






语义分割经典网络记录
1、VGG-16
论文作者:http://www.robots.ox.ac.uk/~vgg/research/very_deep/ (哈佛Oxford)
tf实现:https://www.cs.toronto.edu/~frossard/post/vgg16/

网络具体配置图:

2、FCN
在VGG16基础上改进的(Skip Architectures for Segmentation )跳跃连接

SegNet

Bayesion SegNet
—— SegNet的概率扩展 ,由原班人马推出 (分割性能提高2-3%)

贝叶斯SegNet是贝叶斯卷积神经网络的一种实现,它可以产生语义分割的模型不确定性估计。它在测试时使用Monte Carlo Dropout [5]来生成像素类标签的后验分布。 Bayesion SegNet表明,这可以显着提高分割精度,并提供模型不确定性的度量。
模型不确定性可用于理解我们可以信任图像分割的可信度,并确定我们可以分配语义标签的特定程度。 例如,我们可以说标签是卡车,还是简单的移动车辆? 这可以对机器人的行为决策产生强烈影响。
该模型不确定性与从softmax分类器获得的“概率”显着不同。 softmax函数近似于类标签之间的相对概率,但不是模型不确定性的总体度量。 有关更深入的解释,请查看Yarin的博客文章:深层模型不知道的是…

训练:SGD(stochastic gradient descent )with a base learning rate of
0.001 and weight decay parameter equal to 0.0005.
tips
Dropout
在传统神经网络中DropOut层的主要作用是防止权值过度拟合,增强学习能力。DropOut层的原理是,输入经过DropOut层之后,随机使部分神经元不工作(权值为0),即只激活部分神经元,结果是这次迭代的向前和向后传播只有部分权值得到学习,即改变权值。
BN层
Batch Normalization,批规范化
转自
假设在网络中间经过某些卷积操作之后的输出的feature map的尺寸为4×3×2×2
4为batch的大小,3为channel的数目,2×2为feature map的长宽
对于所有batch中的同一个channel的元素进行求均值与方差,求取完了均值与方差之后,对于这16个元素中的每个元素进行减去求取得到的均值与方差,然后乘以gamma加上beta,公式如下
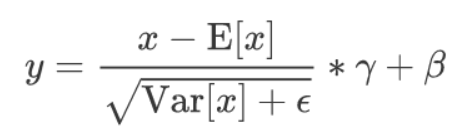
batch normalization层能够学习到的参数,对于一个特定的channel而言实际上是两个参数,即gamma与beta,对于多个channel而言,学习参数是channel数目的两倍。
BN还作为一个正则化(Regularizer),可以减少或避免使用Dropout。
Relu
Softmax
他把一些输入映射为0-1之间的实数,并且归一化保证和为1,因此多分类的概率之和也刚好为1。















 2096
2096











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









