







目录
论文简介
本文引用格式:
- W. Zhao, C. Wu, R. Zhong, K. Shi and X. Xu, “Edge Computing and Caching Optimization Based on PPO for Task Offloading in RSU-Assisted IoV,” 2023 IEEE 9th World Forum on Internet of Things (WF-IoT), Aveiro, Portugal, 2023, pp. 01-06, doi: 10.1109/WF-IoT58464.2023.10539436. [paper],[code]
发表在WF-IoT会议,在RSU辅助IoV 场景中,使用PPO对缓存和计算卸载进行优化。
论文总结:
- 这篇论文的主要内容是提出了一种基于**近端策略优化算法(PPO)的边缘计算与缓存优化方案,用于在路边单元(RSU)辅助的车联网(IoV)**中进行任务卸载。论文的关键要点如下:
1. 背景问题
- 移动边缘计算(MEC)和边缘缓存技术被认为是增强自动驾驶的一种解决方案,但现有技术面临两个主要挑战:
- 车辆请求不断变化,内容的流行度难以预测。
- 现有的被动计算和缓存技术无法有效应对计算密集型和对延迟敏感的任务请求。
2. 解决方案
- 为了解决上述挑战,作者提出了一种主动感知的边缘计算和缓存优化方案:
- RSUs 主动感知可能会被车辆请求的任务,并根据预测的内容流行度进行计算和缓存。
- 重点是选择合适的边缘计算和缓存节点,以最小化任务计算延迟并最大化缓存效益。
3. 技术方法
- 作者将问题表示为0-1整数规划问题,并将其转化为马尔可夫决策过程(MDP)。
- 为了解决该问题,他们使用了**深度强化学习(DRL)中的近端策略优化(PPO)**算法。
- 该算法通过模拟和学习,逐步优化边缘计算和缓存决策,以减少长期平均计算延迟,并提高对车辆请求的响应率。
4. 系统模型
- 系统由云服务器、多个RSUs和自动驾驶车辆组成,分别作为不同类型的计算节点。
- RSUs在每个时间片主动感知道路环境,检测需要处理的任务,并进行缓存决策。
- 内容流行度通过使用Hawkes模型进行预测,以提高缓存的命中率。
