






k8s简介
编排工具分类
系统层面
ansible、saltstack
docker容器
- docker compose + docker swarm + docker machine
docker compose:实现单机容器编排
docker swarm:实现多主机整合成为一个
docker machine:初始化新主机
- mesos + marathon
mesos IDC的操作系统,Apache研发的资源分配工具
- kubernetes
开发模式和架构
开发模式
瀑布式开发→迭代开发→敏捷开发→DevOps
应用程序的架构
单体架构→分层架构→微服务
DevOps
过程:
需求→开发→测试→交付→部署
应用模式的开发把开发与运维整合起来,打破了两者直接的壁垒。
CI(持续集成):
开发完合并代码到代码仓库然后自动构建部署测试,有问题打回给开发,无问题自动交付给运维方
CD(持续交付):
测试完之后自动打包好最终产品,并存放到可以被运维或客户拿到的地方
CD(持续部署):
交付完后自动拖出开发包并自动部署,运行时出现的bug自动反馈给开发
容器化部署优势:
早期交付与部署环节因为各种不同系统不同版本的环境因素使其极其的困难,而容器的实现可以使其得以非常容易实现,可以真正的一次编写多次部署
微服务:
把每一个应用都拆解成一个微小的服务,只做一个功能,例如把一个单体应用程序拆解为数百个微服务,让其彼此间进行协作
缺点:
分发部署以及微服务互相之间的调用关系变得极其复杂,并且数以百计微服务难免其中的某些微服务会出现很问题,而单靠人工梳理和解决并不现实,容器与编排工具可以完美解决这些问题
解决方案:
正是容器和编排工具的出现使得微服务和DevOps得以容易落地
kubernetes的特性
自动装箱
自我修复
水平扩展
服务发现和负载均衡
自动发布和回滚
密钥和配置管理
批量处理执行
K8S组成与架构
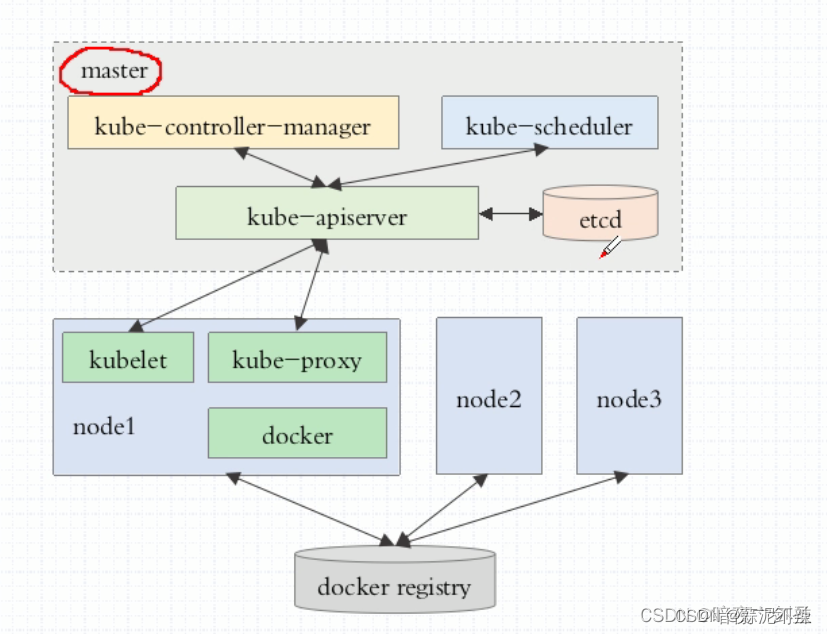
K8S组成架构
整个kubernetes由master、node、组件、附件、统一日志收集平台 组成
kubernetes是一个有中心节点架构的集群系统master/node,一般会有一个或一组(三个master)节点作为主节点来做高可用,各node节点是用来贡献计算能力、存储能等相关资源(运行容器)的节点
master四个核心组件(运行为三个守护进程):
- API Server:
负责对外提供服务解析请求,并且需要存储整个集群中的个对象的状态信息,向客户端提供服务时使用https协议需要CA与证书
- scheduler(调度器):
负责观测每个node之上的资源,并根据用户请求要创建容器所需要的资源量找到符合条件的node,然后根据调度算法中的最优算法选择最优node
- 控制器管理器:
负责监控并确保每一个控制器的健康,并且在多个master之上做控制器管理器的冗余
- etcd共享存储:
由于API Server需要存储整个集群中的对象的状态信息,存储量较大所以就需要etcd来实现;etcd是一个键值存储的数据库系统,而考虑到etcd的重要性,一般需要三个节点做高可用,默认是通过https进行通信,并且通过不同的两个接口分负责内外通信,其中内部通信需要一个点对点通信证书;向客户端提供服务是通过另一套证书实现
node:理论上任何有计算能力可以装容器的机器都能作为node,三个核心组件:
- kubelet(集群代理):
与master通信,接收master和调度过来的各种任务并试图让容器引擎(最流行的容器引擎为doker)来执行
- docker:
容器引擎,运行pod中的容器
- kube-proxy:
每当pod增删和service需要改变规则需要依赖kube-proxy,每当pod增删时会有一个通知,通知到所有相关联的组件,service收到通知需要kube-proxy修改所有集群内所有节点的iptables
其他组件:
pod控制器:
工作负载(workload)负责监控所管理的每一个容器是否是健康的应用节点数是否符合,确保pod资源符合预期的状态,如果出现异常则向API server发送请求,由kubernetes重新创建启动容器、还可以滚动更新或回滚
控制器有多种类型:
- ReplicaSet:
代用户创建指定数量的pod副本数量,确保pod副本数量符合预期状态,并且支持滚动式自动扩容和缩容功能。
帮助用户管理无状态的pod资源,精确反应用户定义的目标数量,但是RelicaSet不是直接使用的控制器,而是使用Deployment
ReplicaSet主要三个组件组成:
(1)用户期望的pod副本数量
(2)标签选择器,判断哪个pod归自己管理
(3)当现存的pod数量不足,会根据pod资源模板进行新建
- Deployment:
工作在ReplicaSet之上,用于管理无状态应用,目前来说最好的控制器。支持滚动更新和回滚功能;还提供声明式配置,可以随时重新进行声明,随时改变我们在API Server上定义的目标期望状态,只要那些资源支持动态运行时修改。
更新和回滚功能:
Deployment一般会控制两或多个个ReplicaSet,平时只激活运行一个,当更新时逐一停止激活状态的ReplicaSet上的容器并在另一个ReplicaSet上创建直到完成,回滚是相反的动作;可以控制更新方式和节奏:例如定义一次更新几个节点或者先临时加几个pod正常后在删除旧pod使能正常提供服务的pod个数保持一致等等
HPA:二级控制器,负责监控资源,自动伸缩
- DaemonSet:
用于确保集群中的每一个节点或符合标签选择器的节点上只运行特定的pod副本,通常用于实现系统级后台任务。比如ELK服务日志收集分析工具。只要新增节点就会自动添加此pod副本
Deployment和DaemonSet所部署的服务特性:
服务是无状态的
服务必须是守护进程
- Job:
只要完成就立即退出,不需要重启或重建;如果任务没完成异常退出才会重建Pod。适合一次性的任务
- Cronjob:
周期性任务控制,不需要持续后台运行
- Statefulset:
管理有状态应用,每一个Pod副本都是被单独管理
pod:
kubernetes中最小单元,是在容器上又封装一层模拟虚拟机,一个pod里可以有多个容器(一般为一个),其中这多个容器可以共享一个网络名称空间、共享存储卷
两类:
自主式pod:如果node故障,其中的pod也就消失了
pod控制器管理的pod
label(标签):
可以用打标签的方式给资源分组,所有对象都可打标签(pod是最重要的一类对象)格式:key=value
selector(标签选择器):
根据标签过滤符合条件的资源对象的机制
service:
是一个四层调度器。实际是一个宿主机上的iptables dnat规则和宿主机的一个虚拟的地址负责反向代理后端容器服务,所以如果你创建一个service,service是会反应到整个集群的每一个节点之上的。他是可以被解析的地址也是固定的,但是并不附加在网卡之上;由于后端容器频繁的变更,不断伸缩、创建删除,他们的地址与容器主机名称是不固定的,所以后端容器每次变动,service通过标签选择器获取他们的标签区别并记录他们并同时记录对应的地址与容器名字,因此当服务请求进来后先到service,通过service找到对应的服务并且转发到其中的容器中,不过安装完K8S之后需要在集群中的dns中配置他的域名解析,如果手动修改service地址或名字,dns中的解析记录也会自动修改,如果后端一个服务有多个节点,service支持ipvs,会把规则写入ipvs中进行负载均衡
service规则默认用的是ipvs,如果不支持ipvs则自动降为iptables
监控:
监控相关资源利用、访问量、是否故障
四个核心附件:
- dns
service想要被发现需要dns服务,dns也是运行在pod之中
- Metrics Server:
用于收集和聚合集群和容器级别的资源使用情况和度量数据,实现监控(与Prometheus结合实现监控功能)和自动伸缩(HPA)等用途。
- Kubernetes Dashboard:
提供了一个基于 Web 的用户界面,用于可视化管理和监控 Kubernetes 集群。
- Ingress Controller:
用于将外部网络流量路由到集群内部的服务。常见的 Ingress Controller 包括 Nginx Ingress Controller 和 Traefik。
统一日志收集工具:EFK
访问过程
在K8S上创建一个NMT

客户→LBaas→node接口→nginx_service→nginx容器→tomcat_service→tomcat→mysql_service→mysql
如果使用的是阿里云,则在云上调用底层LBaas,因为node上可能没有网卡,所以用来负责把请求来的流量调度到node上的对外的接口上,然后通过控制器创建两个pod装载nginx,nginx之上创建一个servece负责接收node接口的流量,并把流量转发给nginx;继续通过控制器创建三个pod装载tomcat,之上在创建一个service,同理再创建两个mysql之上创建一个service
K8S网络与通信
K8S总共有三种网络:
节点网络
集群网络(service网络)
pod网络
三种通信场景:
- 同一个pod之间通信:
是通过lo通信
- 不同pod之间通信:
是通过“叠加网络”进行通信,把需要传递到pod的IP和端口报文外部再封装一个IP用于不同节点之间的传递,当节点接收到叠加网络报文时进行拆封,然后再根据内部的IP和端口找到对应的服务,当然pod是动态的随时会进行增删就需要通过service来找到具体目标pod
- pod与service之间通信:
因为service地址实际上只是宿主机上iptables规则地址,创建service后会反应到整个集群的所有节点和宿主机iptables之上,当pod需要与service通信时会把网关指向docker0乔的地址,另外宿主机也可以把docker0乔当作自己的一个网卡,所以宿主机之上pod可以直接与service通信,通过iptables规则表检查指向发送请求
CNI插件体系:
- 容器网络接口:
负责接入外部插件网络解决方案,可以运行在pod之上作为集群的一个附加使用,需要共享宿主机的网络名称空间。
- 主要作用:
负责给pod、service提供ip地址
负责网络策略功能:实现pod隔离,让不同的pod之间根据要求通过添加规则实现互通或隔离,防止托管在pod中的恶意服务截取或攻击其他pod中服务
- 常见插件:
flannel(叠加网络):只支持网络配置
calico(三层隧道网络):支持网络配置和网络策略
canel:把前两者结合,用flannel配置网络,用calico配置网络策略
...
