







损失函数
✔️ SSD的损失函数包括两部分的加权:
- 位置损失函数 L_loc
- 置信度损失函数 L_conf
整个损失函数为:
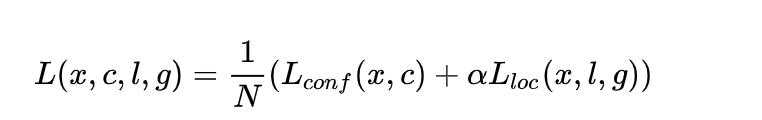
其中:
- N 是先验框的正样本数量;
- c 为类别置信度预测值;
- l 为先验框的所对应边界框的位置预测值;
- g 为ground truth的位置参数。
1.对于位置损失函数
针对所以的正样本,采用 Smooth L1 Loss ,位置信息都是 encode 之后的信息。
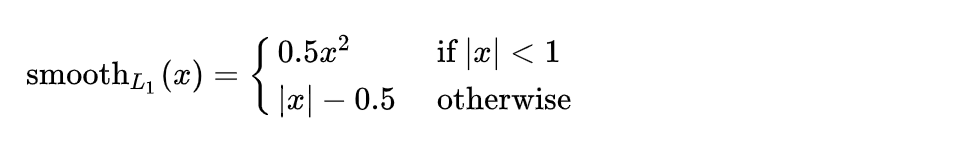
2. 对于置信度损失函数:
首先需要使用 hard negative mining 将正负样本按照 1:3 的比例把负样本抽样出来,抽样的方法是:
思想: 针对所有batch的confidence,按照置信度误差进行降序排列,取出前top_k个负样本。
编程:
- Reshape所有batch中的conf
batch_conf = conf_data.view(-1, self.num_classes)
- 置信度误差越大,实际上就是预测背景的置信度越小。
- 把所有conf进行logsoftmax处理(均为负值),预测的置信度越小,则logsoftmax越小,取绝对值,则**|logsoftmax|越大,降序排列-logsoftmax**,取前 top_k 的负样本。
详细分析



python代码:
def log_sum_exp(x):
x_max = x.detach().max()
return torch.log(torch.sum(torch.exp(x-x_max), 1, keepdim=True))+x_max
conf_logP 表示为:
conf_logP = log_sum_exp(batch_conf) - batch_conf.gather(1, conf_t.view(-1, 1))
#gather:沿给定轴dim,将输入索引张量index指定位置的值进行聚合。
gather函数参考链接
排除正样本:
conf_logP.view(batch, -1) # shape[b, M]
conf_logP[pos] = 0 # 把正样本排除,剩下的就全是负样本,可以进行抽样
两次sort,能够得到每个元素在降序排列中的位置idx_rank
_, index = conf_logP.sort(1, descending=True)
_, idx_rank = index.sort(1)
使用一次sort和两次sort的区别:
一次sort:得到的index是按顺序排的索引
两次sort:得到原Tensor的映射,排第几的数字变为排名
两次sort的巧妙运用
可以参考下图:

后续,就可以筛选出所需的负样本,配合正样本求出conf的cross entropy。
完整loss代码
import torch
import torch.nn as nn
import torch.nn.functional as F
from vgg_backbone import voc
from box_utils import match, log_sum_exp
class MultiBoxLoss(nn.Module):
def __init__(self, num_classes, overlap_thresh, neg_pos, use_gpu=False):
#(cfg['num_classes'], 0.5, True, 0, True, 3, 0.5,False, args.cuda)
super(MultiBoxLoss, self).__init__()
self.use_gpu = use_gpu
self.num_classes = num_classes
self.threshold = overlap_thresh #匹配时需要的iou阈值
self.negpos_ratio = neg_pos#需要训练的负正样本比例
self.variance = voc['variance']
forward函数中,为计算损失函数,需要先对数据进行包括匹配、正样本寻找等的操作:
def forward(self, pred, targets):
"""forward函数第一部分的内容
输入:
pred(tuple): 一个三元素的元组,包含了预测信息.
loc_data [batch,num_priors,4] 所有默认框预测的offsets.
conf_data [batch,num_priors,num_classes] 所有预测框预测的分类置信度.
priors [num_priors,4] 所有默认框的位置
targets [batch,num_objs,5] (last idx is the label).所有真实目标的信息
返回:
loss_l, loss_c:定位损失和分类损失
"""
loc_data, conf_data, priors = pred
batch = loc_data.size(0) #batch
num_priors = priors[:loc_data.size(1), :].size(0) # 先验框个数
# 获取匹配每个prior box的 ground truth
#[batch, num_priors, 4] 匹配到的真实目标和默认框之间的offset,是learning target
loc_t = torch.Tensor(batch, num_priors, 4)
#[batch, num_priors] 匹配后默认框的类别,是learning target
conf_t = torch.LongTensor(batch, num_priors)
#对于batch中的每一个图片进行匹配
for idx in range(batch):
truths = targets[idx][:, :-1].detach() # ground truth box信息 [num_objs,4]
labels = targets[idx][:, -1].detach() # ground truth conf信息 [num_objs,1]
defaults = priors.detach() # priors的 box 信息
# 匹配 ground truth
match(self.threshold, truths, defaults,
self.variance, labels, loc_t, conf_t, idx)
#match函数具体见第二篇博客
# use gpu
if self.use_gpu:
loc_t = loc_t.cuda()
conf_t = conf_t.cuda()
#正样本查找,等于0为背景 [batch, num_priors]
pos = conf_t > 0
定位损失
# Localization Loss,使用 Smooth L1
# shape[b,M]-->shape[b,M,4]
pos_idx = pos.unsqueeze(2).expand_as(loc_data)
#[batch*num_positive, 4] loc_data保存了所有默认框的predict offset,loc_p保存其中的正例
loc_p = loc_data[pos_idx].view(-1,4)
#[batch*num_positive, 4] loc_t保存了所有默认框的target offset,loc_t保存其中的正例
loc_t = loc_t[pos_idx].view(-1,4)
# Smooth L1 损失
loss_l = F.smooth_l1_loss(loc_p, loc_t)
难负样本挖掘
'''
Target;
下面进行hard negative mining
过程:
1、 针对所有batch的conf,按照置信度误差(预测背景的置信度越小,误差越大)进行降序排列;
2、 负样本的label全是背景,那么利用log softmax 计算出logP,
logP越大,则背景概率越低,误差越大;
3、 选取误差交大的top_k作为负样本,保证正负样本比例接近1:3;
'''
# shape[b*M,num_classes]
batch_conf = conf_data.view(-1, self.num_classes)
# 使用logsoftmax,计算置信度,shape[b*M, 1]
conf_logP = log_sum_exp(batch_conf) - batch_conf.gather(1, conf_t.view(-1, 1))
# hard Negative Mining
conf_logP = conf_logP.view(batch, -1) # shape[b, M]
conf_logP[pos] = 0 # 把正样本排除,剩下的就全是负样本,可以进行抽样
# 两次sort排序,能够得到每个元素在降序排列中的位置idx_rank
_, index = conf_logP.sort(1, descending=True)
_, idx_rank = index.sort(1)
#各个框loss的排名,从大到小 [b,M]
# 抽取负样本
# 每个batch中正样本的数目,shape[b,1]
num_pos = pos.long().sum(1, keepdim=True) #[b,1]
num_neg = torch.clamp(self.negpos_ratio*num_pos, max= pos.size(1)-1) #[b,1]
neg = idx_rank < num_neg # 抽取前top_k个负样本,shape[b, M]
分类损失
# shape[b,M] --> shape[b,M,num_classes]
pos_idx = pos.unsqueeze(2).expand_as(conf_data)
neg_idx = neg.unsqueeze(2).expand_as(conf_data)
# 提取出所有筛选好的正负样本(预测的和真实的)
conf_p = conf_data[(pos_idx+neg_idx).gt(0)].view(-1, self.num_classes)
conf_target = conf_t[(pos+neg).gt(0)]
# 计算conf交叉熵
loss_c = F.cross_entropy(conf_p, conf_target)
# 正样本个数
N = num_pos.detach().sum().float()
loss_l /= N
loss_c /= N
return loss_l, loss_c
测试:
# 调试代码使用
if __name__ == "__main__":
loss = MultiBoxLoss(21, 0.5, 3)
p = (torch.randn(1,100,4), torch.randn(1,100,21), torch.randn(100,4))
t = torch.randn(1, 10, 4)
tt = torch.randint(20, (1,10,1))
t = torch.cat((t,tt.float()), dim=2)
l, c = loss(p, t)
# 随机randn,会导致g_wh出现负数,此时结果会变成 nan
print('loc loss:', l)
print('conf loss:', c)
结果:
loc loss: tensor(11.9424)
conf loss: tensor(2.0487)















 1266
1266











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