5. 实验结果
- 通过仿真实验,验证了该方案在减少计算延迟和提高缓存命中率方面的有效性。
- 实验结果表明,提出的方案在长期运行中有效减少了平均计算延迟,并且显著提高了对车辆请求的响应率,尤其是在缓存容量有限的情况下表现优异。
6. 结论
- 论文提出了一种基于PPO的创新边缘计算和缓存方案,能够有效优化任务卸载,提升车联网环境中的系统性能。
- 该方案不仅能够在动态环境中自适应调整,还能在任务卸载和缓存命中率之间取得平衡。
论文复现
- 阅读github的readme文件,只需要装一下numpy 1.21.4和python 3.9.6环境哈,可能还会缺其他的包,到时在安装,readme的环境配置方面写的一般,告诉了要运行哪几个py文件,出图。
- 本人使用了VScode+Anaconda配置python环境,每次复现论文的python环境不同,复现就新建一个,安装相应的版本及各种依赖包。
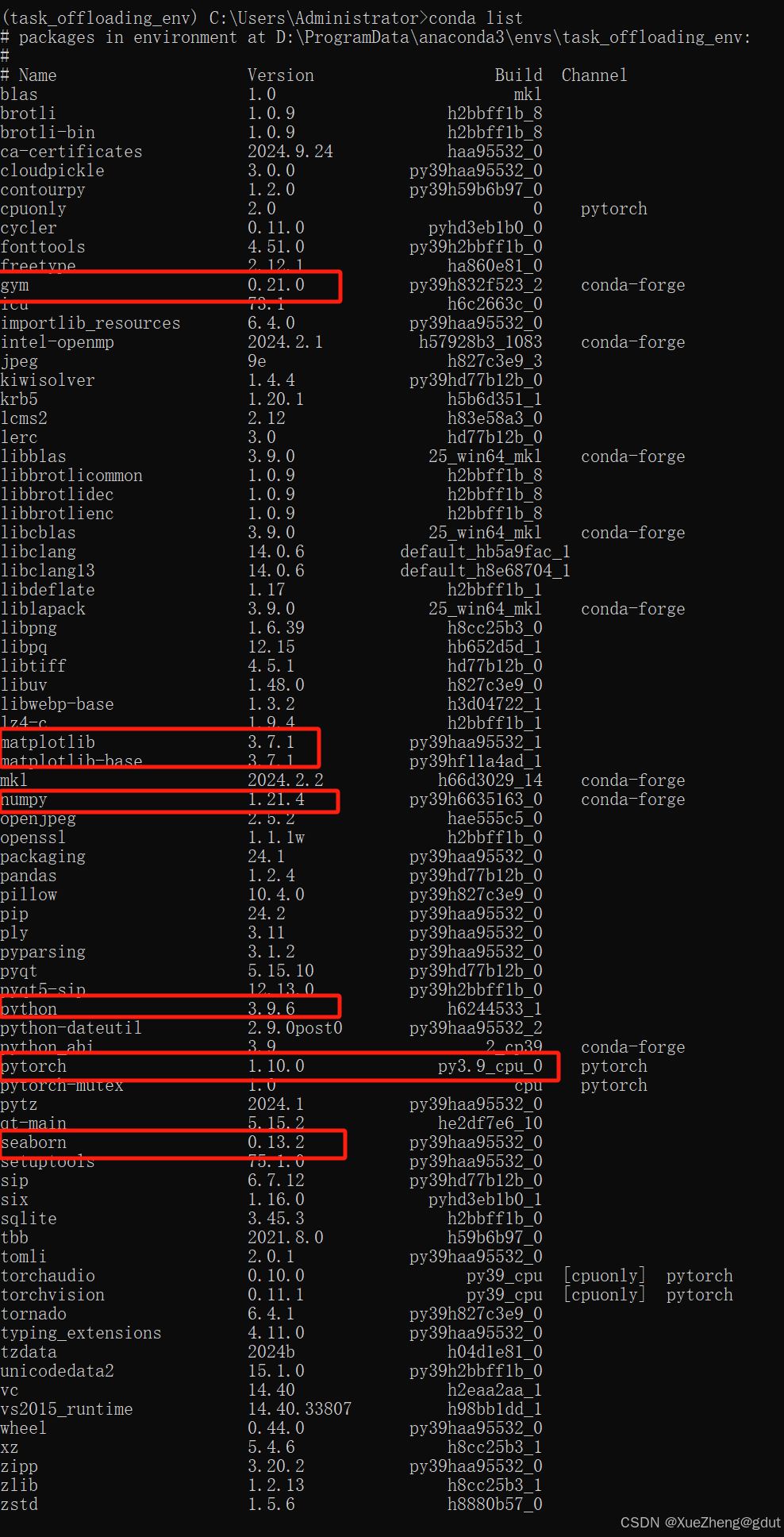
下面是复现后这个环境中需要配置的一些包的版本信息供参考:
VScode会遇到导入目录中其他python文件模块,找不到该模块的情况,需要将项目的源目录路径添加到执行环境,配置一下launch.json文件!
{
// 使用 IntelliSense 了解相关属性。
// 悬停以查看现有属性的描述。
// 欲了解更多信息,请访问: https://go.microsoft.com/fwlink/?linkid=830387
"version": "0.2.0",
"configurations": [
{
"name": "Python: 当前文件",
"type": "debugpy",
"request": "launch",
"program": "${file}",
"console": "integratedTerminal",
"justMyCode": false,
"env": {
"PYTHONPATH": "${workspaceFolder}"
}
}
]
}
GPT解决复现问题的部分截图
复现过程必然遇到困难,借助生成式人工智能、博客解决遇到的困难,关键还是在于你能否准确描述清楚你的问题让gpt理解,或匹配到相关的博客!