- CA:K8S一般是需要5套CA
etcd与etcd之间
etcd与API Server之间
API Server与用户之间
API Server与kubetel之间
API Server与kube-proxy之间
k8s名称空间:
把一个集群根据每一类pod切割成多个名称空间,而切割的这个名称空间边界不是网络边界而是管理边界,例如创建一个项目,项目下可以有多个pod,可以批量管理这个项目中的pod,项目完成可以批量删除整个项目
部署
常用部署方式:
- 传统手动部署:
所有组件运行为系统的守护进行,很繁琐包括做5个CA
- kubespray:
kubespray是一个基于Ansible的部署方案,根据已经写好的ansible的剧本进行执行,也是把所有组件运行为系统的守护进行
- kubeadm(官方提供安装工具):
容器化部署,更像是一套完整的脚本封装,比较快速简单
kubeadm部署
- 服务器设置:
至少两核cpu
部署网络环境:
节点网络:172.20.0.0
service网络:10.96.0.0/12
pod网络:10.244.0.0/16 (flannel插件默认)
master+etcd:172.20.0.70
node1:172.20.0.66
node2:172.20.0.67
- 版本设置
centos7.9
docker-ce-20.10.8、docker-ce-cli-20.10.8
kubelet-1.20.9、kubeadm-1.20.9、kubectl-1.20.9
- 安装步骤:
1.所有主机安装docker+kubelet+kubeadm
2.初始化master:kubeadm init(检查前置条件、并会把master三个组件和etcd运行为pod、CA等)
3.初始化node:kubeadm join (检查前置条件、在pod中运行一个kube-proxy、dns、认证等)
- 安装参考文档:
官方文档
!!!安装参考文档,比较详细可以直接照着这个安装就行
- 注意事项:
docker跟k8s需要特定版本,版本差距较大会出现不兼容问题。以下是一些常见的 k8s 和 Docker 版本对应关系:
k8s 1.22.x 支持 Docker 20.10.x
k8s 1.21.x 支持 Docker 20.10.x
k8s 1.20.x 支持 Docker 19.03.x
k8s 1.19.x 支持 Docker 19.03.x
k8s 1.18.x 支持 Docker 19.03.x
- 程序相关目录
rpm -ql kubelet
/etc/kubernetes/manifests ----清单目录
/etc/sysconfig/kubelet ----配置文件
/etc/systemd/system/kubelet.service
/usr/bin/kubelet ----主程序
/etc/kubernetes/pki #存储ca等认证信息包括认证API sever的ca
- kubeadm初始化准备(master)
kubeadm init
Flags:
--apiserver-advertise-address string #设置apiserver监听地址(默认所有)
--apiserver-bind-port int32 #设置apiserver监听端口(default 6443)
--cert-dir string #设置证书路径(default "/etc/kubernetes/pki")
--config string #设置配置文件
--ignore-preflight-errors strings #预检查时忽略掉出现的错误( Example: 'IsPrivilegedUser,Swap' )
--kubernetes-version string #设置使用的kubernetes版本(default "stable-1")
--pod-network-cidr string #pod网络(flannel插件默认网络为 10.244.0.0/16 )
--service-cidr string #service网络(default "10.96.0.0/12")
- 复制kubectl配置文件:
mkdir -p $HOME/.kube
sudo cp -i /etc/kubernetes/admin.conf $HOME/.kube/config
sudo chown $(id -u):$(id -g) $HOME/.kube/config
#admin.conf文件:kubeadm帮我们自动初始化好的一个被kubectl拿来做配置文件指定连接至K8s的API server并完成认证的配置文件
kubect命令
- kubectl:
是API Server的客户端程序,这个客户端程序是通过连接master节点上的API server这一个对应的应用程序,这也是整个K8S集群上唯一一个管理入口,kubectl就是这个管理入口的客户端管理工具
- 面向对象:
kubectl仿照于面向对象的开发语言,所有k8s中的资源都可以看做对象类,类中有方法和属性。每当根据给定的参数创建pod时就相当于给类中的方法赋值,相当于实例化对象。
- 相关命令:
kubectl
version #获取版本信息
cluster-info #获取集群信息
api-versions #查看当前可支持api的版本
-h #获取帮助
explain <type>.<fieldName>[.<fieldName>] #资源配置清单文档
示例:
kubectl explain pod.spec.volumes.pvc
describe #获取对象的详细描述信息包括所有可以作为对象的目标如:pod、service、node、deployment等
示例:kubectl describe pod nginx-deploy
get 获取信息
cs #组件状态信息
nodes #节点信息
deployment #查看此控制器已创建的pod
ns #获取名称空间
pods #获取当前正在运行的pod信息
deployment #查看控制器信息
services/svc #查看service信息
(以下命令需要追加到对象之后)
-w #持续监控
-n #指定名称空间
-o
wide #显示扩展信息
yaml #以yaml格式输出信息
--export #表示导出它的配置
--show-labels #(需要追加到对象之后)显示所有标签
-L #输出所有,但是只显示指定的标签的标签值,未指定的不显示
示例:
kubectl get pods -L app,run
-l #标签过滤,只输出指定标签的资源
格式(可指定多个):
等值关系(只过滤KEY/等于/不等于):
KEY_1,...KEY_N/KEY_1=VAL_1,.../KEY_1!=VAL_1,...
集合关系:
KEY in (VAL_1,...VAL_N) 键的值只要是这集合中的一个就匹配
KEY notin (VAL_1,...VAL_N)键的值不是是这集合中的一个就匹配
KEY 有这个键的标签就匹配
!KEY 无这个键的标签就匹配
示例:
kubectl get pods -l app,release --show-labels
kubectl get pods -l release=conary,app=myapp --show-labels
kubectl get pods -l "release in (canary,beta)" #过滤 release这个键的值包含canary,beta的pod
kubectl get pods -l "release notin (canary,beta)" #过滤 release这个键的值不包含canary,beta的pod
(以上命令需要追加到对象之后)
run NAME #(控制器名称) 创建并启动
--image='': #指定镜像
--port='': #暴漏端口
--dry-run=true #模拟执行,非真正执行
-- <cmd> <arg1> ... <argN> #指定运行命令和参数
--restart=Never #pod异常后不自动创建
-i
-t
Examples:
kubectl run nginx-deploy --image=nginx:1.14-alpine --port=80 --dry-run=true
测试:在集群中所有node节点都可以使用curl访问此nginx,但只能集群内部访问,想要外部访问需要特殊类型的service
注:每个node会自动生成一个桥和接口,例如: cni0:inet 10.244.1.1 netmask 255.255.255.0 broadcast 10.244.1.255。此node上所有的pod都会在10.244.1.0 网段
kubectl run client --image=busybox -it --restart=Never
查看命令
kubectl get pods -o wide
create #用于创建 Kubernetes 对象。如果对应的资源已经存在,则会返回错误,此时需要先删除原有的资源对象,然后再执行创建操作。如果资源对象不存在,则会自动创建对应的资源对象。适用于初始化资源对象的场景
-f FILENAME #根据资源配置yaml文件创建资源
[options]:#资源对象
namespace NAME
deployment NAME
--image=[]
--dry-run #追加上次选项表示干跑一次(并没有实际执行)并输出一个yaml框架
示例:
kubectl create -f pod-demol.yaml
kubectl create deployment nginx-deploy --image=nginx:1.14-alpine
apply (-f FILENAME | -k DIRECTORY) [options] #用于声明式创建或更新一个 Kubernetes 对象并且可以声明多次。如果该资源对象已经存在,则会首先尝试更新对应的字段值和配置,如果不存在则会自动创建资源对象。适合更新和修改已有的资源对象,因为它会对比新的 YAML 配置文件和已有的资源对象配置,只更新需要更新的部分,而不会覆盖已有的全部配置。
示例:
kubectl create -f pod-demol.yaml
patch #命令允许用户对运行在 Kubernetes 集群中的资源进行局部更新。相较于我们经常使用的 kubectl apply 命令,kubectl patch 命令在更新时无需提供完整的资源文件,只需要提供要更新的内容即可。
Usage:
kubectl patch (-f FILENAME | TYPE NAME) -p PATCH [options]
options:
-p #打补丁
示例:
kubectl patch pod valid-pod -p '{"spec":{"containers":[{"name":"kubernetes-serve-hostname","image":"new image"}]}}'
kubectl patch deployment myapp-deploy -p '{"spec":{"replicas":5}}'
delete ([-f FILENAME] | [-k DIRECTORY] | TYPE [(NAME | -l label | --all)]) [options]
示例:kubectl delete -f pod-demol.yaml
expose #暴漏服务端口,相当于创建一个service然后把pod服务中的端口映射固定在service上,创建完成后默认为ClusterIP类型所以集群外部依然不能访问,集群内部pod或node可以通过service进行访问服务。首先需要集群中dns找到service,然后service会生成一个iptables或ipvs规则把访问此service指定端口的请求都调度至它用标签选择器关联到的各pod后端(可以用 kubectl describe svc NAME 查看关联了哪些标签,可以用kubectl get pods --show-labels 显示pod有哪些标签 )
#解析的步骤:
kubectl get svc/pod -n kube-system 查到dns的service代理IP为10.96.0.10;
在pod中启动两个服务nginx-deploy并暴漏端口80映射为80,设置其service名字为nginx。因为集群中域名的默认后缀为default.svc.cluster.local,所以nginx域名为nginx.default.svc.cluster.local;
解析测试:host -t A nginx.default.svc.cluster.local 10.96.0.10 解析地址为nginx地址
Usage:
kubectl expose (-f FILENAME | TYPE NAME) [--port=port] [--protocol=TCP|UDP|SCTP] [--target-port=number-or-name] [--name=name] [--external-ip=external-ip-of-service] [--type=type] [options]
#注释:
(-f FILENAME | TYPE NAME):指定需要与创建的service建立连接的pod的控制器的名字
[--port=port]:service的端口
[--target-port=number-or-name]: pod中的端口
[--name=name]:service名称
[--type=type] : Type for this service: ClusterIP, NodePort, LoadBalancer, or ExternalName. Default is 'ClusterIPservice'.
