






信源编码的三种方式与实现
一、本文概述
这是第一次在CSDN上写blog,想写很久了,一直因为忙耽搁了,放假了,打算整理一下这学期的一些代码和实验写blog。
本文主要根据我信息论课程的信源编码大作业报告所写,相关代码放在我的GitHub上,初次在CSDN发blog,小小紧张哈哈哈。
本文主要实现了哈夫曼编码,且性能较为优秀。另外还拓展实现了LZ编码和算数编码,并在将哈夫曼和LZ-78两种编码方式的cpp文件通过统一的main.cpp文件整合在一起,可以通过运行project来选择希望的编码方式对目标文件进行编码。
另外,本文的实验中,也出现了一些编译器的问题,例如Visual Studio下和Mac下存在着一定的优劣对比。
本文中给出了一些实现的部分代码,完整代码见GitHub:
https://github.com/YZ-WANG/Three-methods-for-source-encoding
二、编码原理
本文的实验实现了三种编码方式:哈夫曼编码、LZ编码和算数编码。下面分析其各自基本原理。
1. 哈夫曼编码
哈夫曼编码是是一种可变长的分组编码,完全依据各字符出现的概率来构造码字。二进制的哈夫曼编码是基于二叉树的编码思想,所有可能的输入符号在哈夫曼树上对应为一个节点,结点的位置就是该符号的哈夫曼编码。为了构造出唯一可译码,这些节点都是哈夫曼树上的终极结点(即叶子结点),不再延伸,不会出现前缀码。具体编码方法如下:
- 将信源消息符号按其出现的概率大小依次排列为 p1≥p2≥…≥Pn;
- 取两个概率最小的字母分别配以 0 和 1 两个码元,并将这两个概率相加作为一个新字母的概率,与未分配二进制符号的字母一起重新排队;
- 对重排后的两个概率最小符号重复步骤2的过程;
- 不断继续上述过程,直到最后两个符号配以 0 和 1 为止;
- 从最后一级开始,向前返回得到各个信源符号所对应的码元序列,即为相应码字。
特别地,有时为了得到最短平均码长,尽量减少赋长码的信源符号,需要在编码前对信源符号作添加,使得信源的符号数量满足 M(N-1)+1,其中M为正整数,N为进制,这样在多次合并后就能充分利用短码,以便降低平均码长。
此外,哈夫曼编码方法所得到的码并非是唯一的,造成非唯一的原因如下:
- 每次对信源缩减时,赋予信源最后两个概率最小的符号,用0和1是可以任意的,所以可以得到不同的哈夫曼编码,但不会影响码字的长度。
- 对信源进行缩减时,两个概率最小的符号合并后的概率与其他信源符号的概率相同时,这两者在缩减信源中进行概率排序,其位置放置次序可以是任意的,故会得到不同的哈夫曼码。此时将影响码字的长度,一般将合并的概率放在上面,这样可以得到较小的码方差。
哈夫曼编码的特点:
- 哈夫曼码的编码方法保证了概率大的符号对应于短码,概率小的符号对应于长码,充分利用了短码;
- 而是缩减信源的最后二个码字总是最后一位不同,从而保证了哈夫曼码是即时码。
哈夫曼码的编码效率是非常高的,它可以单个信源符号编码或用L较小的信源序列编码,对编码器的设计来说也将简单得多。但是应当注意,要达到很高的效率仍然需要按长序列来计算,这样才能使平均码字长度降低。
哈夫曼编码的解码则在识别出一个个叶子结点后按照叶子结点对应的原信源符号译码。
哈夫曼编码虽然效率出众,但仍然存在一些分组码所具有但缺点。例如概率特性必须精确测定,以此来编织码表,若略有变化,还需要更换码表。故实际编码过程中需要对原始数据扫描两遍,第一遍用来统计原始数据中各字符出现的概率,创建码表存放起来,第二遍则依据码表在扫描的同时进行编码,才能传输信息。如果将这种编码放在网络通信中,两遍扫描会引起较大的时延;如果用于数据压缩,则会降低速度。因此,出现了自适应哈夫曼编码方法,其码表不是实现构造,而是随着编码的进行,不断动态构造、调整。
2. 算术编码
由于在使用分组码对信源单符号进行编码时,没有将符号间的相关性纳入考虑之中:若将m个符号合起来进行编码则会增加设备复杂度,且组间符号的相关性还是无法纳入考虑。这就使得信源编码的匹配原则不能充分满足,编码效率有所损失。
为了克服这种局限性,一种基于非分组码的编码方法——算数编码应运而生。编码的基本思路是:将需要编码的全部数据看成某一 L L L 长序列,所有可能出现的L长序列的概率映射到 [ 0 , 1 ] [0,1] [0,1] 的区间上,把 [ 0 , 1 ] [0,1] [0,1] 区间分成许多小段,每段长度等于某一序列的概率。再在段内取一个二进制小数用作码字,其长度可与该序列的概率匹配,达到高效率编码的目的。
算数编码实际的编译码过程比较复杂,但在性能上具有许多优点,特别是所需要的参数很少,不像哈夫曼编码那样需要一个很大的码表。从理论上说,只要已知信源符号集及其符号概率,算数编码的平均码长可以接近符号熵。
具体编码方法如下:
- 将文件以字节为单位读入,并将其分割成bit串形式
- 计算文件中bit0和bit1的总数量和各自的概率
- 对一定长度L的符号串进行编码,并将数据写入压缩后文件中
- 从压缩文件中读入数据,并还原成长度为L的符号串输入至解压文件中
3. LZ编码
LZ编码是由以色列研究者齐夫和伦佩尔完全脱离哈夫曼码和算术编码的设计思路,设计出的一系列比哈夫曼编码更有效、比算术编码更快捷的通用压缩算法。将这些算法统称为LZ系列算法。LZ系列算法利用一种巧妙的方式将字典技术应用于通用数据压缩领域,而且,可以从理论上证明LZ系列算法同样可以逼近信息熵的极限。
实验采用的 LZ-78编码 的编码过程如下:
- 设信源符号集 A = a 1 , a 2 , … , a K A={a1,a2,…,aK} A=a1,a2,…,aK 共K个符号,设输入信源符号序列为 U = ( u 1 , u 2 , … … , u L ) U=(u1,u2,……,uL) U=(u1,u2,……,uL),编码是将此序列分成不同的段。
- 分解是迭代进行的,在第i步,编码器从 s i s_i si - 1 短语后的第一个符号开始向后搜索在此之前从未出现过的最短短语 s i s_i si,将短语 s i s_i si 添入字典第i段。由于 s i s_i si 是此时字典中最短的新短语,所以 s i s_i si 在去掉最后一个符号 x x x 后所得的前缀必定是字典中之前已经出现过的。
- 若设此前缀是在第 j ( < i ) j(<i) j(<i) 步时出现的,则对 s i s_i si 的编码就可以利用 j j j 和 s i s_i si 最后一位符号 x x x 来表示,即为码字 ( j , x ) (j,x) (j,x)。对于段号 j j j,最多需要 ⌈ l o g i ⌉ \lceil logi \rceil ⌈logi⌉ bit表示,而符号 x x x 只需 ⌈ l o g K ⌉ \lceil logK \rceil ⌈logK⌉ bit。若编码猴的字典中短语共有M(U)个,则U序列编码后输出的码流总长度为 ( ⌈ l o g i ⌉ + ⌈ l o g K ⌉ ) (\lceil logi \rceil + \lceil logK \rceil) (⌈logi⌉+⌈logK⌉)。
LZ-78编码的核心实际上就是一个包含了短语、段号、码字、二进制码的字典,如下所示。
| 短语 | 段号 | 码字 | 二进制码 |
|---|---|---|---|
| a | 1 | (0,a) | (0,0) |
| b | 2 | (0,b) | (0,1) |
| ba | 3 | (2,a) | (10,0) |
| baa | 4 | (3,a) | (11,0) |
| … | … | … | … |
LZ编码的编码方法非常简捷,译码也很简单,可以一边译码一边建立字典。译码时若收到的码字为 ( j , x ) (j,x) (j,x),则在字典中找到第 j j j 个短语,然后加上符号 x x x 即可译出对应的新短语,并添入字典。因此发送时无需传送字典本身。LZ算法的逻辑简单,硬件实现廉价,运算速度快,在很多计算机数据存储中得到应用。其优点在于能够有效利用信源输出序列的频率、重复性和高使用率的冗余度,是一种自适应算法,只需对信源序列进行一次扫描,无须知道信源的先验统计特性,运算时间正比于序列长度。但也有缺点,一是不能有效地利用位置的冗余度;二是该算法通常在序列起始段压缩效果差一些,随着长度增加效果变好。
三、算法设计思路
1. 哈夫曼编码
a. 设置功能结构体和函数
为构造哈夫曼树,首先要知道压缩的目标文件中各个字符的频度。因此先对整个文件进行扫描,统计各个字符的频度。在本算法中,考虑到编码方式,将 每个字节对应于一个符号,对于 8 bit 的二进制码,共计 2 8 = 256 2^8=256 28=256 种。故创建一个 结构体 Node,表示符号与对应的频度,用于对其进行统计。
struct Node
{
unsigned char uch; //一字节的符号
unsigned long weight; //对应的频度
};
针对哈夫曼树本身,需要对每一个节点进行刻画。创建 结构体 HufNode,其中包含变量:频度 weight、父亲节点 parent、左子节点left_child、右子节点right_child,对应的符号uch,存放其编码的字符数组code。
struct HufNode
{
unsigned char uch; //记录符号
unsigned long weight; //权重,即频度
char * code; //存放编码的数组
int parent, left_child, right_child; //定义父节点,左子节点,右子节点
};
typedef struct HufNode HufNode, * HufTree; //方便后续建树
有了struct HufNode之后,用于构造哈夫曼树的符号就用*HufTree来存储。为256种可能的符号各自构造实例组成指针数组,即Node *tmp_nodes =(Node *)malloc(256*sizeof(Node));。该语句为 存放256种符号的实例的指针数组 在内存开辟了相应的空间。
实际上,考虑到读入的目标文件实际上在计算机中就是 一长串的二进制码流,我们每次操作的 一字节的符号实际上就是8bit长的二进制码,那么这8bit二进制码其实就对应于十进制的0-255。如此一来,就可以把256种字节用0-255表示,即tmp_nodes[i].uch = (unsigned char)i;,每个节点存储的unsigned char uch实际上就 对应其下标的8位二进制码表示。
实际上没必要在用指针指向对应的节点,只需要存储其对应节点的uch的8位二进制码相应的十进制值,就可以 通过指针数组的索引到达对应节点。在编码构造哈夫曼树时,需要每次在tmp_nodes数组找到目前剩余节点中频度最小的两个节点,将其纳入树中。因此要编写一个函数void Find2Min来完成该功能。该函数实现起来比较简单,主要就是两次for循环遍历未加入哈夫曼树的节点。
