







简述
记录python爬虫读取豆瓣前250名记录过程,记录爬虫步骤,作个人记录使用。
准备工作
提取豆瓣电影TOP250电影名称,演员阵容,简介信息,提取站点URL为豆瓣电影排名,提取的结果会以文件形式保存下来。使用request库。
抓取分析
抓取的目标站点为豆瓣电影排名,打开之后可以查看榜单信息
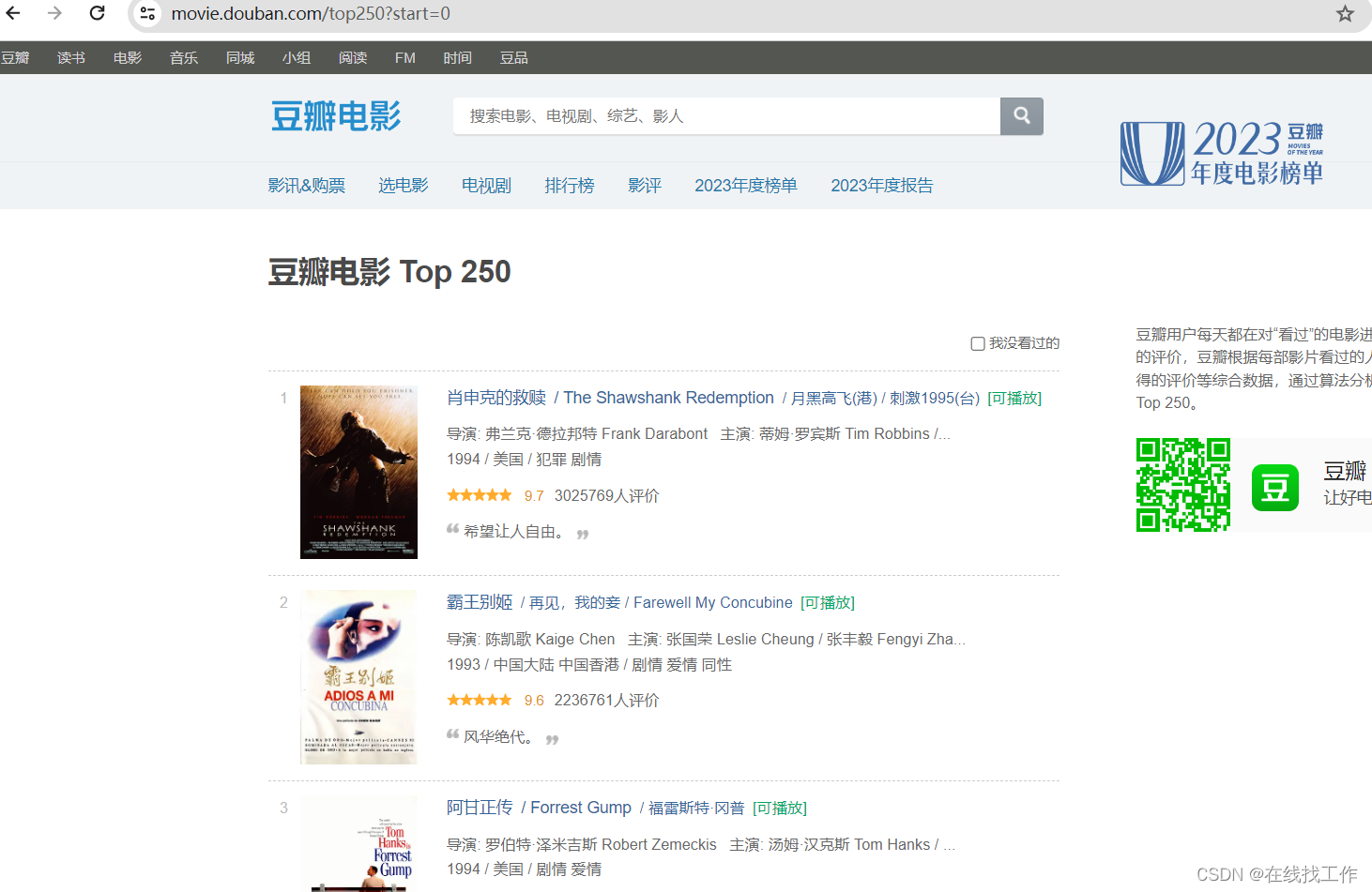
排名第一的是肖申克的救赎,页面显示的有效信息为影片名称,演员阵容,上映时间,分类,简介等内容,将页面滚动最下方,发现分页列表,选择第二页,查看URL变化,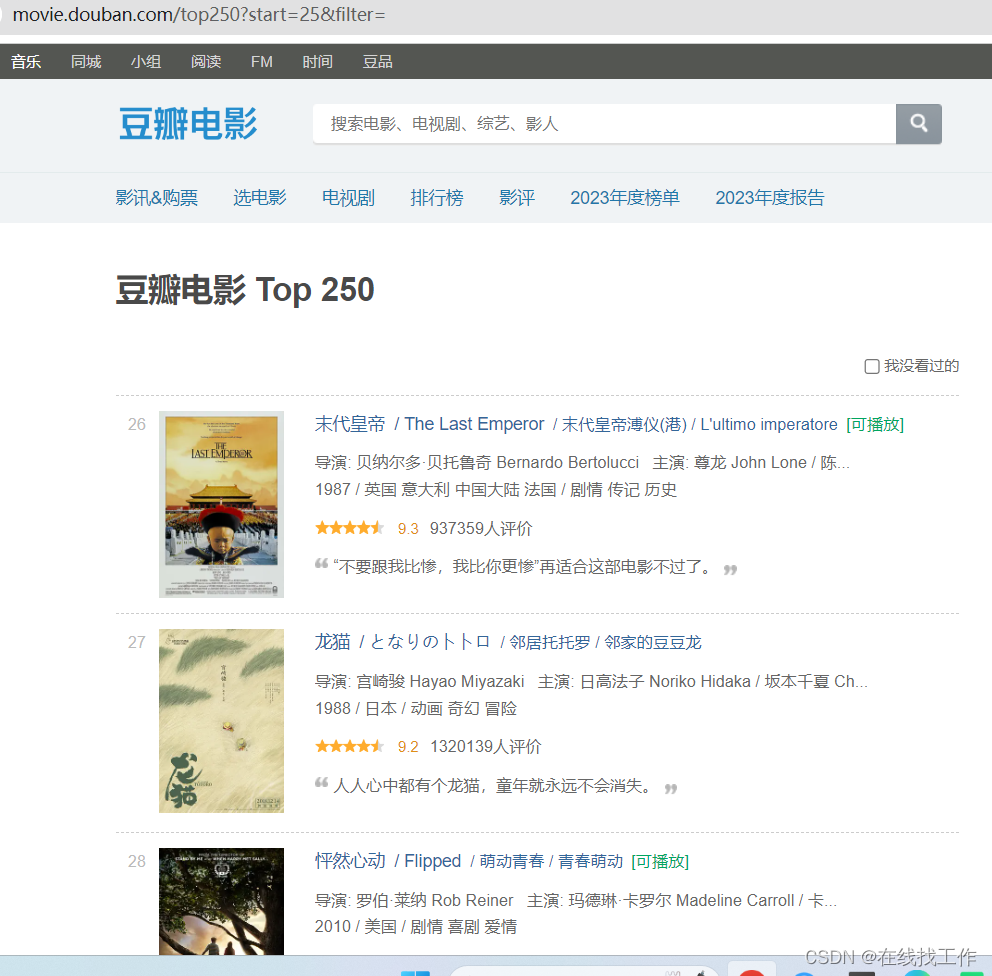
发现URL地址由https://movie.douban.com/top250?start=0变为https://movie.douban.com/top250?start=25,start从0变成25,排名从1–25到了26–50名,表示start代表偏移量,所以,想获取TOP250电影信息,需要分开请求10次,10次请求中start的值为0,25,50…初步以这样的思路去尝试。
抓取首页
首页抓取第一页的内容。实现get_one_page方法,传入url参数,将抓取的结果返回,通过main方法调用,初步代码实现:
import requests
# 页面请求
def get_one_page(url):
headers={
'User-Agent': 'Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/125.0.0.0 Safari/537.36'
}
response = requests.get(url, headers=headers)
if response.status_code == 200:
return response.text
else:
return None
# 主函数
def main():
url = 'https://movie.douban.com/top250?start=0'
html = get_one_page(url)
print(html)