#service的4中主要类型合作用:
1.ClusterIP 是默认的 Service 类型。它将创建一个虚拟的 IP 地址,用于连接客户端和 Pod。这个 IP 地址只能在集群内部使用,无法从集群外访问。这种类型通常用于后端服务,如数据库或缓存服务。
访问路径:集群内部client → ClusterIP:ServicePort → PodIP:containerPort
2.NodePort 允许从集群外部访问 Service,通过将提供的端口号映射到 Pod 的 IP 地址上,同时也会将该端口暴露到集群节点的 IP 地址上。这种类型通常用于开发和测试,不建议在生产环境中使用。
访问路径:集群外部client → [负载均衡器]→NodeIP:NodePort→ClusterIP:ServicePort → PodIP:containerPort
3.LoadBalancer 可以在云环境中借助底层lbaas自动创建外部负载均衡器,并将客户端请求路由到 Pod。该类型的 Service 通常用于公共云或私有云环境中,可以将流量平衡到多个集群节点上,从而提高服务的可靠性和可用性。
访问路径:集群外部client →负载均衡器(Lbaas)→ NodeIP:NodePort→ClusterIP:ServicePort → PodIP:containerPort
4.ExternalName Service 允许 Service 对外暴露一个外部名称,这个名称可以被解析为外部服务的 DNS 名称。该类型的 Service 不会在集群中创建任何负载均衡器或 IP,而是将请求直接转发到指定的外部服务。一般是集群内pod作为客户端需要请求集群外服务时使用。
5.无头service,定义ClusterIP时设置为None。此时解析service域名时直接解析到后端Pod服务
Examples:
kubectl expose deployment nginx-deploy --name=nginx --port=80 --target-port=80 --protocol=TCP
容器中访问测试:
wget -O - -q nginx
wget -O - -q myapp/hostname.html #可查看调度到哪个pod(需要使用此镜像:--image=ikubernetes/myapp:v1)
edit 修改对象信息,包括所有可以作为对象的目标如:pod、service、node、deployment等
object NAME 注:可以直接改service类型,例如把ClusterIP改为 NodePort service的内部集群端口就会自动随机映射为外部端口,可以get查看端口,因此就可以通过外网使用集群中任何节点网络的IP:PORT 访问到此pod中的服务
示例:
kubectl edit svc nginx
scale 伸缩控制器规模
Usage:
kubectl scale [--resource-version=version] [--current-replicas=count] --replicas=COUNT (-f FILENAME | TYPE NAME)
注释:
[--resource-version=version] [--current-replicas=count]:过滤条件
Examples:
kubectl scale --replicas=5 deployment myapp
set
image 更新升级镜像
Usage:
kubectl set image (-f FILENAME | TYPE NAME) CONTAINER_NAME_1=CONTAINER_IMAGE_1 ... CONTAINER_NAME_N=CONTAINER_IMAGE_N
#CONTAINER_NAME_1=CONTAINER_IMAGE_1:指明pod中的哪个容器和镜像,可以指定多个,可以用kubectl describe 查看pod内容器的名称,在Containers:下
Examples:
kubectl set image deployment myapp myapp=ikubernetes/myapp:v2
rollout 管理一个或多个资源的上线
Usage:
kubectl rollout SUBCOMMAND [options]
Commands:
status Show the status of the rollout
Examples:
kubectl rollout status deployment myapp
undo 回滚,默认回滚到上一个版本
Usage:
kubectl rollout undo (TYPE NAME | TYPE/NAME) [flags] [options]
history #查看滚动历史
示例:
kubectl rollout history deployment myapp-deploy
pause #暂停
resume #启动,与先暂停对应
logs PodName
-c containername (如果pod内有多个容器需要指定容器名称)
示例:
kubectl logs myapp-5d587c4d45-5t55g
kubectl logs pod-demol -c myapp
labes 配置标签
#标签相当于附加到对象上的键值对
#一个资源对象可以有多个标签,一个标签也可以被添加至多个资源对象之上;
#标签可以在资源创建时指定,也可以在创建后通过命令管理
#键值对有大小和字符规范限制
Usage:
kubectl label [--overwrite] (-f FILENAME | TYPE NAME) KEY_1=VAL_1 ... KEY_N=VAL_N [--resource-version=version]
Examples:
kubectl label pods foo unhealthy=true 添加标签
kubectl label pods foo unhealthy=yes --overwrite 修改覆盖标签
许多类型的资源都要基于标签选择器关联其他资源例如控制器、service。此时通常使用另外两个字段进行嵌套定义其使用的标签选择器:
matchLabels 直接定义键值(service只支持这一种)
matchExpressions 基于给定的表达式来定义使用标签选择器,格式{key:"KEY",operator:"OPERATOR",values:[VAL1,VAL2....]}
#operator为判断条件,操作符如:In, NotIn,Exists, NotExists
示例:
kubectl explain pod.spec.nodeSelector:
nodeSelector <map[string]string> #节点标签选择器,可以选择让pod运行在哪一类节点上
exec #容器外跳过边界执行容器内命令
Usage:
kubectl exec (POD | TYPE/NAME) [-c CONTAINER] [flags] -- COMMAND [args...] [options]
#[-c CONTAINER]:pod中有多个容器需指定容器名
示例:
kubectl exec myapp-5d587c4d45-h4zxn date
kubectl exec myapp-5d587c4d45-h4zxn -it -- /bin/sh
kubectl exec pod-demol -c myapp -it -- /bin/sh
explain <type>.<fieldName>[.<fieldName>] #查看K8S内建的格式说明
示例:
kubectl explain pods
kubectl explain rs
kubectl explain pods.spec.containers
Pod的生命周期:
从创建到结束的所有状态:
Pending, Running, Failed, Succeeded, Unknown
#Pending:挂起,请求创建pod时条件不能满足调度没完成。例如已经创建但没找到符合指定tag的节点
#Unknown:未知状态,例如节点上的kubelet故障,API Server无法与之通信所以会出现未知状态
Pod生命周期中的重要行为:
主容器启动前:始化容器,主进程启动前先运行辅助容器init进行初始化容器,甚至和可以运行多个并串行执行,运行完之后退出启动主进程
主容器启动时:执行启动后钩子
主进程运行时:
liveness:存活状态检测,判定主容器是否处于运行状态(runing),此时不一定能对外提供服务
readiness:就绪状态检测,判定容器中的主进程是否已经准备就绪并可以对外提供服务
(无论哪种探测都可以支持三种探测行为:执行自定义命令;向指定的TCP套接字发请求;向对指定的http服务发请求。并根据响应码判断其成功还是失败。即三种探针:ExecAction、TCPSocketAction、HTTPGetAction)
主容器结束后:执行结束后钩子
创建与删除Pod过程:
- 创建Pod过程
用户创建Pod后把请求提交给API Server
API Server会把创建请求的目标状态保存到etcd中
API Server会请求调度器进行调度,并把调度的结果、调度的那些节点资源保存到etcd中
节点上的kubelet通过API Server当中的状态变化得知任务通知,并拿到用户此前提交的创建清单
kubelet根据清单在当前节点上创建并启动pod
kubelet把当前pod状态发回给API Server
- 删除Pod过程:
防止删除Pod时数据丢失会向Pod内的每一个容器发送终止信号,让Pod中的容器正常进行终止,这个终止会给一个默认的宽限期默认30秒。如果过了宽限期还没终止就会重新发送kill信号
资源配置清单
apiserver仅接收json格式的资源定义:执行命令时会自动把你给的内容转换成json格式,而后再提交;查看yaml格式资源配置清单 实例: kubectl get pod myapp-848 -o yaml
一个yaml文件可以定义多个资源,需用—分隔开
资源配置清单可分为以下五部分(配置清单中的一级字段):
- apiVersion:
此对象属于K8S的哪一个API版本和群组,一般格式为 group/version 如果省略group则默认为核心组。
例:控制器属于app组;pod属于核心组
查看命令 :kubectl api-versions
- kind:
资源类别,用于初始化实例化成一个资源对象使用的
- metadata:元数据
提供的信息有:name、namespace、labels、annotations(资源注解)
selfLink:每个资源引用方式
固定格式:
api/GROUP/VERSION/namespaces/NAMESPACE/TYPE/NAME
示例:selfLink: /api/v1/namespaces/default/pods/myapp-848b5b879b-8fhgq
- spec:
用户期望的目标状态/规格,定义要创建的资源对象需要有怎样的特性或满足怎样的规范(例如它的容器应该有几个;容器应该用哪个镜像创建;容忍哪些污点)
- status:(只读)
显示当前资源的当前的状态,如果当前状态与目标状态不一致,K8S就是为了目标状态定义完后当前状态无限向目标状态靠近或转移,以此来满足用户需要,注意本字段由K8S集群维护,用户不能定义此字段
资源配置清单中自主式Pod的配置:
([]表示列表)
用法
kubectl explain pods:
metadata <Object>