void Find2Min(HufNode * huf_tree, unsigned int n, int * s1, int * s2)
{
unsigned int i;
unsigned long min = ULONG_MAX;
for(i = 0; i < n; i++)
if(huf_tree[i].parent == 0 && huf_tree[i].weight < min)
{
min = huf_tree[i].weight;
* s1 = i;
}
huf_tree[* s1].parent=1;
min = ULONG_MAX;//赋值无穷大正数
for(i = 0; i < n; i++)
if(huf_tree[i].parent == 0 && huf_tree[i].weight < min)
{
min = huf_tree[i].weight;
* s2 = i;
}
}
接着需要写一个构造哈夫曼树的函数。其实该函数思路很简单,循环待操作符号节点个数的次数,并且每次都是在待操作节点中找到频度(也就是权值)最小的两个节点,将其加入树中。于是利用之前的Find2Min(huf_tree, i, &s1, &s2);函数可以很方便地实现。
//建立哈夫曼树
//char_sum即出现符号的种类数目;node_num即哈夫曼树的最大节点数目
void BuildTree(HufNode *huf_tree, unsigned int char_sum, unsigned int node_num)
{
unsigned int i;
int s1, s2;
for(i = char_sum; i < node_num; i++)
{
Find2Min(huf_tree, i, &s1, &s2);
huf_tree[s1].parent = huf_tree[s2].parent = i;
huf_tree[i].left_child = s1;
huf_tree[i].right_child = s2;
huf_tree[i].weight = huf_tree[s1].weight + huf_tree[s2].weight;
}
}
不难预想到,我们在获得排序完毕的哈夫曼树之后,需要对其进行编码,我们同样出于封装的考虑,写一个函数void HufCode来完成此功能。我们只要调用它,并传入排序成哈夫曼树的完成的*tmp_nodes以及待编码的符号总数即可。最终,会把每个节点的编码结果放入节点的.code变量存放。这里我们对出现的符号种类的节点遍历,分别以这些节点为起点,自下而上检测左右关系来编码,具体实现如下。
//对完成排序的哈夫曼树进行编码
void HufCode(HufNode *huf_tree, unsigned char_sum) //char_sum为出现符号种类数
{
//定义略去
for(i = 0; i < char_sum; i++)
{
index = 256-1;
for(cur = i, next = huf_tree[i].parent; next != 0;
cur = next, next = huf_tree[next].parent)
if(huf_tree[next].left_child == cur)
code_tmp[--index] = '0';
else
code_tmp[--index] = '1';
huf_tree[i].code = (char * )malloc((256-index) * sizeof(char));
strcpy(huf_tree[i].code, &code_tmp[index]);
}
free(code_tmp);
}
b. 压缩文件
初始化统计表频度
开辟Node *tmp_nodes的256个Node单位的内存空间,用于存储字符频度的统计表。开辟空间后随即进行初始化。
Node *tmp_nodes =(Node * )malloc(256*sizeof(Node)); //为字符频度统计表分配内存空间
for(i = 0; i < 256; i++)
{
tmp_nodes[i].weight = 0;
tmp_nodes[i].uch = (unsigned char)i;
}
读入文件并统计频度
这里使用C语言中的FILE中的fread函数,从*infile中一字节一字节地读入符号存入(char * )&temp_char中,边读边更新统计表。读完后接下来就对temp_char的这段内存空间里的符号操作即可
FILE *infile, *outfile;
unsigned char temp_char; //存储读入的字符
unsigned long file_len = 0; //文件字节数
infile = fopen(ifname, "rb");
if (infile == NULL)
return -1;
fread((char *)&temp_char, 1, 1, infile);
while(!feof(infile))
{
tmp_nodes[temp_char].weight++; //统计表中相应符号频度更新
file_len++; //统计文件字节数
fread((char * )&temp_char, 1, 1, infile);
}
fclose(infile);
对统计表频度排序
这里采用冒泡排序对统计表中的 Node 实例们进行从大到小排序。然后找到第一个频度为0的Node,其索引下标即为出现的符号种类数目。