main()
运行之后,应该可以看到首页内容,获取源代码后,需要解析页面,提取我们想要的信息。
正则提取
查看其中一条的源代码,
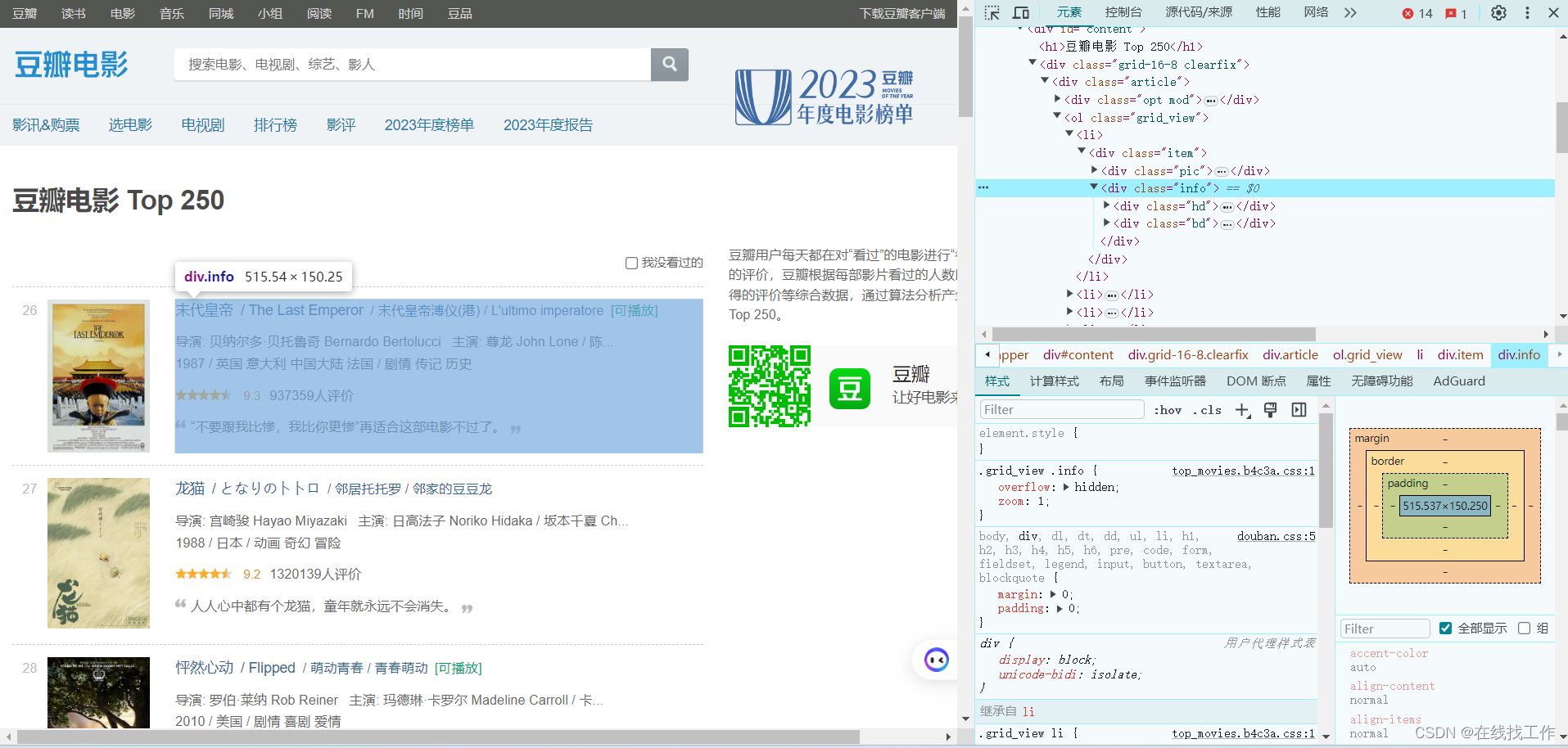
一条电影信息对应的源码是一个info节点,影片描述信息处于dd节点,用正则表达式提取电影名称信息,电影名称信息在class为title的span标签内,利用非贪婪匹配,获取电影名称信息,hd.?title.?>(.*?)
同理获取电影的描述信息,演员阵容,简介内容,定义页面解析方法parse_one_page(),通过正则表达式从结果中获取想要内容
def parse_page(html):
pattern = re.compile('hd.*?title.*?>(.*?)</span>.*?bd.*?p.*?>(.*?)<br>.*?quote.*?inq.*?>(.*?)</span>', re.S)
items = re.findall(pattern,html)
for item in items:
yield {
'电影名称': item[0],
'简介': item[1].strip(),
'描述': item[2].strip(),
}
return items
写入文件
将提取结果写入文件,通过JSON库的dumps方法实现字典的序列化,指定ensure_ascii参数为False,保证输出结果为中文
# 写入文件
def write_to_file(content):
with open('douban.txt','a', encoding='utf-8') as f:
print(type(json.dumps(content)))
f.write(json.dumps(content,ensure_ascii=False)+ '\n')
整合代码
最后,通过main()方法调用前面的方法,将结果写入文件,完整代码如下:
import json
import requests
import re
# 页面请求
def get_one_page(url):
headers={
'User-Agent': 'Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/125.0.0.0 Safari/537.36'
}
response = requests.get(url, headers=headers)
if response.status_code == 200:
return response.text
else:
return None
# 获取对应元素
def parse_page(html):
pattern = re.compile('hd.*?title.*?>(.*?)</span>.*?bd.*?p.*?>(.*?)<br>.*?quote.*?inq.*?>(.*?)</span>', re.S)
items = re.findall(pattern,html)
for item in items:
yield {
'电影名称': item[0],
'简介': item[1].strip(),
'描述': item[2].strip(),
}
return items
# 写入文件
def write_to_file(content):
with open('douban.txt','a', encoding='utf-8') as f:
print(type(json.dumps(content)))
f.write(json.dumps(content,ensure_ascii=False)+ '\n')
# 主函数
def main(offset):
url = 'https://movie.douban.com/top250?start=' + str(offset)
html = get_one_page(url)
data = parse_page(html)
for item in data:
write_to_file(item)
if __name__ == '__main__':
for i in range(10):
main(offset=i * 25)

















 3546
3546

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