annotations <map[string]string>#资源注解,与label不同的地方在于,它不能用于挑选资源对象,仅用于为对象提供“元数据”,并且字符没有大小等规范限制
spec <Object>
restartPolicy <string> #重启策略
Always #Pod中的容器挂了就重启无论是否是正常终止,默认为Always。
#重启逻辑:频繁重启会给服务器带来压力所以第一次会立即重启,每多一次重启就会增加等待时间,直到每5分钟重启一次
OnFailure #只有状态错误时就重启
Never #从不重启
nodeSelector <map[string]string> #节点标签选择器,可以选择让pod运行在哪一类节点上
nodeName <string> #指定pod运行的节点
hostNetwork <boolean> #设置pod直接使用主机的网络名称空间,此时可以使用主机ip:port直接访问pod,不需要暴露端口。常用在DaemonSet控制器中
hostIPC <boolean> #共享主机IP
hostPID <boolean> #共享主机PID
imagePullSecrets <[]Object> #存储了让docker连接私有仓库的账号和密码,账号和密码是由secret对象提供的
serviceAccount <string> #认证信息,可以是镜像仓库的认证
containers <[]Object>
- name <string> -required-
image <string>
imagePullPolicy <string> #镜像获取途径的策略
# <string>:
Always:远程仓库拉取
Never:要使用本地镜像,如果没有就等待,需要手动拉取镜像到本地
IfNotPresent:如果本地有镜像优先使用
默认用法:
如果镜像标签是latest那么默认值就是Always
除特定标签latest以外,其他标签默认镜像获取途径的策略为IfNot
Cannot be updated:如果每个字段写上这段信息表示对象一旦被创建以后改变这个字段值是不被允许的
ports <[]Object> #注释信息:标注要暴露的端口和端口信息,标注以后可以尝试引用这个名称
- name <string>
containerPort <integer> -required-
protocol <string>
command <[]string>
#自定义容器要运行的程序相当于docker配置中的Entrypoint,但是所给定的代码不是运行在shell中,需要手动指定
如果没有提供command,而docker镜像在制作时有ENTRYPOINT就会运行镜像中的ENTRYPOINT
而如果指定了command,无论指没指定参数,docker镜像中的ENTRYPOINT和CMD都会被忽略
示例:
command:
- "/bin/sh"
- "-c"
- "sleep 3600"h"
args <[]string>
#向Entrypoint传递的参数相当于docker配置中的CMD;如果指定args,则用args作为参数;如果没指定args且没指定command则用镜像中的CMD作为参数
#$(VAR_NAME):在args中引用变量
#$$$(VAR_NAME):进行逃逸,不使用引用的变量替换
env <[]Object> #设置环境变量
- name <string> -required-
value <string> #如果引用别的变量格式:$(VAR_NAME)
lifecycle <Object> #定义终止前和启动后钩子,用来定义启动后与终止前需要立即执行的操作
postStart <Object> #启动后钩子
exec <Object>
httpGet <Object>
tcpSocket <Object>
preStop <Object> #终止前钩子
exec <Object>
httpGet <Object>
tcpSocket <Object>
readinessProbe <Object> #就绪状态检测,与livenessProbe用法相同
livenessProbe <Object> #存活状态检测
exec <Object> #探测行为,执行自定义命令
command <[]string> #如果返回值是成功说明是存活的,如果返回状态码表示存活探测失败
httpGet <Object> #探测行为,向指定的TCP套接字发请求,通过http返回状态码判断
host <string> #defaults to the pod IP.
path <string>
port <string> -required- #可以引用端口名称
tcpSocket <Object> #探测行为,向对指定的http服务发请求
host <string> #defaults to the pod IP.
port <string> -required-
failureThreshold <integer> #探测几次都失败才认为失败,默认3次
periodSeconds <integer> #每一次探测间隔时间默认10秒
timeoutSeconds <integer> #超时时间,默认1秒
initialDelaySeconds <integer> #第一次探测的时间,默认容器启动完就开始探测
示例:
(自主式Pod,不受控制器管理)
vim pod-demal.yaml:
apiVersion: v1
kind: Pod
metadata:
name: pod-demol
namespace: default
labels:
app: myapp1
tier: frontend
spec:
containers:
- name: myapp
image: ikubernetes/myapp:v1
ports:
-name: http
containerPort: 80
readinessProbe:
httpGet:
port: http
path: /index.html
initialDelaySeconds: 1
periodSeconds: 3
livenessProbe:
httpGet:
port: http
path: /index.html
initialDelaySeconds: 1
periodSeconds: 3
- name: busybox
image: busybox:latest
command:
- "/bin/sh"
- "-c"
- "sleep 3600"
- name: busybox-liveness-exec-container
image: busybox:latest
imagePullPolicy: IfNotPresent
command: ["/bin/sh","-c","touch /tmp/healthy; sleep 60; rm -rf /tmp/healthy; sleep 3600"]
livenessProbe:
exec:
command: ["test","-e","/tmp/healthy"]
initialDelaySeconds: 1
periodSeconds: 3
根据创建的配置清单文件创建容器:
kubectl create -f pod-demol.yaml
删除:
kubectl deleted -f pod-demol.yaml
kubectl deleted pods pod-demol
资源配置清单中Pod控制器配置
ReplicaSet控制器
用法
kubectl explain rs/ReplicaSet:
kind <string>
metadata <Object>
spec <Object>
replicas <integer> #副本数
selector <Object> -required- #标签选择器
template <Object> #模板,此模板嵌套的就是Pod的配置清单
metadata <Object> #Pod的metadata
spec <Object> #Pod的spec
matchExpressions <[]Object>
matchLabels <map[string]string>
示例:
(可以通过kubectl edit rs myapp 直接修改运行中控制器的yaml配置清单内容实现扩缩容和更新镜像等,但是更新镜像需要手动删除容器自动创建后才会是最新镜像)
apiVersion: apps/v1
kind: ReplicaSet
metadata:
name: myapp
namespace: default
spec:
replicas: 2
selector:
matchLabels:
app: myapp
release: canary
template:
metadata:
name: myapp-pod
labels:
app: myapp
release: canary
environment: qa
spec:
containers:
- name: myapp-container
image: ikubernetes/myapp:v1
ports:
- name: http
containerPort: 80 deployment控制器
(大部分配置与ReplicaSet相似)
用法
kubectl explain deploy/deployment:
spec <Object>
revisionHistoryLimit <integer> #保存多少个历史版本,默认是10个
paused <boolean> #开始更新部署时先暂停
strategy <Object> #更新策略
type <string>
#<string>:支持三类更新
Recreate:重建试更新,删一个创建一个
RollingUpdate:滚动更新,为默认更新方法,更新策略需要配置在上级配置的RollingUpdate中
rollingUpdate <Object> #定义滚动更新策略,需要type配置为RollingUpdate才会生效
maxSurge <string> #设置可以超出期望的副本数几个,<string>可以是数字也可以是百分比,默认25%
maxUnavailable <string> #设置最多有几个不可用,<string>可以是数字也可以是百分比,默认25%
示例:
apiVersion: apps/v1
kind: Deployment
metadata:
name: myapp-deploy
namespace: default
spec:
replicas: 3
selector:
matchLabels:
app: myapp
release: canary
template:
metadata:
labels:
app: myapp
release: canary
spec:
containers:
- name: myapp
image: ikubernetes/myapp:v2
ports:
- name: http
containerPort: 80DaemonSet控制器
(配置文件除了没有replicas,其他大部分与deployment控制器类似,也支持滚动更新策略)
用法
kubectl explain ds/DaemonSet:
spec <Object>
updateStrategy <Object>
rollingUpdate <Object>
maxUnavailable <string> #最多几个不可用,因为每个节点只能部署一个,没有maxSurge选项
type <string> #Can be "RollingUpdate" or "OnDelete"(删除时更新). Default is RollingUpdate.