for(i = 0; i < 256-1; i++)
for(j = i+1; j < 256; ++j)
if(tmp_nodes[i].weight < tmp_nodes[j].weight)
{
node_temp = tmp_nodes[i];
tmp_nodes[i] = tmp_nodes[j];
tmp_nodes[j] = node_temp;
}
for(i = 0; i < 256; i++)
if(tmp_nodes[i].weight == 0)
break;
char_sum = i;
建立哈夫曼树进行编码
首先给HufNode *类型的huf_tree指针数组开辟空间,共2 * char_sum - 1个节点,并根据统计表对出现的符号的节点进行初始化。
然后调用
//初始化树节点
node_num = 2 * char_sum - 1;
huf_tree = (HufNode * )malloc(node_num * sizeof(HufNode));
for(i = 0; i < char_sum; i++)
{
huf_tree[i].uch = tmp_nodes[i].uch;
huf_tree[i].weight = tmp_nodes[i].weight;
huf_tree[i].parent = 0; //初始化节点
}
free(tmp_nodes);
//将以上节点全部设置为待加入节点
for(; i < node_num; i++)
huf_tree[i].parent = 0;
BuildTree(huf_tree, char_sum, node_num); //建立哈夫曼树
HufCode(huf_tree, char_sum); //对树进行编码
写文件
首先要写入原始数据的符号种类数目,fwrite((char *)&char_sum, 4, 1, outfile);,因为char_sum是存储为int类型,故占4个字节。然后将哈夫曼编码表写入文件,即.uch和.weight变量对。接着写入文件的长度file_len,大小为4字节。
接下来我们再一次扫描目标文件,这一次每读入一个符号就查表编码。这有一个难点,考虑到哈夫曼编码是变长码,理论上需要按照bit为单位操作;而实际上计算机中变量存储或者文件读写的最小可操作单位都是字节。因此这里我们借助字符类型数组char code_buf[256] = "\0";,每次编码都将码子先并入该字符数组strcat(code_buf, huf_tree[i].code);。
具体实现中,我们使用while循环直到文件读完。在while循环中,每一次我们都读入一字节符号,将其编码存入 code_buf 数组;每当code_buf中字符长度大于8时,获取数组中的前八位,将其对应的ASCII码所对应的字符存入输出文件中,再将整个字符串前移八位,strcpy(code_buf, code_buf+8);。一直循环该操作,直至code_buf字符长度小于8或为0,然后再次读入符号。若长度最终为0,则写入完毕。若不为0,则将其不足的位数补0,写入到输出文件最后。其中核心部分,也就是每8位输出的转换过程如下。
temp_char = '\0';
for(i = 0; i < 8; i++)
{
temp_char <<= 1; //左移一位
if(code_buf[i] == '1')
temp_char |= 1; //与1按位异或
}
fwrite((char *)&temp_char, 1, 1, outfile);
c. 解压文件
压缩所得文件起始即记录了原文件中字符的种类数,获得后可知之后的多少字节中存储了哈夫曼树的编码信息,按照压缩的格式读取信息后,可以还原出编码后的哈夫曼树,即编码表可知。再向后读取,可得文件中字符的总数,即文件的总长度。
此时,压缩文件中剩余的信息即为编码信息,将其逐位读入后,按照编码表翻译为原来的字符,写入输出文件中,即可得到原文件。需要注意的是,在解码过程中,每次成功解码后将一计数器加一,用于统计解码数是否到达原文件的字符长度,当长度到达后,舍弃压缩文件中剩余位数,完成写入,其目的为防止原先压缩过程中可能存在的补零操作所造成的影响。
2. 算数编码
设置功能类class Arithmetic,成员如下:
string FileAddress; //操作对象文件地址
int TotalNumber = 0; //记录总的bit数
int NumList[2] = {0}; //存储0和1出现的次数
long double ProbaList[2] = {0.0}; //存储0和1出现的概率
long double P[2] = {0.0}; //存储0和1概率区间的下限
Arithmetic(); //构造函数
void open(string input);
void Press(); //压缩文件
void Decode(string sourcefile, string dstfile); //解压文件
以字节为单位读入,并将其分割成bit串形式
read.read((char*)InChar, sizeof(unsigned char)); //读第一个字节
while (!read.eof()) //未读到末尾继续循环
{
TotalNumber += 8; //每读入一个字符,总bit数加8
BitList[0] = (* InChar & 0x80) == 0x80 ? 1 : 0;
