







面向越野地形自动驾驶的语义地形分类
论文 Semantic Terrain Classifification for Off-RoadAutonomous Driving
代码 https://github.com/JHLee0513/semantic_bevnet
CoRL2021据说这个会议上的论文都挺狠的
摘要:
利用环境信息得到高密度、高精度的可穿越性地图对于越野导航至关重要。在本文中,我们重点研究将地形划分为4个成本等级(free, low-cost, medium-cost, obstacle)类的问题,以进行可穿越性评估。这需要机器人对这两种语义进行推理(存在哪些对象?)和几何特性(对象位于何处?)保护环境。为了实现这一目标,我们开发了一种新型的鸟瞰网络(BEVNet),这是一种深度神经网络,可以直接从稀疏的激光雷达输入预测编码地形类别的局部地图。BEVNet以时间一致的方式处理地理、度量和语义信息。更重要的是,它利用学到的经验和历史来预测未知空间和未来的地形等级,使机器人能够更好地评估自己的状况。我们定量评估了BEVNet在公路和越野情况下的性能,并表明其性能优于各种baselines。
介绍
尽管最近人们对开发自动驾驶汽车产生了极大的兴趣,但这项工作的主要内容集中在道路和城市驾驶上。然而,可在复杂自然地形下行驶的自主越野车辆可使包括国防、农业、保护和搜索救援在内的广泛应用领域受益。在这种环境中,了解车辆周围地形的可穿越性对于成功规划和控制至关重要。由于越野地形通常具有地平面快速变化、植被茂密、悬垂树枝和负面障碍物的特点,因此从稀疏的激光雷达数据中判断地形是否可穿越是一个具有挑战性的问题。换句话说,一个成功的越野机器人必须研究其周围环境的几何和语义内容,以确定哪些地形是可穿越的,哪些是不可穿越的。
在这项工作中,我们将可遍历性估计表述为一个语义地形分类问题[1,2]。其动机是统一语义(存在哪些对象?)和几何体(对象位于何处?)将地形转换为单一成本本体。从语义角度来看,大型岩石和树干等物体是不可穿越的,而砾石、草和灌木都是越野车可穿越的[3],但难度越来越大。从几何角度来看,可以忽略悬垂障碍物,同一语义类别的对象的可通过性可能因其高度而异(例如,高灌木丛与短灌木丛)。为此,我们使用一组离散的可遍历性级别,以便于根据语义类的可遍历性对语义类进行分组,同时允许我们根据它们的几何结构调整特定实例的通过性级别。
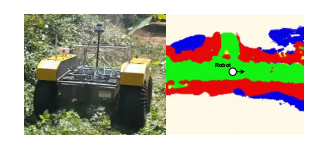
图1:示例目标场景。BEVNet可以在Clearpath Warthog上运行,以生成越野环境的语义地图。
一个有效的地形分类系统应能有效地1)使用噪声里程计收集随时间变化的观测结果[1,4],2)环境中部分可见或甚至尚未可见部分的原因[7,8,9],以及3)检测悬垂结构,如树枝、隧道和电线[10,11]。虽然以前的工作分别解决了这些问题中的每一个,但上述挑战是相互关联的,解决每一个问题都应该使其他人受益。
在本文中,我们提出了一种鸟瞰网络(BEVNet),这是一种递归神经网络,通过激光雷达扫描以2D网格的形式直接预测机器人周围的地形类别。如图2所示,我们的模型有三个主要部分:
1)处理体素化点云的3D稀疏卷积子网络,
2)卷积选通递归单元(ConvGRU),它使用选通递归单元[12]中的卷积层来聚合3D信息,3)基于[13]的高效二维卷积编码器-解码器,可同时修复空白并将三维数据投影到二维鸟瞰图(BEV)地图中。为了训练模型,我们使用过去和未来标记的激光雷达扫描来构建完整的三维语义点云,并构建地面真实二维可遍历性地图。以前的工作[10]利用一组具有地面/悬挑分类的可折叠立方体结构,根据其间隙去除不相关的悬挑,但当难以从稀疏激光雷达扫描中估计准确的地面标高时,这种基于规则的过滤缺乏泛化性。相比之下,我们的模型是用从完全观测和标记的环境中构建的地面真实BEV图来训练的,这允许准确的地面水平估计用于学习。然后,该网络学习检测并移除稀疏激光雷达扫描中的悬垂障碍物,而无需明确的过滤机制。
我们做了一些贡献和经验观察。我们提出了一个新的框架来构建BEV costmap,方法是:1)聚合随时间变化的观测值,2)预测地图中看不见的区域,3)过滤掉不影响可穿越性的无关障碍物,如悬垂树枝。SemanticKITTI[14]和RELLIS-3D[15]的实验结果表明,BEVNet在道路和越野环境中都优于 strong baselines。
 最低0.47元/天 解锁文章
最低0.47元/天 解锁文章


















 3356
3356

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









