







week1第四章---梯度下降---吴恩达机器学习笔记
4-1 梯度下降
上节中,
J
(
w
,
b
)
J(w,b)
J(w,b)是求线性回归的代价函数,但事实证明 梯度下降(gredient decent) 是一种可以用来最小化任何函数的算法,而不仅仅是线性回归的代价函数。
比如要找到代价函数
J
(
w
1
,
w
2
,
.
.
.
,
w
n
,
b
)
J(w_1,w_2,...,w_n,b)
J(w1,w2,...,wn,b)的最小值,梯度下降要做的就是,从对
w
w
w和
b
b
b的初步猜测开始。在线性回归中,参数的初步猜测并不重要,所以常见的选择是将她们都置为0。而在梯度下降中,我们需要继续多次更改
w
w
w和
b
b
b的值以降低
w
w
w和
b
b
b的代价函数
J
J
J,直到
J
J
J达到或接近最小值。
需要注意有些代价函数的图像不是碗状或吊床,并且可能不止一个可能的最小值。
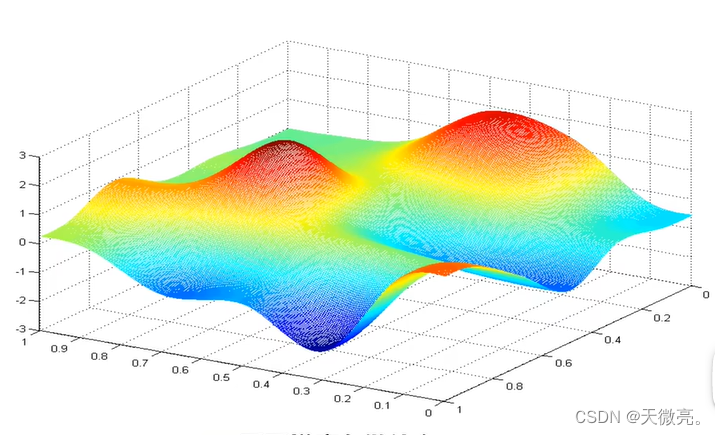
来看一个代价函数的曲面图,这并不是平方误差代价函数,而是一种在训练神经网络模型时得到的代价函数。假设它是一个稍微多山的户外公园。
想象一下你正站立在山的这一点上,站立在你想象的公园这座红色山上,在梯度下降算法中,我们要做的就是旋转360度,看看我们的周围,并问自己要在某个方向上,用小碎步尽快下山。这些小碎步需要朝什么方向?如果我们站在山坡上的这一点,你看一下周围,你会发现最佳的下山方向,你再看看周围,然后再一次想想,我应该从什么方向迈着小碎步下山?然后你按照自己的判断又迈出一步,重复上面的步骤,从这个新的点,你环顾四周,并决定从什么方向将会最快下山,然后又迈进了一小步,并依此类推,直到你接近局部最低点的位置。
梯度下降有一个有趣的特性,当选择不同的初起点下山时,可能会达到不同的终点。在第一个谷底没有到达第二个谷底的道路,第二个谷底也没有到达第一个谷底的道路。这两个谷底都成为局部最小值。
4-2 梯度下降的实现
梯度下降算法如下:
w
=
w
−
α
∂
J
(
w
,
b
)
∂
w
w = w - \alpha \frac{\partial J(w,b)}{\partial w}
w=w−α∂w∂J(w,b)
b
=
b
−
α
∂
J
(
w
,
b
)
∂
b
b = b - \alpha \frac{\partial J(w,b)}{\partial b}
b=b−α∂b∂J(w,b) 其中
α
\alpha
α为学习率(learning rate),即下山的步长。在下山的例子中,我们通过小碎步的方式走到谷底,而在梯度下降中,我们不断重复以上两个更新步骤,直到算法收敛,即当达到局部最小的点时,参数
w
w
w和
b
b
b不再发生明显的变化。
我们要同时更新两个参数
w
w
w和
b
b
b,方法如下:

4-3 理解梯度下降
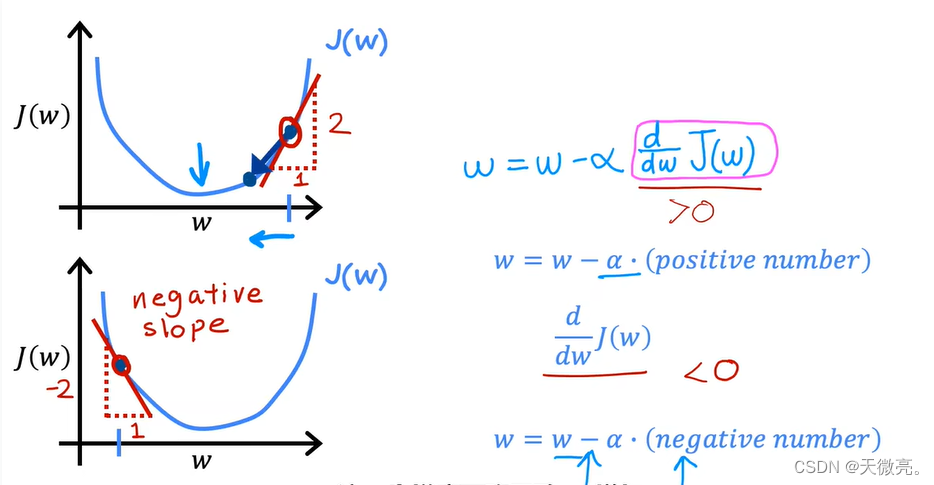
本节中我们通过理解算法中的两个导数(derivative),从直觉上更好的理解梯度下降。
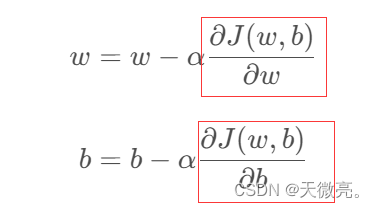
下图将代价函数简化为1个参数
w
w
w,并让我们理解梯度下降正在做什么以及参数如何变化。
4-4 学习率
学习率
α
\alpha
α的选择,将对我们实现梯度下降的效率产生巨大影响。
若
α
\alpha
α特别小,比如
α
=
0.0000001
\alpha = 0.0000001
α=0.0000001,梯度下降的每一步都是微不足道的,收敛速度特别慢。
若
α
\alpha
α过大,则
w
w
w可能会过头,甚至离终点越来越远。
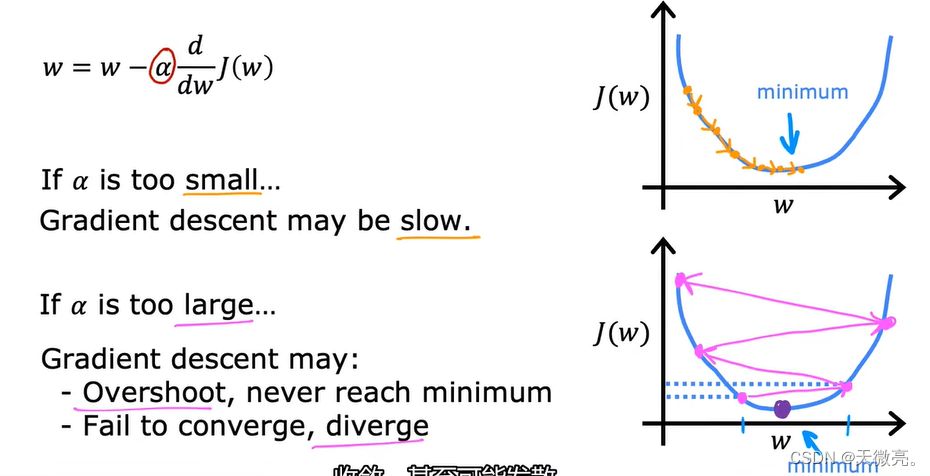
若此时
w
w
w已经使
J
J
J处于局部最小值,下一步梯度下降最怎么做呢?

可以看见此时导数=0,下一步中
w
=
w
−
0
w=w-0
w=w−0,
w
w
w值没有发生变化,即保持在局部最小值,这也同时解释了即使在固定的学习率
α
\alpha
α下,梯度下降也可以达到局部最小值。
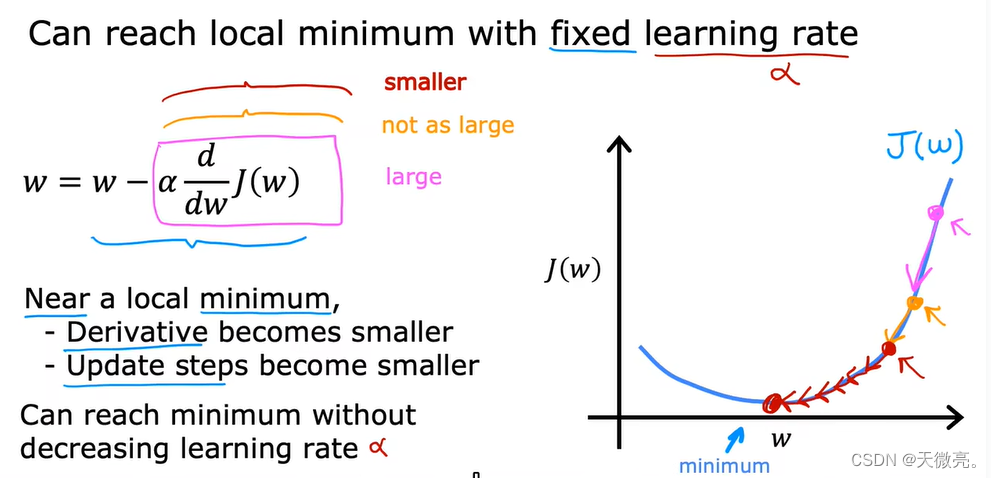
再给出一个固定
α
\alpha
α下达到局部最小值的例子:
越接近最小值,减项越小,
w
w
w变化的距离越小,最终总会达到局部最小值。
4-5 用于线性回归的梯度下降
公式:

用于线性回归的梯度下降可能会导致多个局部最小值,而当使用线性回归的平方误差表示的成本函数时,它只有一个(全局)最小值,曲面图是碗状,只要有一个合适的学习率
α
\alpha
α,就可以收敛到全剧终最小值。
4-6 运行梯度下降
梯度下降算法的实际应用:做实验,运行代码。















 1169
1169











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