BitList[1] = (* InChar & 0x40) == 0x40 ? 1 : 0;
BitList[2] = (* InChar & 0x20) == 0x20 ? 1 : 0;
BitList[3] = (* InChar & 0x10) == 0x10 ? 1 : 0;
BitList[4] = (* InChar & 0x08) == 0x08 ? 1 : 0;
BitList[5] = (* InChar & 0x04) == 0x04 ? 1 : 0;
BitList[6] = (* InChar & 0x02) == 0x02 ? 1 : 0;
BitList[7] = (* InChar & 0x01) == 0x01 ? 1 : 0; //将字节分割成bit形式
计算文件中bit0和bit1的总数量和各自的概率
ProbaList[0] = long double(NumList[0]) / TotalNumber; //计算0和1出现的概率
ProbaList[1] = long double(NumList[1]) / TotalNumber;
P[0] = 0; //计算0和1概率区间的下限
P[1] = ProbaList[0];
对一定长度L的符号串进行编码,并将数据写入压缩后文件中。然后从压缩文件中读入数据,并还原成长度为L的符号串输入至解压文件中
for (int i(0); i < N; i++)
{
if (count == 0) break; //如果已经读完文件,则退出循环
for (int j(0); j < 8; j++)
{
if (temp >= P[1])
{ count -= 1;
OutList[j] = 1;
temp = (temp - P[1]) / ProbaList[1];
}
else
{ count -= 1;
OutList[j] = 0;
temp = (temp - P[0]) / ProbaList[0];
}
}
算法的流程图如下。
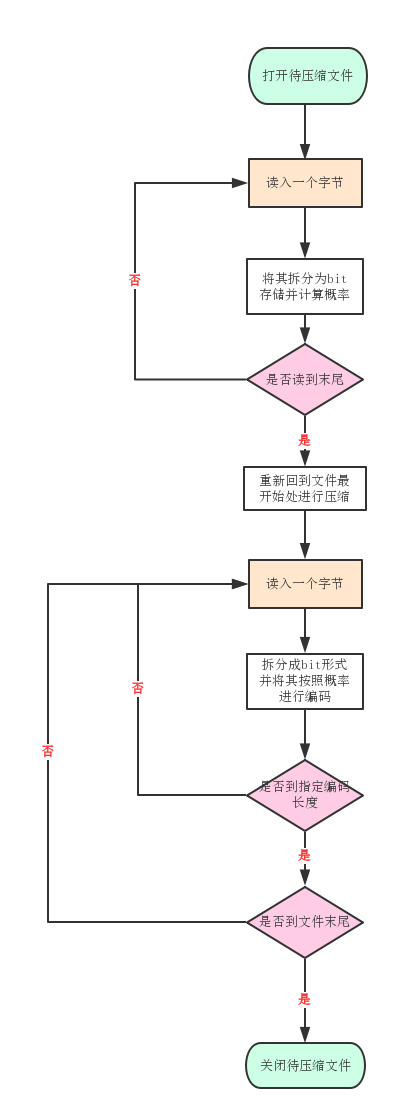
算数编码流程图
|
3. LZ-78编码
a. 设计功能类
LZ-78编码的核心就是编码和解码中构造一个字典,通过字典的段号与最后一位字符来构造码字。因此这里将编码(或解码)这一事件封装成一个class类。类中有一个struct Dictionary变量,该变量存储一段符号串单元的字典元,其中依次包含了:
unsigned short preIndex:无符号短整型,长2字节,存储符号串的前缀的段号;unsigned char lastChar:无符号字符型,长1字节,存储符号串末尾字符;unsigned int Index:无符号整型,存储符号串的字典元在字典序列中的段号;vector<unsigned char> stringInDic:无符号字符型组成的vector容器变量(相当于字符串),用于存储完整的该符号串。
另外,class LZ78中还写了两个重要的函数:
- 函数 IfStringInDic: 返回bool类型值,表示当前符号串是否已经在字典中出现过。该函数要求传入
vector<Dictionary*>类型的变量,即编码中的字典和对应的vector(相当于字符串)。同时,传入的无符号整型Index是引用传递,这是为了让函数的执行结果能传递到外面的preIndex上,即找到并存储前缀的段号。该函数用于编码阶段; - 函数 FindPreString: 返回无符号字符类型的vector变量(相当于字符串)。要求传入字典和前缀数值。该函数用于解码阶段。
整体的编码和解码使用的就是 函数 lz_compress 和 函数 lz_decompress。这两个函数通过调用之前的两个重要的函数,能够简化其代码,最终实现LZ78的解码和编码。
class LZ78
{
public:
struct Dictionary //设置一个动态字典的单元
{
unsigned short preIndex; //2字节,前缀段号
unsigned char lastChar; //最后一位字符
unsigned int Index; //序列段号
vector<unsigned char> stringInDic; //完整符号串
};
void lz_compress(string originfile); //压缩文件
void lz_decompress(string sourcefile, string dstfile); //解压文件
private:
bool IfStringInDic(vector<Dictionary*> DataDic, vector<unsigned char> CurrentString, unsigned int &Index);
//判断字符串是否在字典中
vector<unsigned char> FindPreString(vector<Dictionary*> DataDic, unsigned int preindex);
//找到并返回前缀字符串
};
b. 主程序调用测试
借助前面定义的功能类,只要实例化LZ78 document;,就可以调用document.lz_compress和document.lz_decompress来对传入的文件进行压缩和解压。在测试时,也引入了clock( )来测试运行的时间,并通过cout<<来输出运行中的提示。基础代码如下所示。
