







Semantic Terrain Classification for Off-Road Autonomous Driving 代码学习 网络结构
bevnet网络结构
train_funcs = {
'default': train_fixture.train_single,
}
训练函数
nets = {
name: spec['net'] for name, spec in ret.items()
}
net_opts = {
name: spec['opt'] for name, spec in ret.items() if spec['opt'] is not None
}
#网络
train_funcs[g.model_variant](nets, net_opts, g)
具体的train_single函数
def train_single(nets, net_opts, g):
"""
Training single-frame BEVNet.
Args:
nets: dictionary of models to forward/backprop in sequential order.
net_opts: optim related modules for training nets.
g: global arguments dictionary.
"""
# forward 3 modules: VoxelFeatureEncoder, MiddleSparseEncoder, BEVClassifier
网络由三个模块组成
def forward_nets(nets, x):
voxels = nets['VoxelFeatureEncoder'](x['voxels'], x['num_points'])
voxel_features = nets['MiddleSparseEncoder'](voxels, x['coordinates'], g.batch_size)
preds = nets['BEVClassifier'](voxel_features)
return preds
def step(nets, inputs, labels=None, criterion=None):
def train(nets, net_opts, trainloader, criterion, epoch, writer, device):
def validate(nets, validloader, criterion, n_iter, writer, device):
主程序部分
voxel_cfg = g.voxelizer
voxel_generator = VoxelGenerator(
voxel_size=list(voxel_cfg['voxel_size']),
point_cloud_range=list(voxel_cfg['point_cloud_range']),
max_num_points=voxel_cfg['max_number_of_points_per_voxel'],
full_mean=voxel_cfg['full_mean'],
max_voxels=voxel_cfg['max_voxels'])
从点云生成voxel生成voxel
voxel_generator = spconv.utils.VoxelGenerator(
voxel_size=[0.1, 0.1, 0.1],
point_cloud_range=[-50, -50, -3, 50, 50, 1],
max_num_points=30,
max_voxels=40000
)
points = # [N, 3+] tensor.
voxels, coords, num_points_per_voxel = voxel_generator.generate(points)
其中关键部分三维点云转化为voxel
这个中voxel讲得很好points_to_voxel
https://blog.csdn.net/qq_39732684/article/details/105188258
def points_to_voxel(points,
"""convert 3d points(N, >=3) to voxels. This version calculate
everything in one loop. now it takes only 0.8ms(~6k voxels)
with c++ and 3.2ghz cpu.
Args:
points: [N, ndim] float tensor. points[:, :3] contain xyz points and
points[:, 3:] contain other information such as reflectivity.
voxel_size: [3] list/tuple or array, float. xyz, indicate voxel size
coors_range: [6] list/tuple or array, float. indicate voxel range.
format: xyzxyz, minmax
coor_to_voxelidx: int array. used as a dense map.
max_points: int. indicate maximum points contained in a voxel.
max_voxels: int. indicate maximum voxels this function create.
for voxelnet, 20000 is a good choice. you should shuffle points
before call this function because max_voxels may drop some points.
full_mean: bool. if true, all empty points in voxel will be filled with mean
of exist points.
block_filtering: filter voxels by height. used for lidar point cloud.
use some visualization tool to see filtered result.
Returns:
voxels: [M, max_points, ndim] float tensor. only contain points.
coordinates: [M, 3] int32 tensor. zyx format.
num_points_per_voxel: [M] int32 tensor.
"""
#这里要理解output的voxel具体是什么
ndim包含着点云的特征 x,y,z,f等
max_point,ndim包含着每个小块中所有店的信息
每一个大的voxel包含着M个小块
voxel包含着所有voxel里的点云特征
领用coordinate来进行索引,索引出每个小块所在的位置空间
训练数据和验证数据读取部分,具体详见pytorch 自己构建dataset类
train_dataset = bev_utils.BEVLoaderV2(g.train_input_reader,
g.dataset_path,
voxel_generator=voxel_generator,
n_buffer_scans=g.buffer_scans,
buffer_scan_stride=g.buffer_scan_stride)
valid_dataset = bev_utils.BEVLoaderV2(g.eval_input_reader,
g.dataset_path,
voxel_generator=voxel_generator,
n_buffer_scans=g.buffer_scans,
buffer_scan_stride=g.buffer_scan_stride)
其中数据读取的类定义如下 BEVLoaderV2(data.Dataset):
# overwrite the default threshold values in spconv.utils.points_to_voxel
from functools import partial
import spconv
print('patch spconv to increase the allowable z range. This will not affect the point cloud range.')
