







LR译码
LR是likelihood ratio的缩写。由于编码矩阵是二元域矩阵,那么我们有,所以完全可以理解为译码为编码的逆过程。那么可以得到当编码输入数据长度为2时,译码过程如下图所示
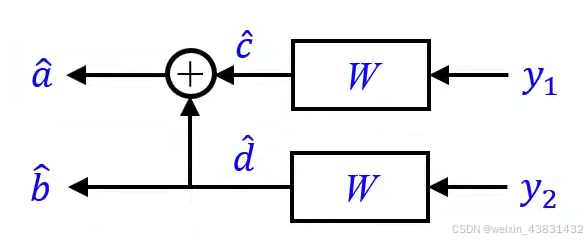
推导过程如下:
推导过程如下:
if
if
所以可以得到
同理,当编码输入长度为4时,译码过程如下
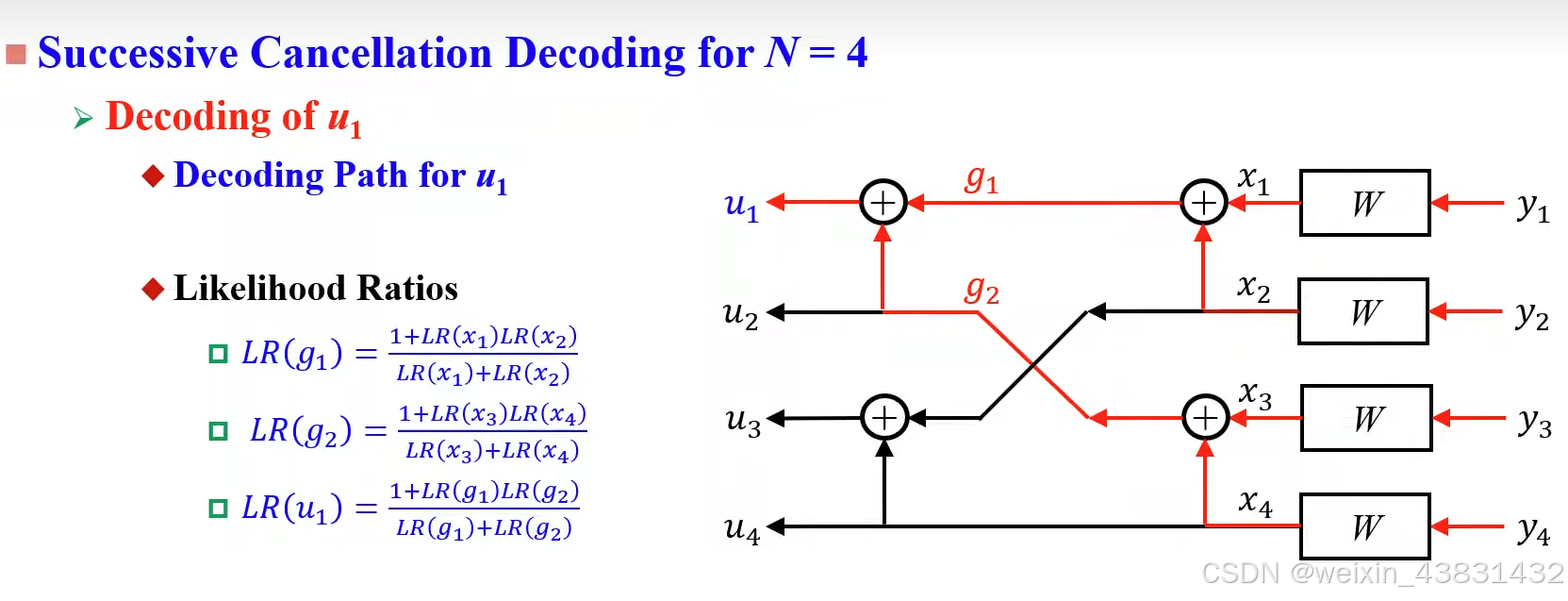