int main(int argc, const char * argv[]) {
LZ78 document;
document.lz_compress("/Users/xrosheart/Desktop/news.txt"); //压缩文件
document.lz_decompress("/Users/xrosheart/Desktop/news.txt.lz", "/Users/xrosheart/Desktop/test.txt");
getchar();
return 0;
}
c. 功能类函数实现
1. 函数 lz_compress
首先是 处理文件的读写。这里不同于之前哈夫曼编码,这里 采用了C++风格的fstream来进行文件读写 的操作。这也算是小组合作的好处之一,能够相互学习不同的编写方式。
需要注意的是,在open操作时,要设置为ios::in|ios::binary,这是为了以二进制方式打开文件。要知道,由于历史原因,Windows 操作系统是用 两个字符\r\n来表示换行符的;而Unix操作系统却是用 单个字符\n来表示换行符 的。虽然无论是否指定二进制方式打开文件,读写的最小单位都是字节,但是在创建文件流时,如果指定了以ios::binary方式打开,那么换行符就是单字符的;否则,就采用Windows操作系统的双字符。
ifstream read;
read.open(originfile, ios::in|ios::binary);
if (!read )
{
cout << "文件读取错误" << endl << endl;
return;
}
ofstream write;
write.open(originfile + ".lz", ios::out|ios::binary);
if (!write)
{
cout << "输出文件不能建立(.lz)" << endl;
}
打开文件之后读入目标文件时,我们使用ifstream的read函数进行操作,每次读入一字符,也就是一字节的长度,即8位二进制码。同样地,输出操作时,我们使用ofstream的write函数进行对文件的写入。每次写入3字节,也就刚好把 Dictionary 类型的前两个变量,即 preIndex 和 lastChar 写入。那么在后面的解码操作时,读写也是一样的方式,只是该方式的逆操作。
//读入字符
unsigned char *now = new unsigned char;
read.read((char*)now, sizeof(unsigned char));
//输出压缩结果
Dictionary *currentInfo = new Dictionary;
write.write((char*)currentInfo,3);
接下来就是 边读入边建立字典编码的过程 了。这里首先要分两类,即第一次读入和接下来的读入,这是为了对于文件是否为空的操作。我们这里直接对接下来的读入进行分析。因为是边读入边建立字典,因此我们使用一个while循环包含了这些操作,涉及的变量如下所示。
//大循环外
vector<Dictionary*> DataDic; //使用vector建立字典,单元为后面的currentInfo
//大循环内
unsigned char *now = new unsigned char; //用于读取的字符
unsigned char *reallast = new unsigned char; //一组字符串除去已出现的前缀的末尾字符
vector<unsigned char> CurrentString; //当前字符串
unsigned int index = 0; //字符串存在在字典中的位置, 初始设为0
Dictionary *currentInfo = new Dictionary; //存储到字典单元中,使用动态指针,便于读写
我们使用函数 IfStringInDic 来作为do ... while的条件,每次找到一组新出现的字符串,然后前缀段号也由该函数通过引用传递到index变量中。而末尾字符也就存到*reallast指向的空间。最后把这些信息存入到字典单元*currentInfo中,然后将字典单元压入字典(vector)中,即DataDic.push_back(currentInfo);。每次都输出*currentInfo的前三字节到压缩输出文件中,也就是需要到码字了。
2. 函数 lz_decompress
该部分实际上与前面类似,不过会简单许多。同样都是建立字典,如果说压缩是将原文件转变为struct Dictionary然后输出 preIndex 和 lastChar 作为码字写入压缩文件;那么解压就是将压缩文件的码字的 preIndex 和 lastChar 转变为struct Dictionary,然后输出字典的 stringInDic。实际上就是互为逆过程。与之前不同的是,这里的采用的是vector<Dictionary> DataDic;和DataDic.push_back(*now);。这是因为指针类型的 vector 会导致码字解码的丢失,因此采用传统的 vector 形式。其中利弊会在优化中指出。
3. 函数 IfStringInDic 和 函数 FindPreString
这两个函数其实都比较简单。实际上就是对字典的遍历操作,但这两个函数中有一点区别,函数 IfStringInDic 中建立的 DataDic 是 Dictionary* 类型的vector,而函数 FindPreString 中建立的 DataDic 是 Dictionary 类型的vector。这两者的区别就在于遍历查找的速度差别。
