







 本文详细介绍了SMPL模型,一种用于人体建模的线性模型,包括形状参数和姿态参数的概念。SMPL通过形状混合成形和姿态混合成形来定义人体形状和动作,并通过蒙皮实现关节运动时皮肤的动态效果。形状参数用10维向量描述人体特征,姿态参数用24×3的轴角表示关节旋转。最后,文章还涉及了骨骼点位置估算和蒙皮的过程。
本文详细介绍了SMPL模型,一种用于人体建模的线性模型,包括形状参数和姿态参数的概念。SMPL通过形状混合成形和姿态混合成形来定义人体形状和动作,并通过蒙皮实现关节运动时皮肤的动态效果。形状参数用10维向量描述人体特征,姿态参数用24×3的轴角表示关节旋转。最后,文章还涉及了骨骼点位置估算和蒙皮的过程。
文章目录
前言
最近在研究神经网络和服装动画结合这一块的文章,发现很多文章的数据集都是和smpl模型相关的,所以记录一下笔记
一、SMPL概述
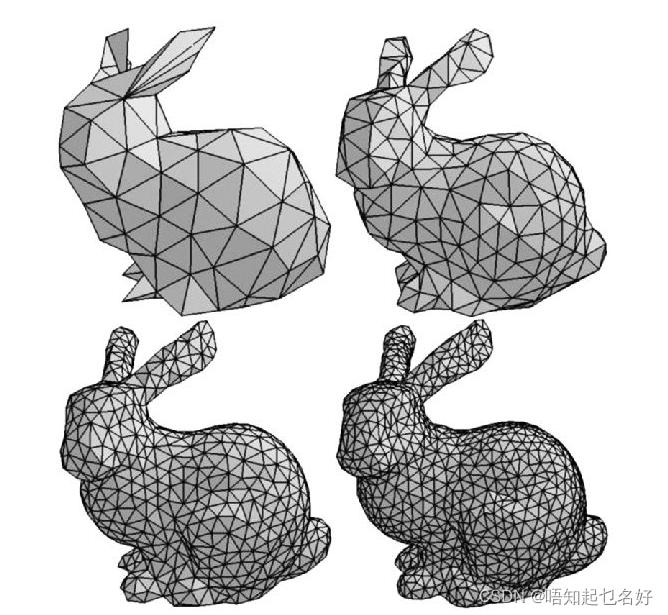
SMPL模型,其全称是Skinned Multi-Person Linear (SMPL) Model,Skinned表示这个模型不仅仅是骨架点了,其是有蒙皮的,其蒙皮通过3D mesh表示。3D mesh如下图所示,指的是在立体空间里面用三个点表示一个面,可以视为是对真实几何的采样,其中采样的点越多,3D mesh就越密,建模的精确度就越高(这里的由三个点组成的面称之为三角面片)
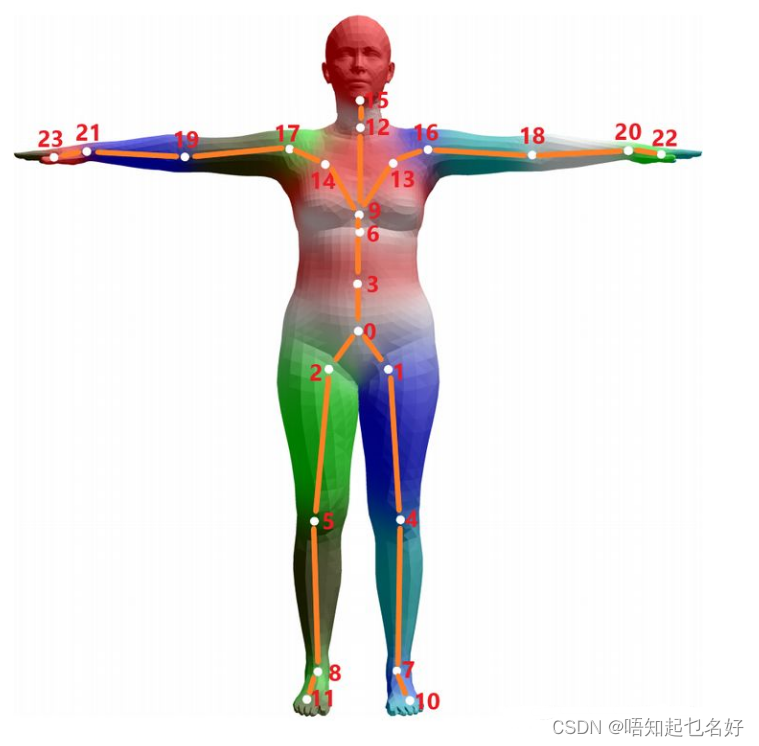
在SMPL模型目标是对于人体的形状比如胖瘦高矮,和人体动作的姿态进行定义,为了定义一个人体的动作,我们需要对人体的每个可以活动的关节点进行参数化,当我们改变某个关节点的参数的时候,那么人体的姿态就会跟着改变,类似于布偶娃娃的姿态活动。为了定义人体的形状,SMPL同样定义了参数,这个参数可以指定人体的形状指标。SMPL定义两个参数pose(
β
\beta
β)和shape(
θ
\theta
θ)来控制人体的运动体姿变化。
1.形状参数( β \beta β)
一组形状参数有着10个维度的数值去描述一个人的形状,每一个维度的值都可以解释为人体形状的某个指标,比如高矮,胖瘦等
2.姿态参数( θ \theta θ)
一组姿态参数有着 24 × 3 24\times3 24×3维度的数字,去描述某个时刻人体的动作姿态,其中的 24 24 24表示的是 24 24 24个定义好的人体关节点,其中的 3 3 3并不是如同识别问题里面定义的 ( x , y , z ) (x,y,z) (x,y,z)空间位置坐标(location),而是指的是该节点针对于其父节点的旋转角度的轴角式表达(axis-angle representation)(对于这 24 24 24个节点,作者定义了一组关节点树)
二、体姿转换过程原理
1.基于形状的混合成形(Shape Blend Shapes)
在这个阶段,一个基模版(或者称之为统计上的均值模版)
T
−
_T^-
T− 作为整个人体的基本姿态,这个基模版通过统计得到,用
N
=
6890
N=6890
N=6890个端点(vertex)表示整个mesh,每个端点有着
(
x
,
y
,
z
)
(x,y,z)
(x,y,z)三个空间坐标,要注意和骨骼点joint区分。
随后通过参数
β
\beta
β去描述我们需要的人体姿态和这个基本姿态的偏移量,叠加上去就形成了我们最终期望的人体姿态,这个过程是一个线性的过程。其中的
B
s
(
β
→
)
B_s(_\beta^\to)
Bs(β→)就是一个对参数
β
\beta
β的一个线性矩阵的矩阵乘法过程,我们接下来会继续讨论。此处得到的人体mesh的姿态称之为静默姿态(rest pose,也可以称之为T-pose),因为其并没有考虑姿态参数的影响。
2.基于姿态的混合成形 (Pose Blend Shapes)
