









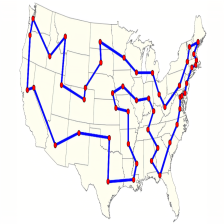
一、TSP问题概述
请参考这里
二、禁忌搜索算法
1、基本原理
- 禁忌搜索算法(Tabu Search,TS)是由美国科罗拉多大学的Fred Glover教授于1986年提出的可用于有效解决组合优化问题的一种智能优化算法。
- 禁忌搜索算法模拟人的思维方式,并引入一个禁忌表,记录下已经搜索过的局部最优解,在下一次的搜索中,有意识地避开它(但不是完全隔绝)。以此来跳出局部最优,从而最终实现全局最优。
2、参数设置
-
禁忌表(Tabu List)
禁忌表是用来存放禁忌对象的一个容器,放入禁忌表中的禁忌对象在解禁之前不能被再次搜索。 -
禁忌长度(Tabu Length)
禁忌长度就是每个禁忌表对象的生存时间,也称为禁忌对象的任期;搜索过程每迭代一次,禁忌表中各个禁忌对象的任期就自动减1,当某一禁忌对象的禁忌长度为0时,就将其从禁忌表中删除。 -
特赦准则(Aspiration Criterion)
迭代的某一步会出现候选集上的某一个元素被禁止搜索,但是若解禁该元素,则会使评价函数有所改善。
3、算法特点
(1)新解不是在当前解的邻域中随机产生,它或是优于“best so far”的解,或是非禁忌的最佳解,因此选取优良解的概率远远大于其他解。
(2)由于它的记忆功能(禁忌表)和特赦准则,且在搜索中可以接受非劣解,故有利于全局最优。
4、算法流程

三、MATLAB程序实现
1、问题描述
假设有意旅行商要拜访全国31个省会城市(不包括港澳台),从一个城市出发,需要经过,所有城市后,回到出发地。每个城市只能经过一次,要求选择一个最短路径。