4. 优化
实际上优化的点就在于数据结构的选择,即vector的单元中选择的单元类型是 Dictionary* 还是 Dictionary。在测试中发现,vector<Dictionary*>比vector<Dictionary>的查找要快了不少,但前者的存储空间调用更加负责,在解码的时候会产生码字流失现象。因此只在压缩中采取了前者的数据结构,而在解压中采用了后者的传统结构。
四、实验拓展与编码操作
实验对实现的哈夫曼编码和LZ-78编码进行了整合,即可以在一个程序下进行两种编码方式的切换选择,其简易操作界面展示如下。
1.打开项目,打开main.cpp文件并运行程序,可以看到如图的简易操作界面,上面提示我们选择编码方式,待选项有:选项1,哈夫曼编码;选项2,LZ-78编码。
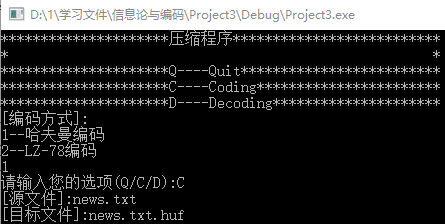
图1 运行操作界面
|
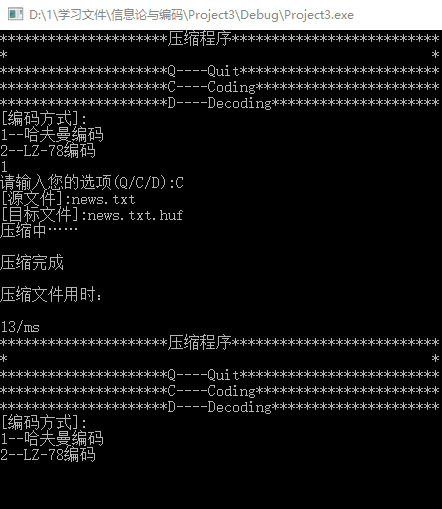
图2 哈夫曼编码压缩txt
| 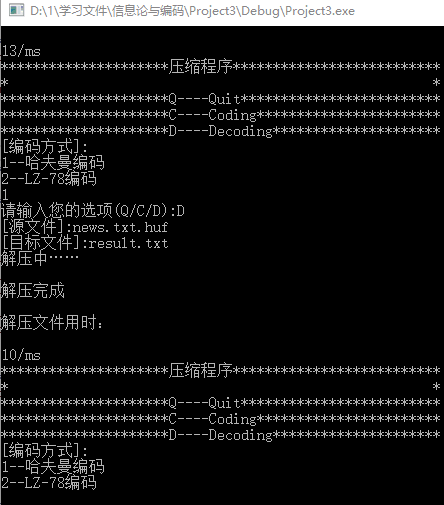
图3 哈夫曼编码解压txt
|
2.选择编码方式,我们先选择哈夫曼编码进行测试,即输入1,然后会车。接下来操作界面会提示请输入您的选项(Q/C/D):,其中Q表示退出程序,C表示编码压缩,D表示解码解压。这里我们先选择压缩,即输入C然后回车,如图2所示。
3.输入源文件和目标文件路径。在步骤2键入C后,会提示[源文件]:。这里既可以输入绝对路径(如E://user/…),也可以是相对路径(如图2)。输入完后,又会提示[目标文件]:,操作同上。
4.步骤3完成后就会开始压缩。这里是把目标文件news.txt压缩成news.txt.huf,同时程序会对压缩过程进行计时。如图3所示,这次 哈夫曼编码压缩txt用时13/ms。
5.接着对刚刚产生对压缩文件进行解压。我们选择1,也就是哈夫曼编码,再选择D,然后输入源文件news.txt.huf和解压文件result.txt,进行解压,结果如图4所示。可以看到这次 哈夫曼编码解压txt用时10ms。另外也可以从图5和图6的对比中看到,哈夫曼编码压缩和解压后的文件和原文件一模一样。

图4 news.txt 截图
| 
图5 result.txt 截图
| 
图6 result1.txt 截图
|
6.使用哈夫曼编码对news.docx进行压缩,压缩为news.docx.huf。操作过程与结果如图8所示,可见这次 哈夫曼编码压缩docx用时659ms。接着再对news.docx.huf进行解压,得到result.docx,其操作过程和结果如图9所示,可见这次 哈夫曼编码压缩docx用时239ms。
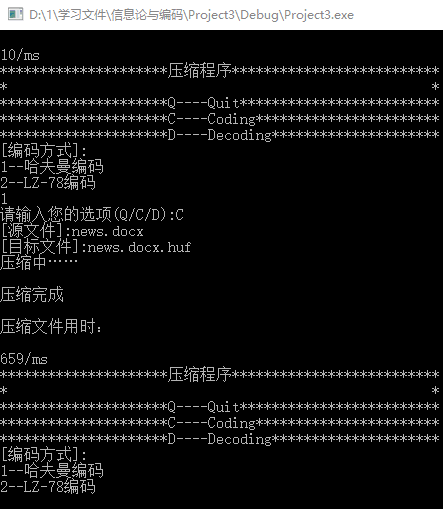
图7 哈夫曼编码压缩docx
| 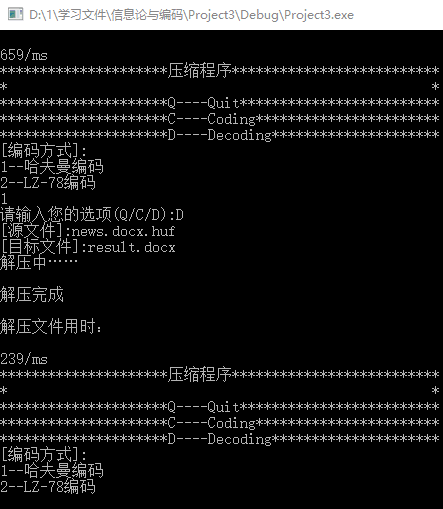
图8 哈夫曼编码解压docx
|
7.接下来对LZ-78编码进行测试。使用LZ-78编码把news.txt压缩为news.txt.lz,然后再把news.txt.lz解码为result1.txt,通过图9可见,生成文件与原文件一模一样。压缩过程如图10所示,解压过程如图11所示,可见这次LZ-78编码txt用时24s,解压txt用时49s。其x
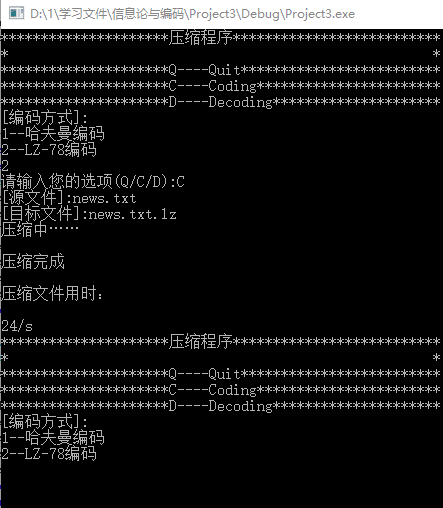
图9 LZ-78编码压缩txt
| 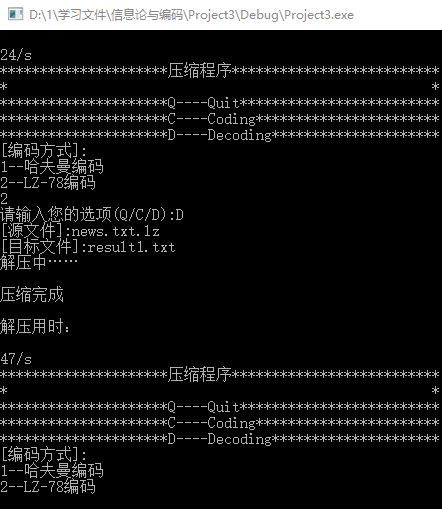
图10 LZ-78编码解压txt
|
以上就是整合的两种编码方式简易操作界面的操作过程,通过使用C++的clock( )进行计时来记录编码解码的用时,通过对前后文件大小的变化衡量编码效率。该过程也可以进行哈夫曼和LZ-78的编码效果对比。
五、编码结果与性能分析
1. 哈夫曼编码
操作环境: Windows10,Visual Studio 2017。
测试用例: 使用了老师所给的17KB的news.txt文件、531KB的news.docx,以及自己随机找的96KB的little.docx和17.6M的large.docx,包括了 txt、docx和mp4三种文件类型,和4个不同数量级的文件大小,小到17KB,大到30.2M,测试范围涵盖全面。
测试数据: 主要测试压缩前后文件大小,计算压缩率;另外记录编码和解码用时。具体数据如下所示。
| 原始文件 | news.txt (17KB) | little.docx (96KB) | news.docx (531KB) | large.docx (17.6M) | test.mp4 (30.2M) |
|---|---|---|---|---|---|
| 压缩文件 | news.txt.huf (10KB) | little.docx.huf (96KB) | news.docx.huf (531KB) | large.docx (17.6M) | test.mp4.lz (30.2M) |
| 压缩率 | 58.8% | 1 | 1 | 1 | 1 |
| 编码用时 | 10ms | 133ms | 659ms | 24164ms | 44s |
| 解码用时 | 4 | 63ms | 239ms | 7742ms | 15s |