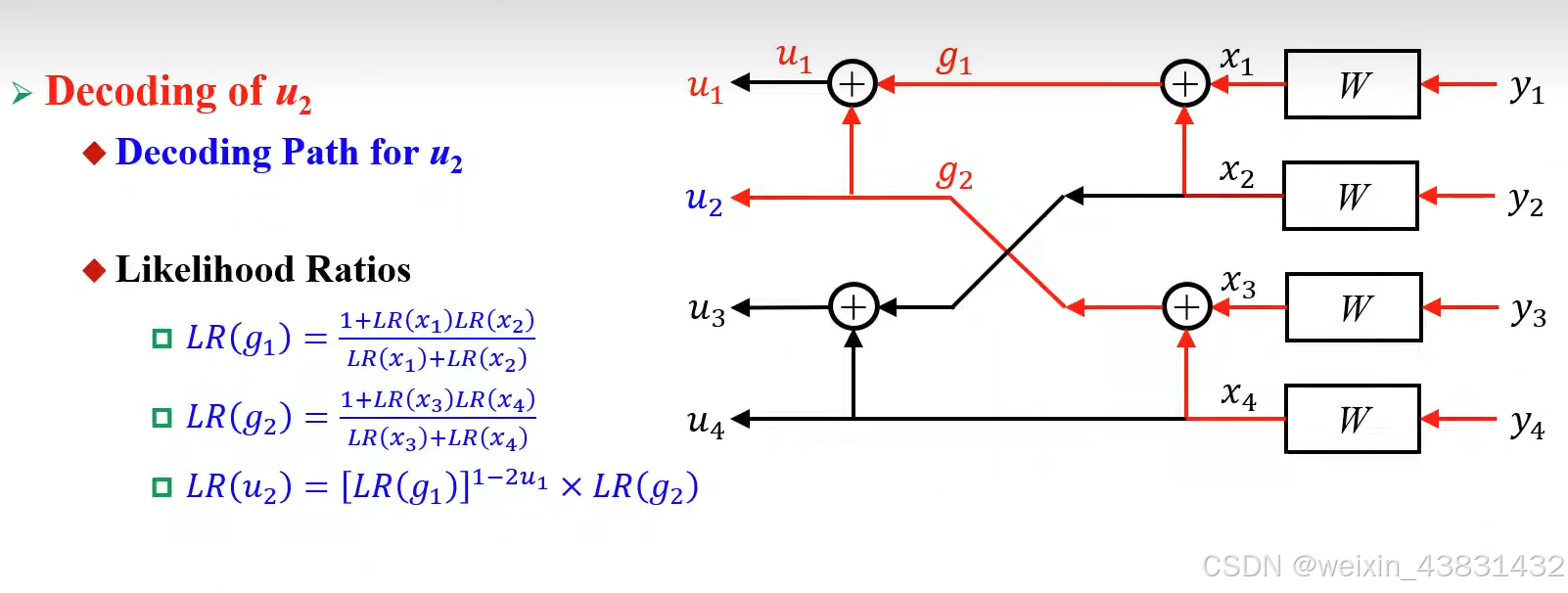
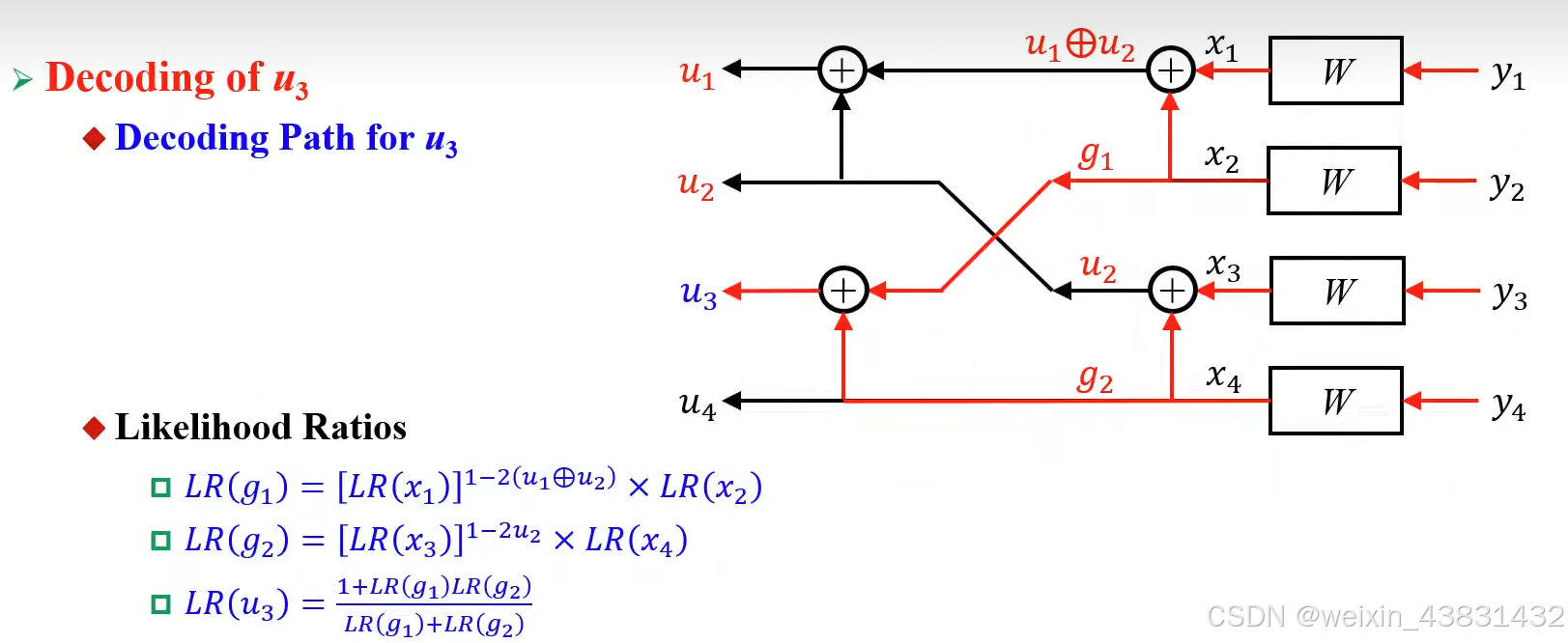
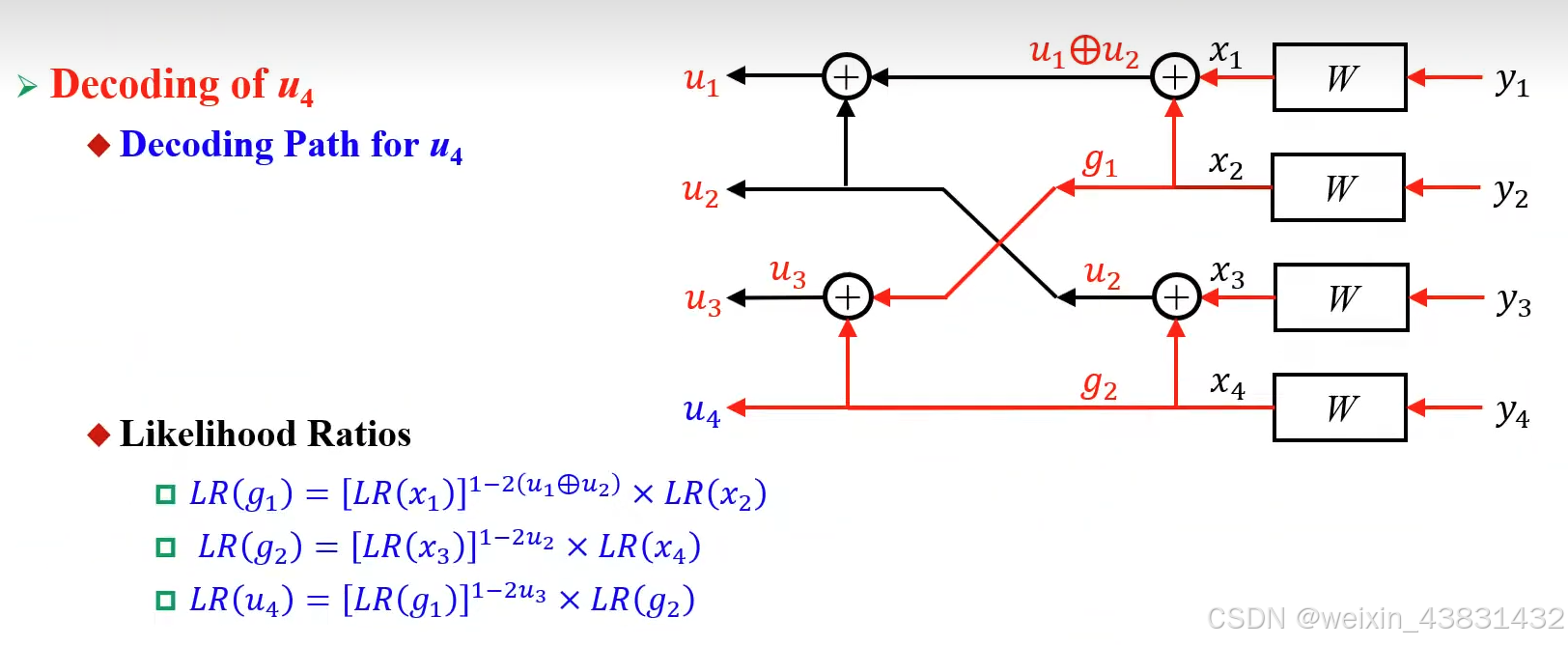
进一步的,我们可以用二叉树的形式总结出极化码译码过程

我们可以看到,u1,u2,u3,u4的译码二叉树基本一致,除了输入u的不同。
我们可以引出g-node和f-node的概念
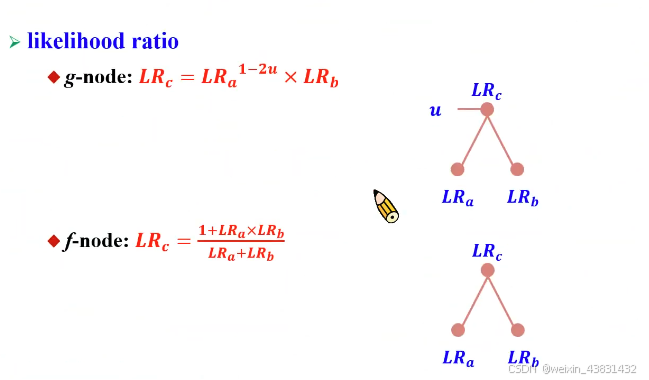