2、禁忌搜索算法求解
(1)初始化参数、置空禁忌表。初始化城市规模n=31,禁忌长度TabuL=22,候选解的个数Ca=200,最大迭代次数iter_max=1000,citys表示31个城市的坐标等参数。代码如下:
load citys_data.mat;
n = size(citys, 1); % 城市数目
D = zeros(n); % 距离矩阵
Tabu = zeros(n); % 禁忌表
TabuL = round(sqrt(n*(n-1)/2)); % 禁忌长度
Ca = 200; % 候选集的个数(全部邻域解个数)
Canum = zeros(Ca, n); % 候选解集合
S0 = randperm(n); % 随机产生初始解
bestsofar = S0; % 当前最佳解
BestL = Inf; % 当前最佳解距离
iter = 1; % 初始迭代次数
iter_max = 1000; % 最大迭代次数
(2)求两两城市相互之间的距离矩阵D,随机产生一组初始解,计算适应度值(即路径距离),赋值给bestsofar。其中:
D
i
,
j
=
(
x
i
−
x
j
)
2
+
(
y
i
−
y
j
)
2
(1)
D_{i,j}=\sqrt{(x_i-x_j)^2+(y_i-y_j)^2}\tag{1}
Di,j=(xi−xj)2+(yi−yj)2(1)
D
i
,
j
=
[
D
1
,
1
D
1
,
2
⋯
D
1
,
31
D
2
,
1
D
2
,
2
⋯
D
2
,
31
⋮
⋮
⋮
D
31
,
1
D
31
,
2
⋯
D
31
,
31
]
(2)
D_{i,j}=\begin{bmatrix} D_{1,1} & D_{1,2} & \cdots & D_{1,31} \\ D_{2,1} & D_{2,2}& \cdots & D_{2,31} \\ \vdots & \vdots & & \vdots \\ D_{31,1} & D_{31,2} & \cdots & D_{31,31}\\ \end{bmatrix}\tag{2}
Di,j=⎣⎢⎢⎢⎡D1,1D2,1⋮D31,1D1,2D2,2⋮D31,2⋯⋯⋯D1,31D2,31⋮D31,31⎦⎥⎥⎥⎤(2)代码如下:
%% 计算距离矩阵
for i = 1:n
for j = i+1:n
D(i, j) = sqrt(sum((citys(i, :)-citys(j, :)).^2));
D(j, i) = D(i, j);
end
end
(3)定义初始解的邻域映射为2-opt形式,即初始解路径中随机交换两个城市。代码如下:
i = 1;
A = zeros(Ca,2); % 交换的城市矩阵,200行2列
%% 求邻域解中交换的城市矩阵
% 将一个200行2列的A阵用随机的方式填满,且没有任意两组数是相等的
while i <= Ca
r = ceil(n*rand(1,2)); % 随机交换两个城市
if r(1) ~= r(2)
A(i, 1) = max(r(1), r(2));
A(i, 2) = min(r(1), r(2));
if i == 1
flag = 0;
else
for j = 1:i-1
if A(i, 1) == A(j, 1) && A(i, 2) == A(j, 2)
flag = 1;
break;
else
flag = 0;
end
end
end
if ~flag
i = i + 1;
end
end
end
%% 产生邻域解
% 保留前BestCanum个最好候选解
BestCanum = Ca/2;
BestCa = Inf * ones(BestCanum, 4);
F = zeros(1, Ca);
for i = 1:Ca
Canum(i, :) = S0;
Canum(i, [A(i, 2), A(i, 1)]) = S0([A(i, 1), A(i, 2)]); % 交换A(i, 1)和A(i, 2)列的元素
F(i) = fitness(D, Canum(i, :));
if i <= BestCanum % 选取候选集
BestCa(i, 1) = i; % 第1列保存序号
BestCa(i, 2) = F(i); % 第2列保存适应度值(路径距离)
BestCa(i, 3) = S0(A(i, 1)); % 第3列保存交换后的数据
BestCa(i, 4) = S0(A(i, 2)); % 第4列保存交换后的数据
else
for j = 1:BestCanum % 更新候选集
if F(i) < BestCa(j, 2)
BestCa(j, 1) = i;
BestCa(j, 2) = F(i);
BestCa(j, 3) = S0(A(i, 1));
BestCa(j, 4) = S0(A(i, 2));
break;
end
end
end
end
% 对候选集按照适应度值进行升序排列
[value, index] = sort(BestCa(:, 2));
SBest = BestCa(index, :);
BestCa = SBest; % 选取前100个比较好的候选解
(4)判断选出的解是否满足特赦准则。代码如下:
%% 特赦准则
if BestCa(1,2) < BestL % 候选解比最佳值都还小,那么不管在不在禁忌表中,都是一样的操作
% 在禁忌表中,全部减1,特赦出来,放在最后;
% 不在禁忌表中,全部减1,放在最后;
BestL = BestCa(1, 2); % BestL当前最优解适配值
S0 = Canum(BestCa(1,1), :); % 最优解的替换
bestsofar = S0;
% 更新禁忌表
for i = 1:n
if Tabu(i, :) ~= 0
Tabu(i, :) = Tabu(i, :)-1;
end
end
Tabu(BestCa(1, 3), BestCa(1, 4)) = TabuL; % 更新禁忌表,把特赦的这个放在最末端
else % 候选解中最佳的解 仍然没有比目前最佳值更优,则:
for i = 1:BestCanum % 遍历候选集
if Tabu(BestCa(i, 3), BestCa(i, 4)) == 0 % BestCa就是从小到大排列的,选取第一个不在禁忌表中的解,即禁忌长度为0
S0 = Canum(BestCa(i, 1), :); % 则释放,并作为下一次迭代的初始解
for j = 1:n
if Tabu(j, :) ~= 0
Tabu(j, :) = Tabu(j, :)-1;
end
end
Tabu(BestCa(i, 3), BestCa(i, 4)) = TabuL; % 放到禁忌表最末端
break; % 立刻跳出for循环,因为已经选中不在禁忌表中的最佳解了
end
end
end
3、仿真结果


代码下载链接:
链接:https://pan.baidu.com/s/1I6c_cCdmZdtJbtg27NWpkg?pwd=9x41
提取码:9x41

















 8750
8750

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