可见编写的哈夫曼编码适用范围广,对于txt、docx、mp4视频等文件均适用,而且编码解码速度较快。不足之处在于,虽然对于txt文件有着优秀的压缩率,但对于docx、mp4这类较大较负责的文件,几乎无压缩效果。这点也是需要后期有机会改进的。
2. LZ-78编码
该算法最初在macOS Xcode 10.1上编写调试,初步效果对于txt和较小的docx文件较好。出于在算法设计中提到的,译码时采用指针类型vector会导致码字丢失,故在解码过程中采用了传统的vector数据结构,速度较慢。这也在测试数据中明显地体现出来了:编码用时比解码用时少,编码速度较快而解码速度稍慢。
| 原始文件 | news.txt (17KB) | little.docx (98KB) |
|---|---|---|
| 压缩文件 | news.txt.lz (13KB) | little.docx.lz (122KB) |
| 压缩率 | 76.5% | 1.24 |
| 编码用时 | 44ms | 30ms |
| 解码用时 | 275ms | 202s |
然而,或许是因为macOS类Linux系统与Windows系统的差别,二者对于指针存储结构的处理能力差别较大。因此在win10的 Visual Studio 2017上效果明显劣于macOS上的表现。
| 原始文件 | news.txt (17KB) | little.docx (96KB) |
|---|---|---|
| 压缩文件 | news.txt.huf (13KB) | little.docx.lz (96KB) |
| 压缩率 | 76.5% | 1.24 |
| 编码用时 | 24s | 2547s |
| 解码用时 | 47s | / |
可见 此处实验使用的LZ-78实现算法更适合在macOS系统上使用。从这其中发现的 系统差别对于编码性能的影响 也算是实验的意外收获了。
3. 算数编码
对96KB的news.txt文件进行算数编码,压缩结果如图10所示,压缩总 bit 数为 137872 bit,其中0的概率为 54.3%,1的概率为 47.3%。压缩用时271ms,解压用时1ms。
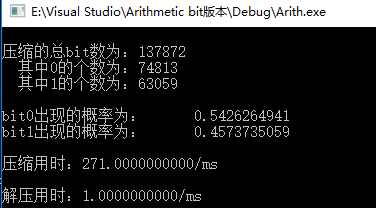
图11 编码字符串1字节news.txt结果
|
由于未能在代码中解决浮点数在运算和存储中精度的不确定性,因此编码效率无法到达100%,会产生一定的无码,因而无法压缩docx文档。
另外,在压缩txt文件时,随着待编码字符串长度的增加,对浮点数精确度要求更高,编码准确率降低,以下显示待编码字符串长度为1字节、2字节、3字节时的压缩情况。
图12 编码字符串1字节时情况
|

图13 编码字符串2字节时情况
|

图14 编码字符串3字节时情况
|
六、问题总结与体会
以上信源编码的实现需要深刻地理解 哈夫曼编码、LZ编码与算数编码 的原理,并且明白了不同编码的实现方式。一开始时,由于对于这些编码方式的理解并不深刻,对于该如何用程序实现代码也没有思路,所以进展比较缓慢。于是尝试首先理解这些编码的基本编码原理,再尝试利用C++代码实现这些编码的字典,一步步走,最后得以写出完整的编码。
在实现哈夫曼编码的过程中,最初不知道怎样将文件进行读入或者读出,所以最初实现的编码方式是通过指令台输入要编码的信源序列,并且采用一个数组来保存它,对它进行读取扫描来实现哈夫曼树或者建立字典,但是由于数组长度有限,而且希望以文件格式输入输出,所以最开始实现的程序需要在很大程度上进行改进;此外,在实现哈夫曼树的过程中时,当一步步将概率合并以将哈夫曼树走到上层之后,如何一步步返回到下层又成了问题。
在实现LZ-78编码的过程中,遇到的两个主要问题就是如何实现bit单位的变长码字以及如何存储字典数据。在查阅资料以及不同数据结构的尝试下,找到了较优的数据结构,即采用指针单位的vector数据类型。另外对于变长码字,由于bit单位的操作较为负责,退而求其次,采用了一个上限长度,不过缺点在于造成了一定的冗余。在macOS的Xcode移植到win10的VS上时,发现了 系统与编译器对编码算法性能的巨大影响。通过查阅资料了解了VS和Xcode的性能比对后,将 原因归结于系统的差别——类Linux系统和windows系统在存储方式的差别对指针类型存储结构的操作性能差异。
在实现算数编码的过程中,最初是对每一个字符进行编码。由于 A S C I I ASCII ASCII码对应的长度为一个字节而许多中文字符对应的长度为两个字节,因此单纯对一个字符进行编码会造成不同字符长度不一致的问题。最后决定对文件中一个字节一个字节读入,然后对 8位比特的256种不同的可能性 进行编码。由于算数编码需要对不同的字符的概率进行映射,而一个文本中8位不同的比特可能组合会高达数十种,造成有些概率非常接近,最终精度不够,编码正确率不够高。最后采取的方式为将文件分割成比特形式,统计比特0和比特1出现的概率并在此基础上编码,提升了准确率。
最后,将哈夫曼编码和LZ-78整合在一起的过程也遇到了一些阻力:一方面是对VS不够了解,另一方面对于整合用的main.cpp的设计。不过有了之前编码实现的提示,也都比较顺利地解决了困难,最终做出了一个 简易的操作界面,实现了 哈夫曼编码和LZ-78的选择编码。

















 2927
2927

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