示例:
apiVersion: apps/v1
kind: DaemonSet
metadata:
name: filebeat-ds
namespace: default
spec:
selector:
matchLabels:
app: filebeat
release: stable
template:
metadata:
labels:
app: filebeat
release: stable
spec:
containers:
- name: filebeat
image: ikubernetes/filebeat:5.6.5-alpine
env:
- name: REDIS_HOST
value: redis.default.svc.cluster.local
- name: REDIS_LOG_LEVEL
value: info 资源配置清单中service配置:
用法:
kubectl explain svc/service:
clusterIP <string>
#<string> :service的IP,不需要指定因为在集群中会自动分配,如果要指定要确定不要导致ip冲突;也可以设置为None,没有集群IP又称为无头sevice。通过service域名直接解析到后端Pod上
spec <Object>
ports <[]Object>
name <string>
nodePort <integer> #指定节点上的端口,一般不用指定因为只有service类型时nodePort时节点端口才有用
port <integer> -required- #指定对外提供服务的端口
targetPort <string> #容器的端口
protocol <string> #协议,默认为TCP
selector <map[string]string>
type <string>
externalName <string> #type为ExternalName Service时才会有效,解析结果应该是A记录,用的比较少
sessionAffinity <string> #会话粘性,默认情况是不做粘性的,如果设置为ClientIP则来自同一个客户端IP的请求始终调度到同一个后端Pod上去
#<string>: "ClientIP" 或 "None"
ingress Control
为什么用ingress Control
service是一个四层调度器因此有个缺陷,它只是工作在TCP/IP协议栈或者OS模型的第四层。因此如果用户访问的是https请求,服务用service代理时CA证书、私钥无法配置,更无法调度https的这种七层协议,这种情我们只能在每个后端服务器配置https。因为https的特点是即贵且慢所以我们需要尽量在调度器上卸载所以需要七层调度器,使在外网时使用https,内网使用http。
解决方案一:
设置一个独特的pod运行在七层用户空间正常的应用程序例如nginx,当用户试图访问某一服务时,我们不让它到达前端service而先到七层代理pod。pod与pod直接可以通过podIP同一网段直接通信完成反向代理
访问路径:集群外部client进行https访问 →负载均衡器(Lbaas)→ NodeIP:NodePort→ClusterIP:ServicePort → PodIP:containerPort(七层代理服务卸载https并把http请求直接反向代理给后端)→PodIP:containerPort(真正提供服务的容器)
弊端:多级调度导致性能低下
方案二:ingress Control
直接让七层代理pod共享节点的网络名称空间并监听宿主机地址端口。而且使用DaemonSet控制器启动此容器,并设置节点污点从而控制节点个数使这些节点只运行一个七层代理服务容器。这个代理pod在K8s上又被称为:ingress Control
访问路径:集群外部client进行https访问→四层负载均衡器→NodeIP:NodePort(Pod中七层代理服务)→PodIP:containerPort(真正提供服务的容器)
后端有多组web,每组提供不同功能的情况下:
方案一:例如nginx代理可以用不同主机名或端口设置4个虚拟主机每个主机代理一组后端
方案二:通过URL映射,每一个路径映射到一组后端服务
七层代理服务:
- HAProxy:用的比较少
- nginx:默认
- Traefik:面向微服务的开发的,能监控自身配置文件变化并自动重载配置文
- Envoy:servicemesh网络中比较倾向的,微服务用的比较多,也能监控自身配置文件变化并自动重载配置文件
ip不固定问题
在七层代理服务器假如是nginx反代至后端时,因为后端时pod容器所以ip不固定,如何修改nginx上upsteam确认后端IP
解决方案:
在他们中间层设置一个service,但此service不做代理使用只是负责给后端资源分组
K8S上有个ingress资源(注意与ingress Control区分),他可以读取每个service上所属的组包含的后端的IP定义成upsteam server并注入到nginx配置文件中并触发nginx重载配置文件
安装和部署ingress-nginx Control
(注意k8s不能低于1.19)
kubectl apply -f https://raw.githubusercontent.com/kubernetes/ingress-nginx/controller-v1.8.2/deploy/static/provider/cloud/deploy.yaml
#ingress资源创建后会自动注入配置可以通过交互命令查看ingress-nginx中nginx配置信息
资源配置清单中ingress配置:
(创建ingress资源后,会根据配置自动注入到ingress Control中)
kubectl explain ingress:
apiVersion <string>
kind <string>
metadata <Object>
annotations <map[string]string> #声明用哪种代理
spec <Object>
backend <Object> #定义后端
serviceName <string> #定义后端service
servicePort <string> #后端service端口
rules <[]Object> #定义调度规则
host <string> #通过虚拟主机调度
http <Object>
paths <[]Object> -required- #通过url路径映射调度
tls:定义https时定义
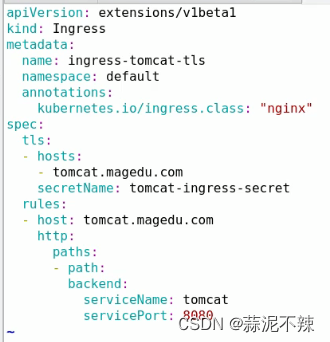
ingress配置清单示例(https协议)
- 1.用openssh生成一对自谦证书
- 2.创建secret资源对象用来转换自签证书格式
kubectl create secret tls tomcat-ingress-secret --cert=tls.crt --key=tls.key
#tls:表示对象类型
#tomcat-ingress-secret 自定义名字
#--cert=tls.crt --key=tls.key :指明秘钥对文件
- 3.创建ingress
#tls为https协议,secretName为指定秘钥认证的secret,tomcat.magedu.com为后端名称虚拟主机,myapp为后端提供服务所属的service,80为后端所提供服务的端口号于service无关
存储卷
同一个pod中的多个容器可以共享一个存储卷:因为存储卷不是属于容器而是属于pod,同一个pod中的容器底层复制的同一个基础架构镜像:pause。
存储卷种类:
- 非持久存储:
emptyDir:作为容器中临时空目录使用,映射为宿主机目录或者内存,容器删除此目录中的数据也会被删除
hostPath:宿主机目录做映射,pod变更重新创建时需要调度到同一个宿主机上才能实现持久存储
gitRepo:类似与emptyDir,只不过是有内容的。在创建pod时会把指定的一个git仓库内容克隆下来并挂载。如果内容发生改变并不会自动进行推送或远程同步,要实现此功能需要一个辅助容器Sidecar
- 持久存储:
传统网络存储:SAN(iscsi)、NAS(NFS、CIFS)
分部式存储(文件系统级别、块级别):glusterfs,rbd,ceph
- 云存储:
ebs、Azure Disk
资源配置清单中pod存储卷配置:
kubectl explain pod.spec
volumes <[]Object> #在pod中定义存储卷
- name
emptyDir <Object> #emptyDir存储卷
medium <string>
sizeLimit <string>
hostPath <Object> #hostPath存储卷
path <string> -required- #指明宿主机上的路径
type <string>
#DirectoryOrCreate:挂载的宿主机上的目录如果不存在则创建
#Directory:宿主机上必须存在此目录
#FileOrCreate:挂载一个宿主机文件如果不存在则创建
#File:宿主机必须存在此文件
#Socket
#CharDevice:字符类型设备文件
#BlockDevice:块设备文件
nfs <Object> #nfs存储卷,可以实现多个pod同时挂载同一个共享存储
path <string> -required- #nfs共享路径
readOnly <boolean>
server <string> -required- #nfs服务器地址
containers
volumeMounts <[]Object> #在容器中挂载存储卷
- mountPath <string> -required-
name <string> -required-
readOnly <boolean>
ubPathExpr <string>
示例
- 示例1(emptyDir存储卷):
定义一个pod中两个容器,并定义pod中存储卷并分别挂载到两个容器中,第二个容器输入内容到html并作为第一个nginx容器的主页显示。(可以通过curl 这个容器进行验证) 
- 示例2(hostPath存储卷)
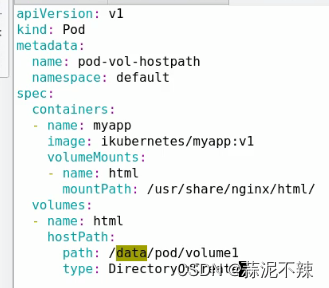
- 示例3(NFS共享存储)
需要各个节点都要安装nfs-utils

PVC
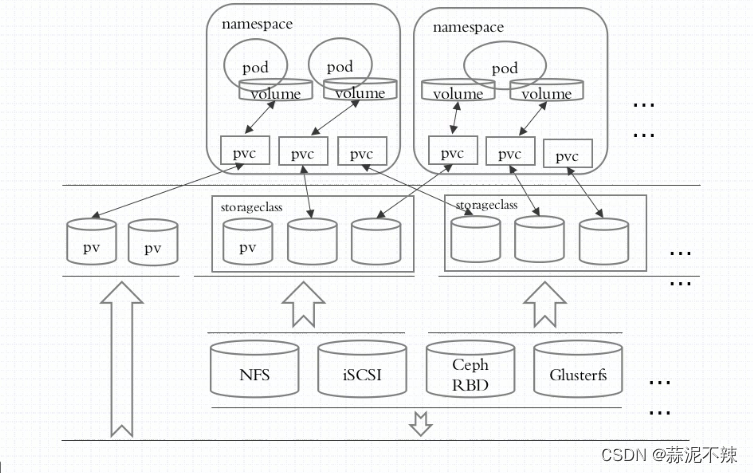
作用和实现逻辑
PVC:持久化卷声明.把k8s和存储卷剥离开,对于真正使用存储的用户不需要关心底层的存储实现细节降低使用者的门槛,只需要直接使用 PVC 即可。PVC 是用户存储的一种声明,PVC 和 Pod 比较类似,Pod 消耗的是节点,PVC 消耗的是 PV 资源,Pod 可以申请 CPU 和内存,而 PVC 可以申请特定的存储空间和访问模式。
存储逻辑:如上图所示在pod中只需要定义存储卷并指定存储大小,而这个存储卷必须与当前名称空间的pvc建立直接绑定关系,pvc必须与pv建立直接绑定关系,pv是真正某个存储设备上的存储空间。所以pvc与pv是k8s之上的抽象的、标准的资源,他俩的创建方式跟在k8s之上创建service等没啥区别。存储工程师把底层存储每一个存储空间先划割好,k8s管理员他需要把每一个存储空间给映射到系统上做成pv和创建好pvc。用户只需要自己定义pod,在pod中定义使用pvc。而在pvc与pv之间,当pvc不被调用时是没有用的空载的,当有人调用pvc时他需要与pv绑定起来,相当于pvc上的数据放到pv上的。pvc要绑定哪一个pv取决于pod创建者定义的存储空间的大小、访问模型(一人读一人写、多人读多人写等)、标签等,如果找不到合适的pv则会阻塞挂起。pvc与pv是一一对应的关系,如果某个pv把pvc占用了就不能被其他pvc占用了。而一个pvc创建后就相当于一个存储卷,此存储卷却可以被多个pod所访问,需不需要支持多个pod访问是根据其定义的访问模式决定
资源配置清单中pod定义使用pvc
kubectl explain pod.spec.volumes
persistentVolumeClaim <Object>
claimName <string> -required- #pvc名称
readOnly <boolean>
资源配置清单中定义pvc
kubectl explain pvc
apiVersion: v1
kind: PersistentVolumeClaim
metadata <Object>
spec <Object>
accessModes <[]string> #访问模型必须是pv访问模型的子集
#访问模型帮助文档
resources <Object> #资源限制。设置存储空间最少多大,例如设置为10G则要找10G以上的pv进行绑定
limits <map[string]string> #限制使用的最大资源
requests <map[string]string> #指定请求的资源大小
selector <Object> #标签选择器,通过标签选择pv
storageClassName <string> #存储类名称
volumeMode <string> #存储卷的模式,通过这个可以做类型限制
volumeName <string> #卷名称,一对一精确绑定。如果不指定就是从一大堆符合条件的pv中选择一个最佳匹配进行绑定
资源配置清单中定义pv
#与定义pod中的存储卷用法类似
#注意配置时定义pv的时候一定不要加名称空间,因为pv是集群级别的不属于名称空间下的所有名称空间都可以用,但是pvc是属于名称空间下的。名称空间也是集群级别的资源
kubectl explain pv
apiVersion: v1
kind: PersistentVolume
metadata <Object>
spec <Object>
