







爬取豆瓣电影排行榜
- 选择页面
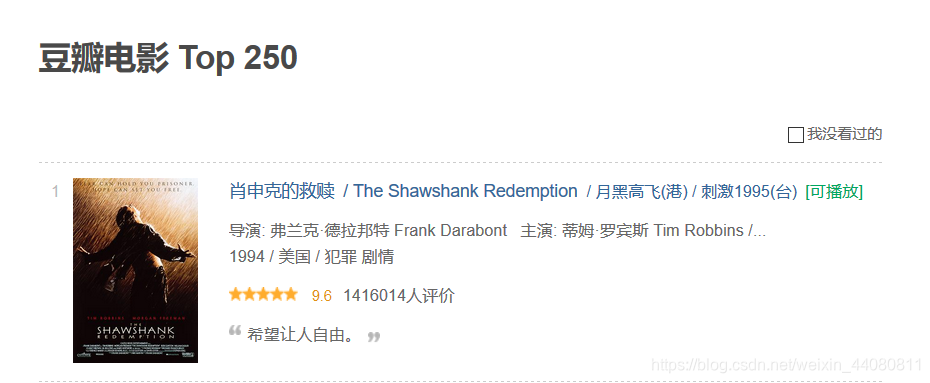
首先,我们打开豆瓣的电影排行榜的页面。网页链接:双击跳转
 2. 页面分析
2. 页面分析
接下来,我们要在这个页面提取每一部电影的详情节链接,总页码数,每一部电影的短评。
我们先来提取电影详情页的链接。
# 获取豆瓣top250每个页面下的电影豆瓣链接列表
movies_link_list = html.xpath('//li//div[@class="info"]/div[@class="hd"]/a/@href')
提取导航页的每一部电影的短评。
`# 获取每个页面下的电影的代表影评
movies_quote_list = html.xpath('//p[@class="quote"]/span[@class="inq"]/text()')`
提取电影排行榜的总页数
`total_page_num = int(html.xpath('string(//span[@class="next"]/preceding-sibling::a[1])'))`
下面,我们提取每一部电影的详细信息。
 我们提取的信息包括上图中的电影排名、名称、链接、评分、评价人数以及各个星级的评价人数,还有电影的导演,编剧、主演、类型、制片国家/地区、语言、上映日期、片长、又名和IMDb链接。代码如下:
我们提取的信息包括上图中的电影排名、名称、链接、评分、评价人数以及各个星级的评价人数,还有电影的导演,编剧、主演、类型、制片国家/地区、语言、上映日期、片长、又名和IMDb链接。代码如下:
# 获取电影排名
movie_rank = r'电影排名:{}'.format(html.xpath('string(//div[@class="top250"]/span[@class="top250-no"])'))
# 获取电影名称
movie_name = r'电影名称:{}'.format(html.xpath('string(//span[@property="v:itemreviewed"])'))
# 获取电影链接
movie_link = r'电影链接:{}'.format(movie_link)
# 获取电影评分
 最低0.47元/天 解锁文章
最低0.47元/天 解锁文章


















 1615
1615

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