spconv.utils.points_to_voxel = partial(spconv.utils.points_to_voxel,
height_threshold=-4.0,
height_high_threshold=5.0)
#其中 partil 的理解https://blog.csdn.net/joeyon1985/article/details/41984487
函数的partial应用
典型的,函数在执行时,要带上所有必要的参数进行调用。然后,有时参数可以在函数被调用之前提前获知。这种情况下,一个函数有一个或多个参数预先就能用上,以便函数能用更少的参数进行调用。
例子import functools
def add(a, b):
return a + b
add(4, 2)
6
plus3 = functools.partial(add, 3)
plus5 = functools.partial(add, 5)
plus3(4)
7
plus3(7)
10
plus5(10)
15
定义损失函数和trainloader
criterion = torch.nn.CrossEntropyLoss(reduction="mean", ignore_index=ignore_idx,
weight=class_weights)
trainloader = data.DataLoader(
train_dataset,
batch_size=g.batch_size,
num_workers=g.num_workers,
collate_fn=bev_utils.bev_single_collate_fn,
drop_last=True,
shuffle=True)
一些基本的,输出
output = g.output
os.makedirs(output, exist_ok=True)
writer = SummaryWriter(log_dir=os.path.join(output))
tfu.log_dict(writer, 'global_args', g, 0)
根据轮数调整学习率https://blog.csdn.net/qyhaill/article/details/103043637
更新策略:
每过step_size个epoch,做一次更新:
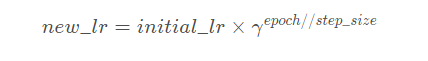
其中new_lr是得到的新的学习率,initial_lr是初始的学习率,step_size是参数step_size,γ 是参数gamma。
参数:
optimizer (Optimizer):要更改学习率的优化器;
step_size(int):每训练step_size个epoch,更新一次参数;
gamma(float):更新lr的乘法因子;
last_epoch (int):最后一个epoch的index,如果是训练了很多个epoch后中断了,继续训练,这个值就等于加载的模型的epoch。默认为-1表示从头开始训练,即从epoch=1开始。
训练过程
for epoch in range(1, g.epochs + 1):
if resume_epoch < epoch:
train(nets, net_opts, trainloader, criterion, epoch, writer, g.train_device)
_save_model(nets, net_opts, epoch, g, os.path.join(output, 'model.pth'))
n_iter = epoch * len(trainloader)
val_loss = validate(nets, validloader, criterion, n_iter, writer, g.train_device)
if val_loss < best_valid_loss:
print("new best valid loss at %3f, saving model..." % val_loss)
best_valid_loss = val_loss
_save_model(nets, net_opts, epoch, g, os.path.join(output, 'best.pth'))
for _, sched in net_scheds.items():
sched.step()
其中训练函数部分
def train(nets, net_opts, trainloader, criterion, epoch, writer, device):
tfu.make_train(nets)
loss_avg = []
itr = tqdm(trainloader)
注:1
在训练模型时会在前面加上:
model.train()
在测试模型时在前面使用:
model.eval()
2 tqdm 在python的一个长循环中增加一个进度条
读取数据部分
for i, batch_data in enumerate(itr):
# dataloader类理解 https://blog.csdn.net/zw__chen/article/details/82806900
# i 返回第几次 batch_data返回data和label
for _, opt in net_opts.items():
opt.zero_grad()
def to_device(key):
return batch_data[key].to(device, non_blocking=True)
label = to_device('label')
inputs = dict()
inputs['batch_size'] = len(label)
for key in batch_data:
if key in ['points']:
continue
inputs[key] = to_device(key)
输入和标签以key区分
然后进行每一步的训练
pred, loss = step(nets, inputs, labels=label, criterion=criterion)
loss.backward()
其中每一步训练函数step
def step(nets, inputs, labels=None, criterion=None):
model_outputs = forward_nets(nets, inputs)
pred = model_outputs['bev_preds']
loss = 0.0
if g.include_unknown:
# Note that `num_class` already includes the unknown label
labels[labels == 255] = g.num_class - 1
if labels is not None and criterion is not None:
labels = labels.long()
loss = criterion(pred, labels) # 计算loss
return pred, loss
网络为