accessModes <[]string> #指定访问模型,是个列表所以可以定义多种
ReadWriteOnce #单路读写,简写RWO
ReadOnlyMany #多路只读,简写ROX
ReadWriteMany #多路读写,简写 RWX
persistentVolumeReclaimPolicy <string> #回收策略,pvc被释放后被绑定的pv里面的数据处理方式
Retain #保留数据
Delete #直接删除pv
Recycle #回收数据,把数据情况吧pv置为空闲状态
capacity <map[string]string> #指定输出多少空间
nfs <Object>
path <string> -required-
readOnly <boolean>
server <string> -required-
示例 NFS实现pvc
- nfs配置
/data/volumes/v1 172.20.0.0/16(rw,no_root_squash)
/data/volumes/v2 172.20.0.0/16(rw,no_root_squash)
/data/volumes/v3 172.20.0.0/16(rw,no_root_squash)
/data/volumes/v4 172.20.0.0/16(rw,no_root_squash)
/data/volumes/v5 172.20.0.0/16(rw,no_root_squash)
- pv配置

- pod配置pvc

查看是否有pv被绑定: kubectl get pv
StorageClass
StorageClass的作用和实现逻辑
- 问题:
pvc申请的时候未必就有现成的pv符合其指定的条件,k8s和存储工程师也不可能时时在线处理
- 解决逻辑:
可以把各种各样的底层存储尚未做成pv的存储空间都拿出来再根据各种存储的性能(如IO等)、质量(如冗余、价钱等)做一个分类并定义好存储类(StorageClass)。pvc在申请pv时不针对某个pv而是针对某个存储类(StorageClass),可以动态创建出一个符合要求的pv来,借助这么一个中间层来完成资源的分配。
注意:存储设备必须要支持restful风格请求接口
- 工作逻辑
例如ceph有好多的本地磁盘一共凑出了4个PB的空间,这些空间需要再划分成它的子单位image才能拿来使用,每个image相当于一个磁盘或一个分区。当试图请求一个20G的pv时,通过ceph的restful接口请求立即划分出一个20G大小的image并格式化完成通过ceph导出来,然后在集群中定义成20G大小的pv,接着跟pvc绑定
configmap/secret
(configmap中存放的都是键值数据)
- 问题:
同一个镜像因为需求不同需要不同的配置文件因而要创建多个镜像或多个节点同时需要修改配置文件,就需要将所有节点配置修改并加载一遍
- configmap核心作用:
让配置信息与容器镜像解耦,从而增强应用的可移植性和可复用性
- configmap用法:
相当于k8s的配置中有两个用法:
(1)使用env的valueFrom方式引用configmap中的数据作为变量值,这种方式只在容器启动注入时有效
kubectl explain pod.spec.containers.env.valueFrom.configMapKeyRef
key <string> -required-
name <string>
optional <boolean> #表示引用的configmap中的变量是否必须存在,默认为必须存在并读取成功否则容器启动失败
(2)可以直接作为存储卷挂载,挂载的位置正好是程序读取配置文件的位置,这种方式可以实时更新配置;挂载之后表现形式为键名为挂载目录下面的文件名,键值为文件内容。
kubectl explain pod.spec.volumes.configMap
items <[]Object> #指定键值
key <string> -required- #键名
mode <integer> #指定文件权限
path <string> -required- #指定键值所对应的文件名
name <string> #configmap资源的名字
资源配置清单中configmap的配置
(configmap 是名称空间下的资源)
kubectl explain configmap/cm:
apiVersion apps/v1
binaryData <map[string]string> #二进制格式的键值对
data <map[string]string> #键值对
immutable <boolean>
kind ConfigMap
metadata <Object>
创建configmap
示例1:直接添加键值
[root@master ~]# kubectl create cm nginx-cm --from-literal=nginx=80 --from-literal=name=www.cj.com
configmap/nginx-cm created
[root@master ~]# kubectl get cm
NAME DATA AGE
kube-root-ca.crt 1 42d
nginx-cm 2 8s
[root@master ~]# kubectl describe cm nginx-cm
Name: nginx-cm
Namespace: default
Labels: <none>
Annotations: <none>
Data
====
name:
----
www.cj.com
nginx:
----
80
Events: <none>
[root@master ~]#
示例2:把一个文件作为数据
[root@master ~]# mkdir configmap
[root@master ~]# cd configmap/
[root@master configmap]# vim www.conf
[root@master configmap]# cat www.conf
server {
server_name www.cj.com;
listen 80;
root /data/web/html;
}
[root@master configmap]# kubectl create cm www.conf --from-file=./www.conf
configmap/www.conf created
[root@master configmap]# kubectl get cm www.conf -o wide
NAME DATA AGE
www.conf 1 44s
[root@master configmap]# kubectl get cm www.conf -o wide -o yaml
apiVersion: v1
data:
www.conf: "server {\n\tserver_name www.cj.com;\n\tlisten 80;\n\troot /data/web/html;\n}\n"
kind: ConfigMap
metadata:
creationTimestamp: "2024-01-10T05:51:59Z"
managedFields:
- apiVersion: v1
fieldsType: FieldsV1
fieldsV1:
f:data:
.: {}
f:www.conf: {}
manager: kubectl-create
operation: Update
time: "2024-01-10T05:51:59Z"
name: www.conf
namespace: default
resourceVersion: "3453573"
uid: 555b4e08-efd0-4ee6-98b1-2bd53e118684
[root@master configmap]# 创建pod并引用configmap
示例1:环境变量注入方式
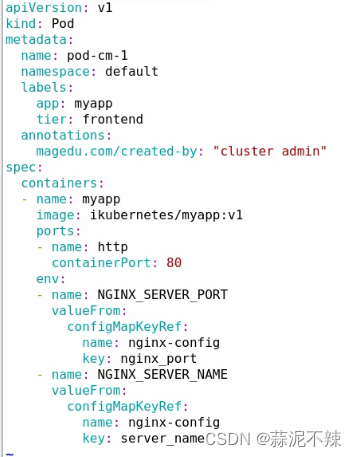
验证:
kubectl exec -it pod-cm-1 -- /bin/sh #进入容器
#printenv #查看两个变量是否存在
示例1:configmap以存储卷方式挂载
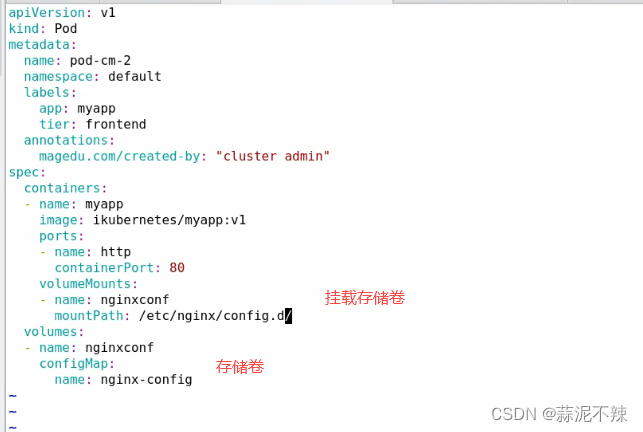
验证:
kubectl edit cm nginx-config #修改键值
进入容器查看目录下的键值是否修改,可能会慢几秒中因为edit修改完之后需要先同步到API server 中然后再同步到pod中。
secret
与configmap唯一不同是不是明文显示,也非加密只是另一种编码方式
kubectl主要有三种类型:
kubectl create secrete --help
docker-registry #节点需要向私有registry访问下载镜像时需要认证,就可以通过它进行认证
generic #通用secret编码功能
tls #保存私钥和证书
statefulset控制器
有状态应用副本集的前提或要求:
(1)稳定且唯一的网络标识符:节点名称
(2)稳定且持久的存储
(3)有序、平滑的部署和扩展
(4)有序、平滑的终止和删除
(5)有序的滚动更新
三个组件组成
(1)无头service
为了保证pod节点及表示符稳定持久有效,需要无头service来确保解析的名称是直达后端podIP地址。
(2)statefulset控制器
(3)存储卷申请模版
每个节点都应该有自己专用的存储,所以每个节点创建时要自己自动申请pv。当pod被删除重建时pv不会被删除,并且新pod会有同样的标识符并关联同一个pv
资源配置清单中statefulset的配置
kubectl explain sts:
apiVersion apps/v1
kind StatefulSet
metadata <Object>
spec <Object>
replicas <integer> #有几个副本
selector <Object> -required- #标签选择器
serviceName <string> -required- #所关联的无头service
template <Object> -required- #定义pod模版和关联某个存储卷
volumeClaimTemplates <[]Object> #由它动态生成pvc
updateStrategy <Object> #更新策略
type <string>
rollingUpdate <Object> #自定义更新策略
partition <integer> #分区更新,默认为0。如果定义为5则表示大于等于5的标识节点将会被更新
示例
定义无头service

定义statefulset

statefulset扩缩容和升级
扩容
是有序的扩容,例如先扩第4个再扩第5个
缩容
是逆序的缩容,例如先删第5个在删第4个
扩缩容实现方式
(1)kubectl scale 命令
(2)kubectl patch -p 打补丁
升级
kubectl set image
k8s认证及serviceaccount
客户端包括kubectl等要访问管理端入口API service需要三步
( 因为k8s是高度模块化的,所以三步认证机制都可以通过各种插件自定义实现)
- 1. 认证,有多种方式:(可以同时存在,只要一种认证通过就认证成功)
(1):交换域共享密钥
(2):ssl认证。不但可以认证还可以确认服务器身份,所以客户端与服务端都需要有证书做双向认证
- 2. 授权检测,有多种方式:(可以同时存在,只要一种认证通过就认证成功)
RBAC授权检测机制:基于角色的访问控制机制,默认已启用
- 3. 准入控制:检测如果涉及到其他容器的操作是否被允许
账号信息与资源访问
访问API server的客户端有两种:(所以API server需要两个地址的证书 )
集群外部客户端:通过API server对外的监听地址进行通信,客户端无论在哪只要安装有对应证书都可以进行远程操作K8S
k8s容器中服务:通过API server专用于集群内的地址进行通信,此地址实际是由svc提供并转发给外部端口,而此时API server需要两个地址的证书来验证身份,容器的证书由pod提供而非容器中的服务。
pod中要访问API service时需要指定要加载的serviceAccountName资源的配置:
kubectl explain pod.spec.serviceAccountName
查看API service内部访问地址:
[root@master ~]# kubectl get svc
NAME TYPE CLUSTER-IP EXTERNAL-IP PORT(S) AGE
kubernetes ClusterIP 10.96.0.1 <none> 443/TCP 49d
[root@master ~]# kubectl describe svc kubernetes
Name: kubernetes
Namespace: default
Labels: component=apiserver
provider=kubernetes
Annotations: <none>
Selector: <none>
Type: ClusterIP
IP Families: <none>
IP: 10.96.0.1
IPs: 10.96.0.1
Port: https 443/TCP
TargetPort: 6443/TCP
Endpoints: 192.168.0.11:6443
Session Affinity: None
Events: <none>
事实上每个pod都要与API server通信,只不过权限有大有小,可以进行查看:
[root@master ~]# kubectl describe pod myapp-deploy-58b7f5cf77-fnfzn
...