有u输入的,被称为g-node,没有u输入的,称为f-node。
那么如何确定每个节点有没有u输入以及u是多大呢?下面介绍一种利用生成矩阵产生u的方法
- step 1
将M(前面译出的码元个数)写成二进制形式
i表示被分配bit节点所在层数
- step 2
将已解码bit向量分成子向量
,包含
个bit,如下图所示

- step 3
按下面公式计算在第层的node bits,G为生成矩阵
![]()
- step 4
将node bits分配到相应节点,然后开始译码
下面举个例子来说明
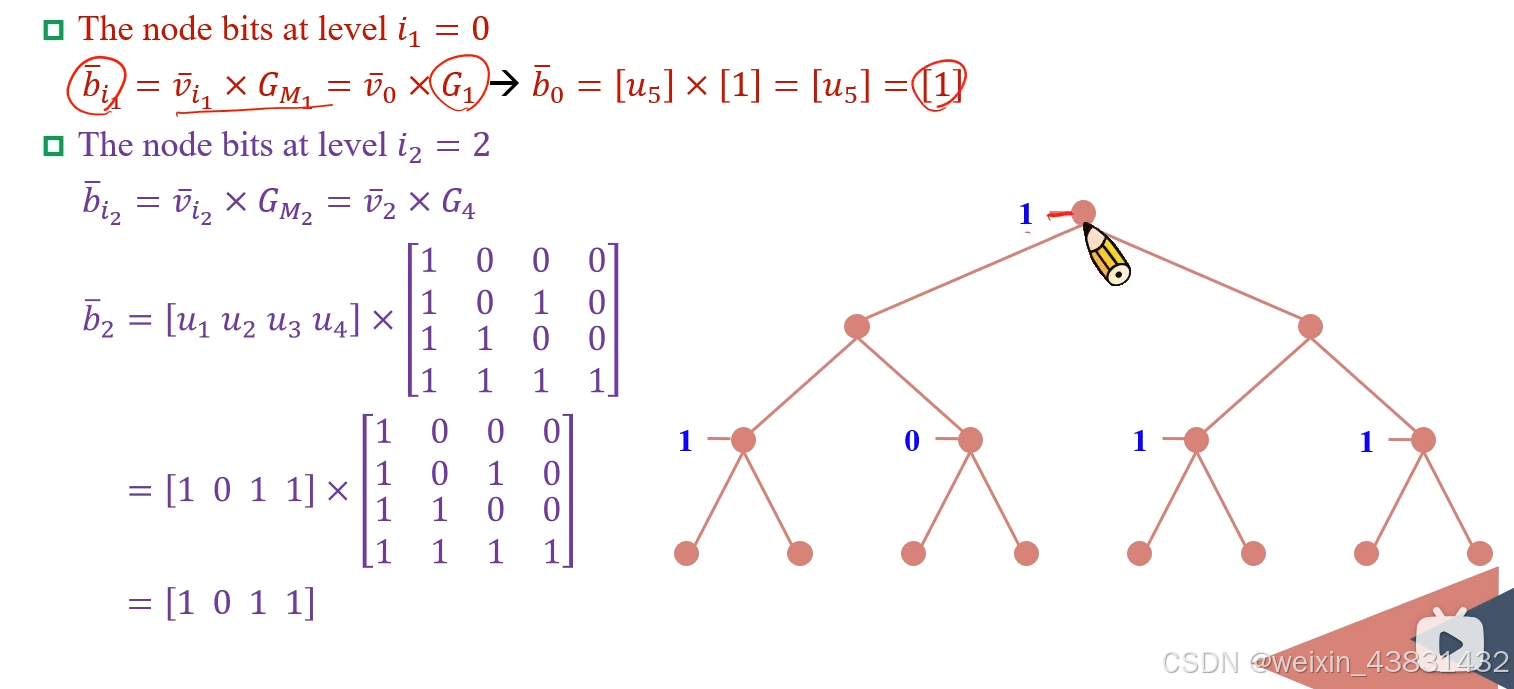
当极化码code word长度N=8时,假设我们现在前5bit为[1 0 1 1 1],我们现在要译码第六个bit,我们开始尝试用上面方法来完成译码:
- step 1
- step 2
为u5,
为[u1,u2,u3,u4]
- step3

















 3197
3197

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









