':'c']具有相同的功能.
- s.iloc[1:3]根据行号进行切片,与s[1:3]具有相同的功能
注意:iloc是通过隐式索引和切片进行数据的获取的,而loc是通过显式索引进行数据的获取的,而普通的方括号,无论是显式索引还是隐式索引都是可以的.
2.2.4Series的运算
1.加法运算
适用于numpy中的运算在Series中也是适用的,Series之间的运算在运算中自动对齐不同索引的数据,如果索引不对应,那么就补NaN。
a={
'username':'gfb',
'age':22,
'u_id':'201607020101'
}
b={
'username':'txl',
'age':22,
'gender':'female'
}
A=pd.Series(a)
B=pd.Series(b)
C=A+B
display(C)
age 44
data NaN
gender NaN
u_id NaN
username gfbtxl
dtype: object结论:使用加号运算
- a有值b没有值那么返回NaN
- a和b都有值,如果是字符串则拼接,如果是数值类型那么相加
- 如果我们想要将合并的空值填充,可以使用A.add(B,fill_value=0)进行运算.
2.Series、numpy、list互转
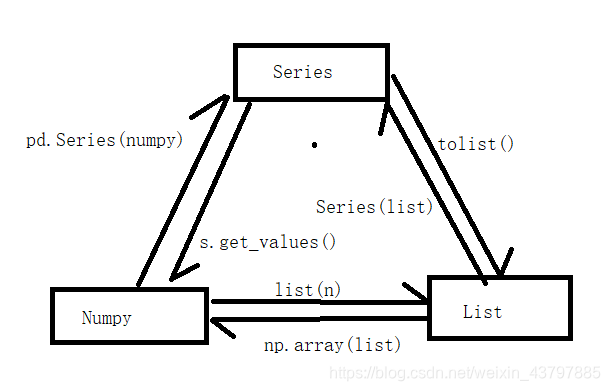
3.Series的广播运算
s[::2]+10和s[::2].add(10)具有相同的功能
4.提取满足条件的值
s=pd.Series([1,2,3,4])
cond=s<3
s[cond]5.常用函数
- s.mean() 均值
- s.median() 中位数
- s.count() 统计计数
- s.argmax() 取出最大值的下标
- s.idxmax() 取出最大值的下标
- s.add_prefix('pre_') 为索引添加前缀
- s.add_suffix('_suf') 为索引添加后缀
2.3DataFrame
2.3.1创建
矩阵方式创建
df=DataFrame(
data=np.random.randint(0,150,size=(10,4)),
index=list('abcdefhijk'),
columns=['Python','Java','C++','C'],
dtype=np.int16,
copy=True
)字典方式创建
dict1={
'姓名':['关羽','张飞','曹操'],
'年龄':[23,34,43],
'性别':['男','男','女']
}
df1=DataFrame(data=dict1,index=list('abc'))2.3.2索引
Series可以理解成带索引的数据,而DataFrame是表格结构的数据
2.3.2.1一级索引
一级索引获取到的是Series类型的数据.
获取单列
- df.Python
- df['Python'][1:3]
获取单行
- df.loc['a']
- df.iloc[2]
- df.ix['a']
- df.ix[2]
2.3.2.2二级索引
获取到的是DataFrame类型的数据.
获取行和列
- df[['Python','Java']].iloc[[1,4,5,6]] 先获取多列再获取多行
- df.loc[['a','b','c']][['Python','Java']] 先获取多行再获取多列
- df.loc[['a','b','c']] 获取多行 与iloc或者ix这两个函数有相同的功能
- df[['Python','Java']] 获取多列
2.3.3切片
和索引操作的不同,索引操作是先从列开始算再是行获取,但是切片操作是先从行开始再从列开始,切片操作使用一个括号获取的直接就是DataFrame,和Numpy中的矩阵操作比较类似.
- df['a':'g']切取多行
如果想要在切取行的时候还切取列,我们可以使用函数loc,iloc和ix等
- df.loc['a':'g','Python':'PHP'] 使用iloc和ix也能发挥同样的功能.