当我们根据指定的 β \beta β参数对人体mesh进行形状的指定后,我们得到了一个具有特定胖瘦,高矮的mesh。但是我们知道,特定的动作可能会影响到人体的局部的具体形状变化,举个例子,我们站立的时候可能看不出小肚子,但是坐下时,可能小肚子就会凸出来了,这个就是很典型的 具体动作姿态影响人体局部mesh形状的例子了。 换句话说,就是姿态参数[公式]也会在一定程度影响到静默姿态的mesh形状。结合完形状变形和姿态变形之后,就去估算关节点的位置,用于第三步蒙皮操作。
3.蒙皮 (Skinning)
在之前的阶段中,我们都只是对静默姿态下的mesh进行计算,当人体骨骼点运动时,由端点(vertex)组成的“皮肤”将会随着骨骼点(joint)的运动而变化,这个过程称之为蒙皮。蒙皮过程可以认为是皮肤节点随着骨骼点的变化而产生的加权线性组合。简单来说,就是距离某个具体的骨骼点越近的端点,其跟随着该骨骼点旋转/平移等变化的影响越强。
三、具体过程分析
1.基于形状的混合成形
整个形状的混合成形可以用以下公式表示:
V
s
h
a
p
e
=
D
β
+
T
‾
V_{shape}=D\beta+\overline{T}
Vshape=Dβ+T
其中:
D
∈
R
6890
×
3
×
10
D\in R^{6890\times3\times10}
D∈R6890×3×10是10个主成份的偏移
β ∈ R 10 \beta\in R^{10} β∈R10表示的是10个主成份偏移的大小
T ‾ ∈ R 6890 × 3 \overline T\in R^{6890\times3} T∈R6890×3表示的是基模版的mesh
V s h a p e ∈ R 6890 × 3 V_{shape}\in R^{6890\times3} Vshape∈R6890×3表示的是混合成形后的mesh
这个公式是线性的,可以直接套参数运算
2.基于姿态的混合成形
模型以0号节点为根节点,通过其他23个节点相对于其父节点(根据其运动学树结构可以定义出节点的父子关系)的旋转角度,我们可以定义出整个人体姿态的姿势。这里的旋转是用的轴角式表达。那么表示这些非根节点的相对于父节点的相对旋转需要用 23 × 3 23\times3 23×3个参数,为了表示整个人体运动的全局旋转(也称之为朝向,Orientation)和空间位移,比如为了表示人体的行走,奔跑等,我们还需要对根节点定义出旋转和位移,那么同样的,需要用3个参数以轴角式的方式表达旋转,再用3个参数表达空间位移。需要特别注意的是,轴角式并不方便计算,因此通常会把它转化成旋转矩阵进行计算,其参数量从3变成了 3 × 3 = 9 3\times3=9 3×3=9个。因此在控制mesh成形方面,基于姿态的混合成形需要 R ( θ → ) = 23 × 9 = 207 R(\overrightarrow{\theta})=23\times9=207 R(θ)=23×9=207个基本的pose模版。由于姿态的混合变形是非线性的,所以需要利用神经网络来训练得到一个 P ∈ R 3 N × 9 K P\in R^{3N\times9K} P∈R3N×9K的一个矩阵来结合形变参数 θ \theta θ来说使用。要知道这个过程是非线性的,需要训练的
3.骨骼点位置估
因为不同人体形状具有较大差异性,因此在经过了之前谈到的两种混合成形之后,我们仍然需要根据成形后的mesh估计出符合该mesh的骨骼点,以便于我们后续对这些骨骼点进行旋转,形成我们最终期望的姿态。因此,骨骼点位置估计(Joint Locations Estimation)在这里指的是根据混合成形后静默姿态下的mesh端点的位置,估算出静默姿态的作为控制点的骨骼点的理想位置。这个过程也是非线性的,需要训练的
4.蒙皮
在经过骨骼点位置估计之后,我们便有了对整个人体数字模型进行操作的控制点了,其实就是骨骼点。当我们对骨骼点进行旋转时,我们可以像摆动球形关节娃娃一样将静默姿态下的人体摆成我们需要的姿态。人体mesh端点也会随着其周围的关节点一起变化,形成我们最后看到的人体数字模型。因此蒙皮其实是让静默姿态下的人体骨架“动起来”,并且对其蒙上“皮肤”的过程。

















 2490
2490

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