Volumes:
default-token-2rs7k:
Type: Secret (a volume populated by a Secret)
SecretName: default-token-2rs7k #证书由Secret提供
...
- API service通过识别用户的哪些信息来确认授权:
user: username,uid
group:
extra:附加信息
- 容器外部客户端通过restful接口访问API server进行增删改查,通过路径确认资源位置
Request path:
#API server所在节点:接口/api接口/api组/api版本/指定要访问名称空间/名称空间名字/指明要访问deployment控制器/控制器名字/,其中/api接口/api组/api 中的核心群组可以直接使用/api/v1这个特殊连接其他都需要apis
http://172.20.0.70:6443/apis/apps/v1/namespaces/default/deployments/myapp-deploy/
- 测试:
因为https访问APIservice需要认证,所以可以在已经认证的客户端上执行代理命令监听一个端口,这样http就可以访问这个端口,然后通过这个代理反向转发到API service:
kubectl proxy -p 8080
curl http://localhost:8080/api/v1/namespaces
curl http://localhost:8080/apis/apps/v1/deployments
serviceaccount
一个serviceaccount相当于一个账号一般用于集群内部,k8s在创建时会自动生成一个serviceaccount和关联的secrets,k8s中的各种组件和创建的pod都是通过它来访问API server的,不过权限一般都不大。
我们可以手动创建一个serviceaccount,但默认没有权限,需要RBAC等插件授权,但不能使用k8s中默认的那个账号,不然所有加载这个serviceaccount的pod都有相同的权限。每个serviceaccount都关联一个secrets。所以pod在请求镜像访问私有registry时的认证也可以指定一个serviceaccount这样更加安全。
查看在pod中配置serviceaccount:
kubectl explain pod.spec.serviceAccount
创建serviceaccount方式:
kubectl create serviceaccount NAME [--dry-run=server|client|none] [options]
config
config中配置了哪些账号可以访问哪些集群,一般用于集群外部
相关命令:
kubectl config --help
view #打印
配置内容包含四项:(上下文相关设置了哪些用户访问哪些集群)
集群列表:
上下文列表:
当前所用用户
用户列表:
[root@master ~]# kubectl config view
apiVersion: v1
clusters:
- cluster:
certificate-authority-data: DATA+OMITTED
server: https://192.168.0.11:6443
name: kubernetes
contexts:
- context:
cluster: kubernetes
user: kubernetes-admin
name: kubernetes-admin@kubernetes
current-context: kubernetes-admin@kubernetes
kind: Config
preferences: {}
users:
- name: kubernetes-admin
user:
client-certificate-data: REDACTED
client-key-data: REDACTED
示例:通过API server信任的ca创建一个可以连接API server的账号
注意:
etc/kubernetes/pki中所有证书都是k8s信任的,都可连入集群
证书的持有者就是账号名
操作
(umask 077; openssl genrsa -out test.key 2048) #生成证书
openssl req -new -key test.key -out test.csr -subj "/CN=test" #生成证书请求,其中/CN=用来指定证书名字,同样也是k8s账号名字
openssl x509 -req -in test.csr -CA ca.crt -CAkey ca.key -CAcreateserial -out test.crt -days 365 #根据k8s信任的CA公钥和私钥(ca.crt、ca.crt)进行签证,-CAcreateserial表示CA随机生成一个序列号
openssl x509 -in test.crt -text -noout #查看证书信息,因为证书是由同一个K8S集群的CA创建的证书所以认证没有问题
###############
通过config认证为连接K8S的信息
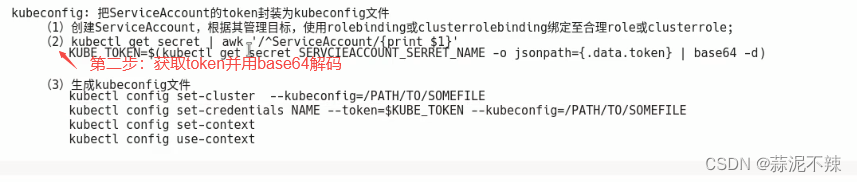
kubectl config set-cluster mycluster --kubeconfig=/tmp/test.conf --server="https://172.20.0.10:6443" --certificate-authority=/etc/kubernetes/kpi/ca.crt --embed-certs=true #修改添加config资源中的集群列表
kubectl config set-credentials test --client-certificate=./test.crt --client-key=./test.key --embed-certs=true #修改添加config资源中的用户列表
kubectl config set-context test@kubernetes --cluster=kubernetes --user=test #修改添加config资源中的上下文列表
##############
#切换当前上下文账号为创建的账号
kubectl config use-context test@kubernetes #因为没有授权所以没有权限RBAC授权
RBAC:基于角色的访问控制,可以让一个用户扮演一个角色,因而拥有了角色的权限。
要实现RBAC授权有以下几部分:
users:serviceaccount和真正有证书的集群外客户端
Role:名称空间级别下配置了对那些对象可以做哪些操作和角色绑定哪些用户
rolebinding:名称空间级别下定义了哪些用户和哪些角色绑定
clusterrole:集群级别
clusterrokebinding:集群级别
有四种绑定方式:
rolebinding配置了Role:表示在当前名称空间级别
clusterrokebinding配置了 clusterrole:集群级别,表示绑定的用是可以访问所有名空间的所有pod
clusterrokebinding配置了Role:名称空间级别,优点一些环境下可以用一个clusterrokebinding配置多个Role,从而减少了rolebinding要配置多次的麻烦
rolebinding配置了clusterrole:名称空间级别,也是减少需要多次配置role的步骤
创建role/clusterrole资源方法:
role:
kubectl create role NAME --verb=verb --resource=resource.group/subresource [--resource-name=resourcename] [--dry-run=server|client|none] [options]
clusterrole:
kubectl create clusterrole NAME --verb=verb --resource=resource.group [--resource-name=resourcename] [--dry-run=server|client|none] [options]
示例:
[root@master ~]# kubectl create role foo --verb=get,list,watch --resource=pods --dry-run -o yaml
W0220 13:42:30.346333 51866 helpers.go:553] --dry-run is deprecated and can be replaced with --dry-run=client.
apiVersion: rbac.authorization.k8s.io/v1
kind: Role
metadata:
creationTimestamp: null
name: foo
rules:
- apiGroups:
- ""
resources:
- pods
verbs:
- get
- list
- watch
创建rolebinding/clusterrolebinding资源语法:
rolebinding:
kubectl create rolebinding NAME --clusterrole=NAME|--role=NAME [--user=username] [--group=groupname] [--serviceaccount=namespace:serviceaccountname] [--dry-run=server|client|none] [options]
clusterrolebinding
kubectl create clusterrolebinding NAME --clusterrole=NAME [--user=username] [--group=groupname]
[--serviceaccount=namespace:serviceaccountname] [--dry-run=server|client|none] [options]
示例:
[root@master ~]# kubectl create rolebinding admin --clusterrole=admin --user=user1 --user=user2 --group=group1 --dry-run -o yaml
W0220 14:06:42.806307 68411 helpers.go:553] --dry-run is deprecated and can be replaced with --dry-run=client.