def forward_nets(nets, x):
# forward 3 modules: VoxelFeatureEncoder, MiddleSparseEncoder, BEVClassifier
voxels = nets['VoxelFeatureEncoder'](x['voxels'], x['num_points'])
voxel_features = nets['MiddleSparseEncoder'](voxels, x['coordinates'], g.batch_size)
preds = nets['BEVClassifier'](voxel_features)
return preds
这里使用可以替换的网络参数,在yaml文件中可以修改
网络结构 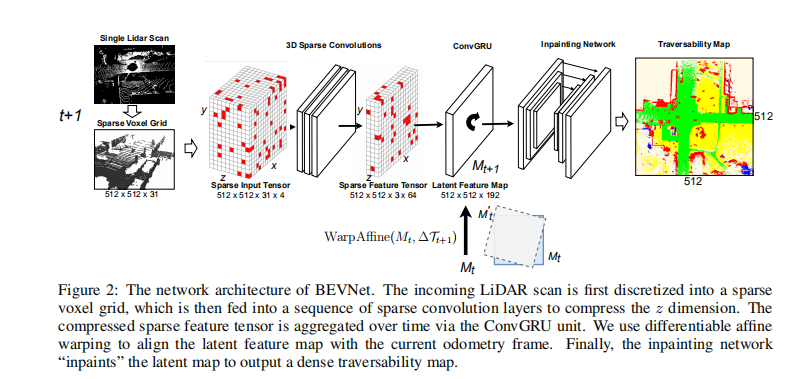
图2:BEVNet的网络架构。首先将入射激光雷达扫描离散为稀疏体素网格,然后将稀疏体素网格送入一系列稀疏卷积层以压缩z维。压缩后的稀疏特征张量通过ConvGRU单元随时间进行聚合。我们使用可微的仿射翘曲来对齐潜在特征图与当前里程计框架。最后,inpaint网络“inpaint”潜映射以输出密集的可遍历映射。
其中 step 输入为voxel和label 其中数据格式如下
return {
'voxels': voxels,
'coords': coords,
'num_points': num_points,
'label': label,
'points': points,
'img': np.array([0.0], np.float32), # Dummy value
'voxel_point_pixel_idxs': voxel_point_pixel_idxs,
'voxel_point_pixel_inrange': voxel_point_pixel_inrange,
'voxel_point_idxs': voxel_point_idxs,
'voxel_point_segmentation': voxel_point_segmentation,
}
随后输入到网络里
#第一步 voxel特征提取
voxels = nets['VoxelFeatureEncoder'](x['voxels'], x['num_points']) ##这里使用可以替换的网络参数,在yaml文件中可以修改
输入为voxel和每个voxel的点 不使用voxel的坐标 耿直的取均值 压缩voxel内容
voxel_features = nets['MiddleSparseEncoder'](voxels, x['coordinates'], g.batch_size)
#中间层 降采样z轴 不考虑xy
中间层的采样
class SpMiddleNoDownsampleXYNoExpand(nn.Module):
"""
Only downsample z. Do not downsample X and Y.
"""
def __init__(self,
output_shape,
num_input_features):
super(SpMiddleNoDownsampleXYNoExpand, self).__init__()
BatchNorm1d = functools.partial(nn.BatchNorm1d, eps=1e-3, momentum=0.01)
SubMConv3d = functools.partial(spconv.SubMConv3d, bias=False)
sparse_shape = np.array(output_shape[1:4]) + [1, 0, 0]
self.sparse_shape = sparse_shape
self.voxel_output_shape = output_shape
self.middle_conv = spconv.SparseSequential(
SubMConv3d(num_input_features, 32, 3, indice_key="subm0"),
BatchNorm1d(32),
nn.ReLU(),
SubMConv3d(32, 64, 3, indice_key="subm0"),
BatchNorm1d(64),
nn.ReLU(),
# SubMConv3d(32, 64, 3, (2, 1, 1), padding=[1, 1, 1]),
spconv.SparseMaxPool3d(3, (2, 1, 1), padding=[1, 1, 1]),
BatchNorm1d(64),
nn.ReLU(),
SubMConv3d(64, 64, 3, indice_key="subm1"),
BatchNorm1d(64),
nn.ReLU(),
SubMConv3d(64, 64, 3, indice_key="subm1"),
BatchNorm1d(64),
nn.ReLU(),
SubMConv3d(64, 64, 3, indice_key="subm1"),
BatchNorm1d(64),
nn.ReLU(),
# SubMConv3d(64, 64, 3, (2, 1, 1), padding=[0, 1, 1]),
spconv.SparseMaxPool3d(3, (2, 1, 1), padding=[0, 1, 1]),
BatchNorm1d(64),
nn.ReLU(),
SubMConv3d(64, 64, 3, indice_key="subm2"),
BatchNorm1d(64),
nn.ReLU(),
SubMConv3d(64, 64, 3, indice_key="subm2"),
BatchNorm1d(64),
nn.ReLU(),
SubMConv3d(64, 64, 3, indice_key="subm2"),
BatchNorm1d(64),
nn.ReLU(),
# SubMConv3d(64, 64, (3, 1, 1), (2, 1, 1)),
spconv.SparseMaxPool3d((3, 1, 1), (2, 1, 1)),
BatchNorm1d(64),
nn.ReLU(),
)
def forward(self, voxel_features, coors, batch_size):
coors = coors.int()
ret = spconv.SparseConvTensor(voxel_features, coors, self.sparse_shape, batch_size)
ret = self.middle_conv(ret)
ret = ret.dense()
N, C, D, H, W = ret.shape
ret = ret.view(N, C * D, H, W)
return ret















 935
935











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









