







图像-海洋生物探索 未来杯赛题
———————— 一个fastai的简单使用
1.导入fast.ai和将要用到的其他库
from pathlib import Path
from fastai import *
from fastai.vision import *
import torch
import seaborn as sns
import warnings
from sklearn.metrics import classification_report, confusion_matrix
warnings.filterwarnings('ignore')
2.读取数据
data_folder = Path("/content/drive/My Drive/data/Future_cup")
train_df = pd.read_csv("/content/drive/My Drive/Future_cup/training.csv")
test_df = pd.read_csv("/content/drive/My Drive/Future_cup/test.csv")
3.查看数据
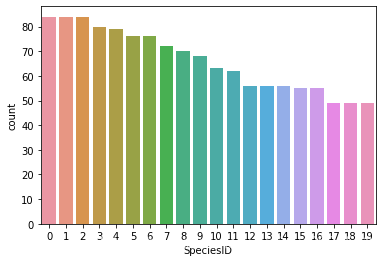
利用countplot函数来查看培训数据的分布情况,从图中可以看到数据分布比较均衡。
sns.countplot(train_df.SpeciesID)
4.向模型传入数据
采用fast.ai的DataBlock API来构造数据,这是向模型输送数据集的一种简易的方法。
-
利用ImageList的from_df方法来保存训练数据,这样做是因为将有关训练集的信息存储在名字为df的数据帧中,让它能找到训练图像所在的路径和保存图像的文件夹名称,train_images.
-
接下来,使用随机分割来对训练集进行分割,留出10%的数据来监控模型在训练过程中的性能。选择一颗种子,以确保再次检查时能得到同样的结果,我们必须知道什么在起作用,什么不起作用。
-
告诉ImageList在训练集中的数据的标签所在地,利用has_oilpalm方法将组合后的数据添加到测试数据中。
-
最后,对数据进行转换,利用imagenet_stats对图像归一化处理。
#训练集
train_img = (ImageList.from_df(train_df, path=data_folder)
.split_by_rand_pct(0.1)
.label_from_df('SpeciesID')
.add_test(test_img)
.transform(trfm, size=224)
.databunch(bs=48)
.normalize(imagenet_stats)
)
train_img
#测试集
test_img = ImageList.from_df(test_df, path=data_folder)
test_img

5.数据增强
常用数据增强方法:
(1) 几何变换类
- 水平翻转和垂直翻转
- 随机旋转
- 随机裁剪
变形缩放
(2) 颜色变换类 - 添加Coarse Dropout噪声
- 颜色扰动
tfm = [crop(size=224, row_pct=0.7, col_pct=0.7), rand_crop()]
trfm = get_transforms(do_flip=True,
max_rotate=10.0,
max_zoom=1.25,
max_lighting=0.2,
max_warp=0.2,
p_affine=0.65,
p_lighting=0.55,
xtra_tfms=tfm)
6.图像预览
train_img.show_batch(rows=3, figsize=(7,6))

7.训练模型
现在开始训练模型,采用卷积神经网络骨干,并使用预先训练的权重,这个权重从一个已经训练好的图像分类的resnet模型中直接获得。
learn = cnn_learner(train_img, models.resnet152, metrics=[error_rate, accuracy])
callbacks = [
#callbacks.EarlyStoppingCallback(learn, min_delta=1e-5, patience=3),
callbacks.SaveModelCallback(learn)
]
learn.callbacks = callbacks
找出最优的模型学习率
接下来,使用lr_find()找到理想的学习率,并利用recorder.plot().对它可视化。
learn.lr_find()
learn.recorder.plot()

选择一个接近坡度最陡之处的学习速率,在这个示例中是1e-3。
冻结部分卷积层训练
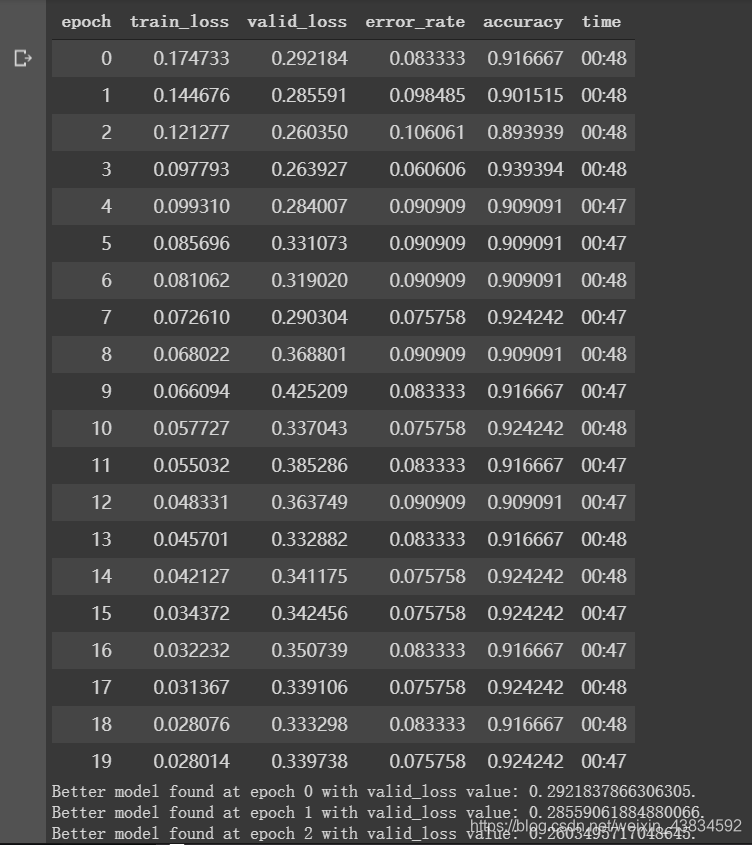
learn.freeze_to(5)
learn.fit_one_cycle(20, slice(1e-4 ,1e-2))
解冻训练
结果分析
查看训练过程中损失最大的图片,以便分析原因
interp = ClassificationInterpretation.from_learner(learn)
interp.plot_top_losses(12)

测试数据
在这里插入代码片
preds, _ = learn.TTA(ds_type=DatasetType.Test)
test_df['label'] = np.argmax(preds.numpy(), axis=1)
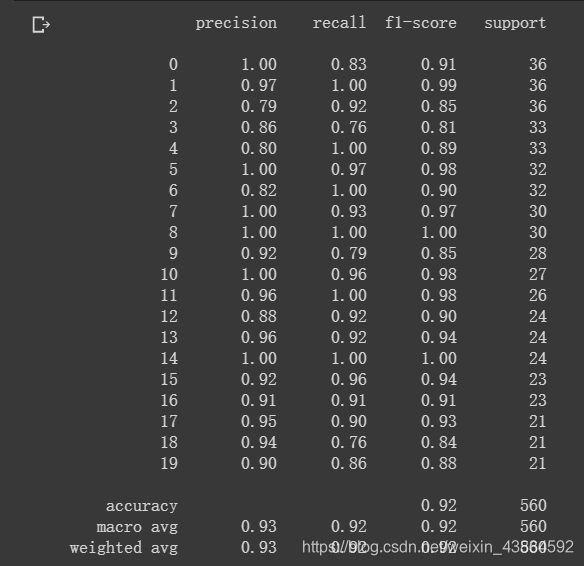
利用混淆矩阵查看结果
print(classification_report(test_label['SpeciesID'], test_df['label']))
print(confusion_matrix(test_label['SpeciesID'], test_df['label']))















 317
317











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