apiVersion: rbac.authorization.k8s.io/v1
kind: RoleBinding
metadata:
creationTimestamp: null
name: admin
roleRef:
apiGroup: rbac.authorization.k8s.io
kind: ClusterRole
name: admin
subjects:
- apiGroup: rbac.authorization.k8s.io
kind: User
name: user1
- apiGroup: rbac.authorization.k8s.io
kind: User
name: user2
- apiGroup: rbac.authorization.k8s.io
kind: Group
name: group1
dashboard安装与认证
安装
wget https://raw.githubusercontent.com/kubernetes/dashboard/v2.7.0/aio/deploy/recommended.yaml
vim recommended.yaml
#编辑一下代码
kind: Service
apiVersion: v1
metadata:
labels:
k8s-app: kubernetes-dashboard
name: kubernetes-dashboard
namespace: kubernetes-dashboard
spec:
type: NodePort # 新增一行
ports:
- port: 443
targetPort: 8443
nodePort: 30010 # 新增一行
selector:
k8s-app: kubernetes-dashboard
创建账号并授权
- 方法一:通过serviceaccount认证授权
创建账号
kubectl create serviceaccount dashboard-admin -n kubernetes-dashboard
授权
kubectl create clusterrolebinding dashboard-admin-rb --clusterrole=cluster-admin --serviceaccount=kubernetes-dashboard:dashboard-admin
找到对应的secrets资源
kubectl get secrets -n kubernetes-dashboard | grep dashboard-admin
查看token
kubectl describe secrets dashboard-admin-token-htpjd -n kubernetes-dashboard
浏览器访问 :https://node:30010 复制上token登录
- 方法二通过config文件授权
配置网络插件flannel
CNI
kubernetes四种网络通信:
(1)容器间通信:同一个pod内的多个容器间通过lo通信
(2)pod通信:k8s要求是从Pod IP 直接到Pod IP的通信之间不能进行snat等
(3)Pod与service通信
(4)service与集群外部客户端通信
K8S通过CNI(定义了容器网络接口规范)和遵循此规范实现的常用插件:
flannel:比较简单但是不支持网络策略,名称空间直接不会进行网络隔离
calico
canel
kube-router
加载插件方式:通过读取目录/etc/cni/net.d/下的配置文件加载网络插件
k8s集群在node达到上千或更多时往往会出现网络瓶颈,就需要我们选择合适的网络插件和优化插件配置提高网络性能
配置flannel
简介:
Flannel:Flannel是一个流行的CNI插件,它使用虚拟网络覆盖技术(overlay network)来连接不同节点上的容器。Flannel支持多种后端驱动,如VXLAN、UDP、Host-GW等
查看运行的flannel:控制器为daemonset
kubectl get daemonset -n kube-flannel
查看flannel配置文件:
kubectl get configmap -n kube-flannel
配置参数
Network:配置flannel的网段,如:10.244.0.0/16
SubnetLen:指定多长的子网掩码进行切分flannel网络,从而划分子网。如:10.244.1.0/24
SubnetMin:限定子网中最小范围,如10.244.10.0/24
SubnetMax:限定子网最大范围,如10.244.100.0/24
Backend:指定pod之间通信方式,支持的有:vxlan、Host Gateway、UDP
vxlan、Host Gateway、UDP通信方式比较
UDP:效率低一般不用
Host Gateway:主机网关通信,把所有节点的物理网卡设置为一个网段的地址作为网关使用,pod在另一个网段中通信时通过网关进行路由转发。速度比较快但物理机必须在同一个网段内
vxlan:flannel 的默认pod之间通信方式,此方式支持两种设置:
叠加网络:默认方式。优点:可以跨网段;缺点:效率较主机网关通信效率较低
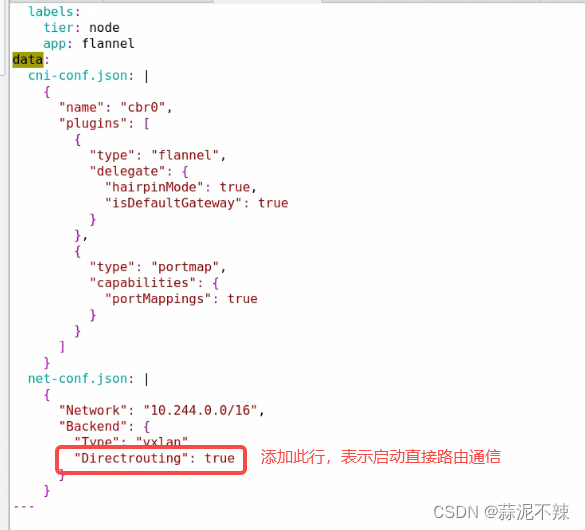
类似主机网关直接通信:默认未启用此方式,要想启动此方式需要再创建flannel网络插件时修改flannel的配置清单yaml文件如下图所示。启用后当不通网段通信时会用叠加网段;同一网段通信时会用直接网关路由通信。
优点:通信快,效率高
缺点:必须限定在同一网段内通信
基于Calico的网络策略
Calico:Calico是一个开源的网络和安全解决方案,它使用BGP协议来实现容器之间的路由。alico支持灵活的网络策略和安全规则,可用于大规模部署。默认网络:162.168.0.0/16
Canal:Canal是一个综合性的CNI插件,结合了Calico和Flannel的功能。它可以使用Flannel提供overlay网络,同时使用Calico的网络策略和安全性功能。
安装
目的:Calico实现网络策略,并且继续让flannel 实现网络功能
因为Calico需要依赖etcd,以下是使用k8s自己的etcd进行部署
curl https://raw.githubusercontent.com/projectcalico/calico/v3.27.2/manifests/canal.yaml -O
kubectl apply -f canal.yaml规则
Egress:出站规则,可以限制目标地址和端口
Ingress:入站规则,可以限制来源地址和目标端口
podSelecto:pod标签选择器,可以选择受控制的一个或一组pod
规则清单文件
kubectl explain networkpolicy
spec <Object>
egress <[]Object>
ports <[]Object>
port <string>
protocol <string>
to <[]Object>
ipBlock <Object>
namespaceSelector <Object>
podSelector <Object>
ingress <[]Object>
ports <[]Object>
from <[]Object>
podSelector <Object> -required-
policyTypes <[]string> #定义egress生效还是ingress生效;不定义则都生效,如果没定义又没设置规则则允许所有。如果定义后没有设置规则则拒绝所有
示例
示例:允许所有

示例2:设置有myapp标签的pod允许访问80端口在10.244.0.0/16网段内除10.244.1.2以外的请求入站
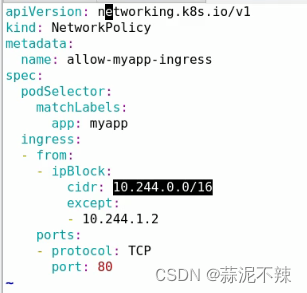
scheduler(调度器)
三步调度原理:
第一步预选过程:排除不符合的node,例如资源需求是否满足pod最低要求、端口是否已被占用、自己设置的node标签、污点等
第二步优选:基于一些列算法把所有节点属性输入进去计算每一个节点的优先级
第三步选定:pod与选定的节点绑定
污点 (Taint)和容忍 (Tolerations)
容器资源请求、资源限制
资源清单用法
kubectl explain pods.spec.containers.resources
limits <map[string]string> #容器资源上线,硬限制
requests <map[string]string>#容器请求的资源。调度器通过计算节点已分配的请求资源和剩余资源来进行调度
单位:
内存单位: E, P, T, G, M, k或Ei, Pi, Ti, Gi, Mi, Ki
cpu单位:一个逻辑核心可以分为1000个微核单位是m,也可以用小数表示。所以1m=0.001
注意:在容器中使用free或top监控内存或cpu是监控的node节点的资源利用率而不是容器限额的使用率
示例
---
apiVersion: v1
kind: Pod
metadata:
name: frontend
spec:
containers:
- name: app
image: images.my-company.example/app:v4
resources:
requests:
memory: "64Mi"
cpu: "250m"
limits:
memory: "128Mi"
cpu: "500m"
- name: log-aggregator
image: images.my-company.example/log-aggregator:v6
resources:
requests:
memory: "64Mi"
cpu: "250m"
limits:
memory: "128Mi"
cpu: "500m"Qos:服务质量
当pod设置限额时describe会自动显示Qos他的状态,有三种:
Guranteed:
同时设置内存和cpu的上线和下限,并且上限和下限值相同,这类容器会被优先运行,优先级最高
Burstable:设置了cpu和内存的的requests属性,中等优先级
BestEffort:没有设置下限或上限,最低优先级
所以当node内存不足时先杀低优先级pod,相同级别时先杀占用率接近requests的pod
k8s监控
kubernetes安装metrics-server
版本要求:

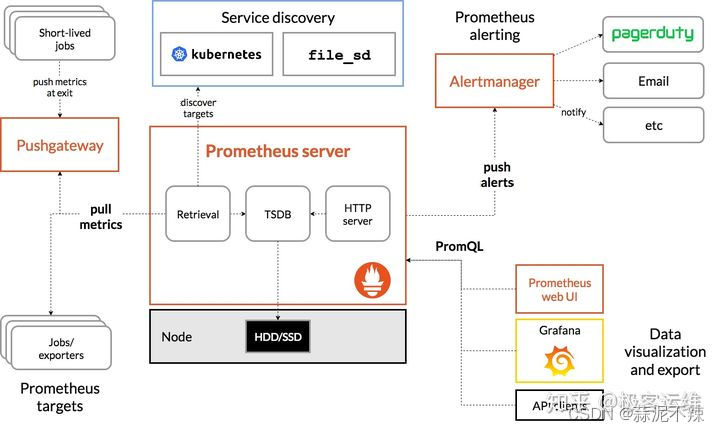
Prometheus提供给k8s自定义指标原理
node_exporter(收集数据,可自定义收集哪些数据)
——→ Prometheus(通过metrics URL来获取node上的监控指标数据的,可自定义哪些指标)
——→ PromQL(这是Prometheus提供的一个RESTful风格的,强大的查询接口,这也是它对外提供的访问自己采集数据的接口)
——→ kube-state-metrics(转换从PromQL查询到的数据格式为API能理解的格式)
——→k8s-prometheus-adpater(配置为一个自定义API server)
——→ kube-aggregator(API聚合器,然后就能通过 kubectl api-versions命令查到所聚合的自定义组)
helm原理
helm相当于Tiller的客户端
安装helm
方法一:
curl -fsSL -o get_helm.sh https://raw.githubusercontent.com/helm/helm/main/scripts/get-helm-3 && bash get-helm-3.sh
方法二:
wget https://get.helm.sh/helm-v3.14.3-linux-amd64.tar.gz
tar -xvf helm-v3.14.3-linux-amd64.tar.gz
mv linux-amd64/helm /usr/bin
helm --help
helm本地仓库目录:/root/.cache/helm/repository
char包中文件作用:
chars/目录:存放其他需要依赖的char包
requirements.yaml:描述依赖关系的文件
NOTES.txt:安装完之后提示给用户的使用信息
helm命令:
dependency :分析char包的依赖关系并下载相应的char包并放在chars目录下
EFK:K8S统一日志管理平台
必要性:kubectl log 只能实时查看日志,当k8s的pod或节点死掉需要分析日志无从下手,所以需要提前把日志收集到一个专门的日志存储里
EFK原理:
E:Elasticsearch,为了让ES运行在K8S之上,ES官方已经打包好了先关镜像并把ES自身拆为两部分master和data,这个镜像可以运行三种格式:
(1)master:负责处理轻量化的查询请求,它是ES的唯一入口,需要分部署部署和存储卷
(2)data:负责重量级的比如索引构建等请求 ,需要分部署部署和存储卷
(3)client(上载):所有节点收集来的日志由它来统一设定格式后发给ES,实际上就是logstash
F:Fluentd日志收集工具,K8S的日志存放在节点文件系统目录/var/log/pod 中,所以在k8s上部署Fluentd时需要关联这个目录
K:Kibana是ES的web界面展示工具,因为是无状态应用所以可以直接部署在k8s之上
安装
helm pull bitnami/elasticsearch
helm pull bitnami/fluentd
helm pull bitnami/kibana 与es版本号要保持一致















 453
453











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