注意:切记直接使用一个括号进行的是切片操作,
2.3.4各种数据类型之间的转换
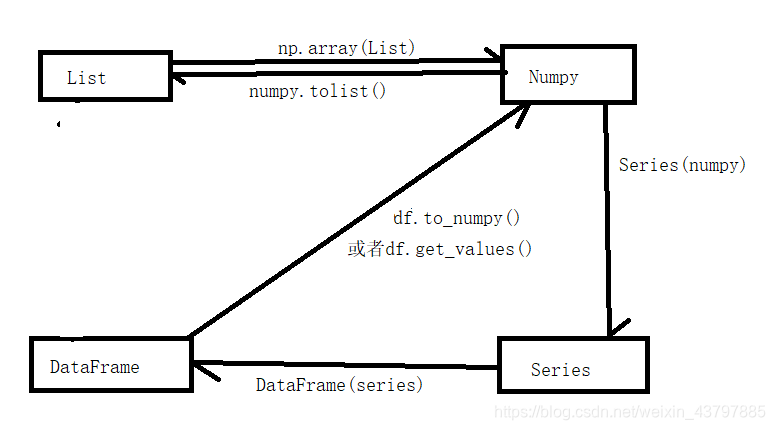
2.3.5DataFrame的运算函数
我们对DataFrame的运算其实基本上都是对Series的运算,因为如果我们想改变DataFrame中某些行或者列的值,我们通过括号取出的却是Series的类型,因此我们对DataFrame的运算基本都是对Series的操作。
统计函数
- df['平均分'].count()
- df['平均分'].min()
- df['平均分'].max()
- df['平均分'].mean()
- df['平均分'].median()
- df['平均分'].std()
- df['平均分'].argmax()
- df['平均分'].unique()
- df['平均分'].add_prefix('pre_')
- df['平均分'].add_suffix('_suf')
- df['平均分'].map(lambda x : x+ 100)
- df['c'][2]=np.nan
- df.info() # 查看数据的基本信息
- df.describe() # 查看数据的统计情况
排序函数
- series.sort_values(axis=0) # 按照值进行排序
- series.sort_index(axis=0) # 按照索引进行排序
- df.sort_index() 根据索引进行排
- df.sort_values(by='b') # 根据指定的值进行排序
- df.sort_values(by=1, axis=1) # 指定值,指定维度进行排序
2.4广播机制
2.4.1Series
Series和数字进行计算
pd.Series(np.array([1,2,3]))+10Series之间是没有广播的,因为Series是自带索引的,索引是它的唯一辨识。如果Series的长度不一致或者索引没有对应的时候,我们可以使用pandas提供的方法进行运算,索引不对齐的地方用fill_value进行填充.
pd.Series([1,2,3])+pd.Series([1,2,3,4])
s1=pd.Series(np.array([1,2,3]))
s2=pd.Series(np.array([4,5,6,7]))
s1.add(s2,fill_value=0)2.4.3DataFrame
1】和数值进行运算
pd.DataFrame(
data=np.random.randint(0,10,size=(2,3)),
columns=['Python','Java','C']
)+102】DataFrame之间的加法没有广播,对应位置相加,如果没有对应上,那么就会是NaN.add方法,如果有空的位置,就用指定的值进行填充。
df1.add(df2,fill_value=0)2.5数据的读取和保存
数据读取和写入的时候首先我们要安装openpyxl和xlrd包。
csv文件数据的读取和保存:短网址生成器
df=pd.read_csv('http://suo.im/6ja5G4')
df.to_csv('./1.csv')将数据写入数据库
# 首先应该安装这两个包
# pip install mysqlclient
# pip install sqlalchemy
# 创建连接数据库的引擎
engine = sqlalchemy.create_engine('mysql+mysqldb://softpo:root@localhost/dushu?charset=utf8')
# 直接写入,不添加主键,会报警告
df2.to_sql('book211',engine,index=False)存入数据的同时添加主键
# 修改了主键,增删改查都可以
# unsigned int8 - 128 ~ 127 无符号 0 ~ 255
with engine.connect() as conn:
conn.execute('alter table book985 change id id int unsigned not null auto_increment primary key;')
with engine.connect() as conn:
df = conn.execute('select * from book985 limit 100')
for i in df:
print(i)数据库中数据的读取
import pymysql
conn = pymysql.connect(host = 'localhost',port = 3306,database = 'dushu',user = 'softpo',
password = 'root',charset = 'utf8') # 连接
df = pd.read_sql('select * from books',conn) # 读取数据数据库中数据的查询
df.query("book_name == '主人的溃败'") # 精确查询
df2 = df.query("book_name.str.contains('的')") # 模糊查询2.6Pandas与SQL的对比
- select--切片
- from--join,merge,concat,append
- where--query
- group by---groupby
- having---apply(),transform(),max()
- orderby---sort_values(),sort_index()















 184
184











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