导入模块的路径问题(描述清楚具体的路径):
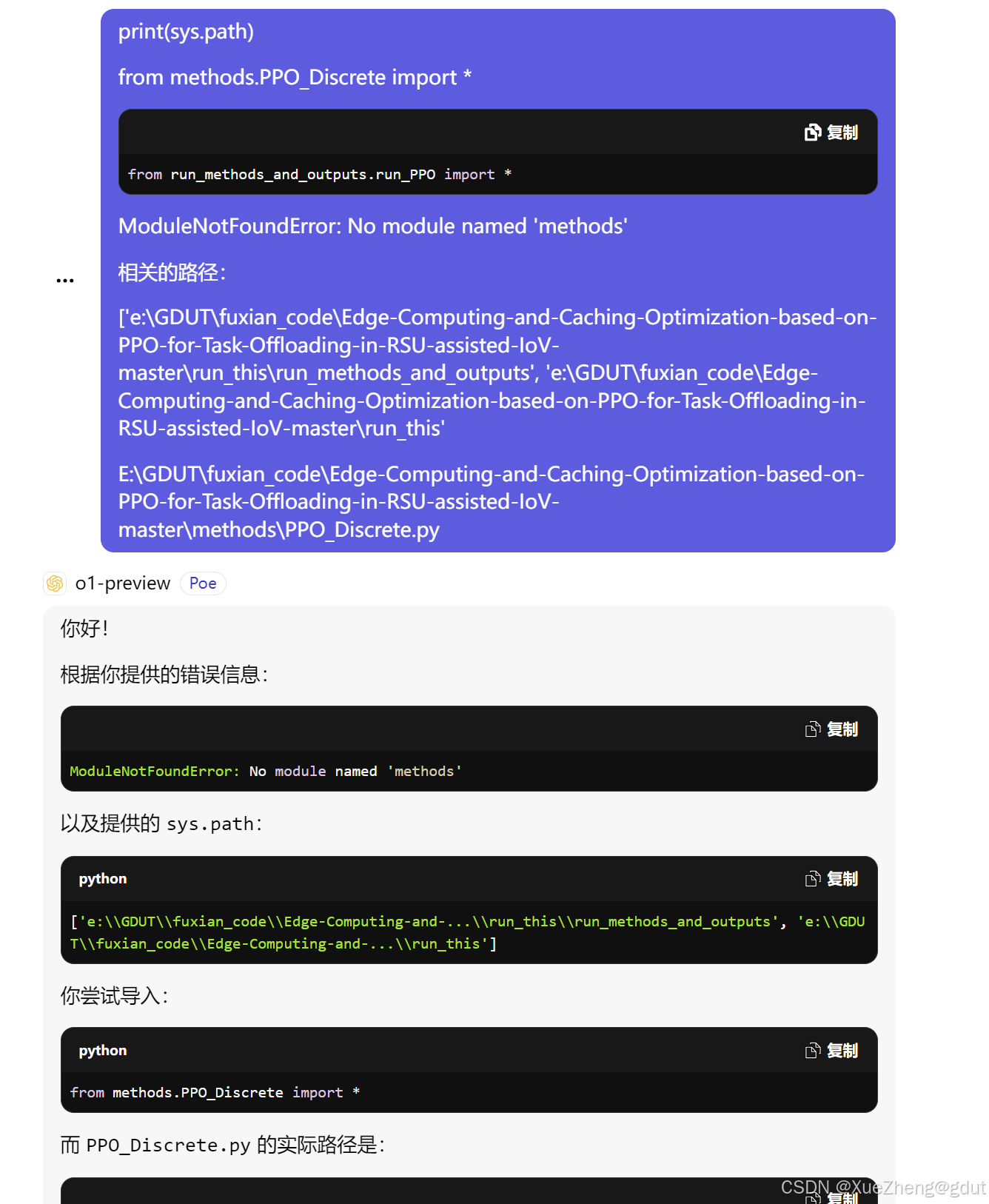
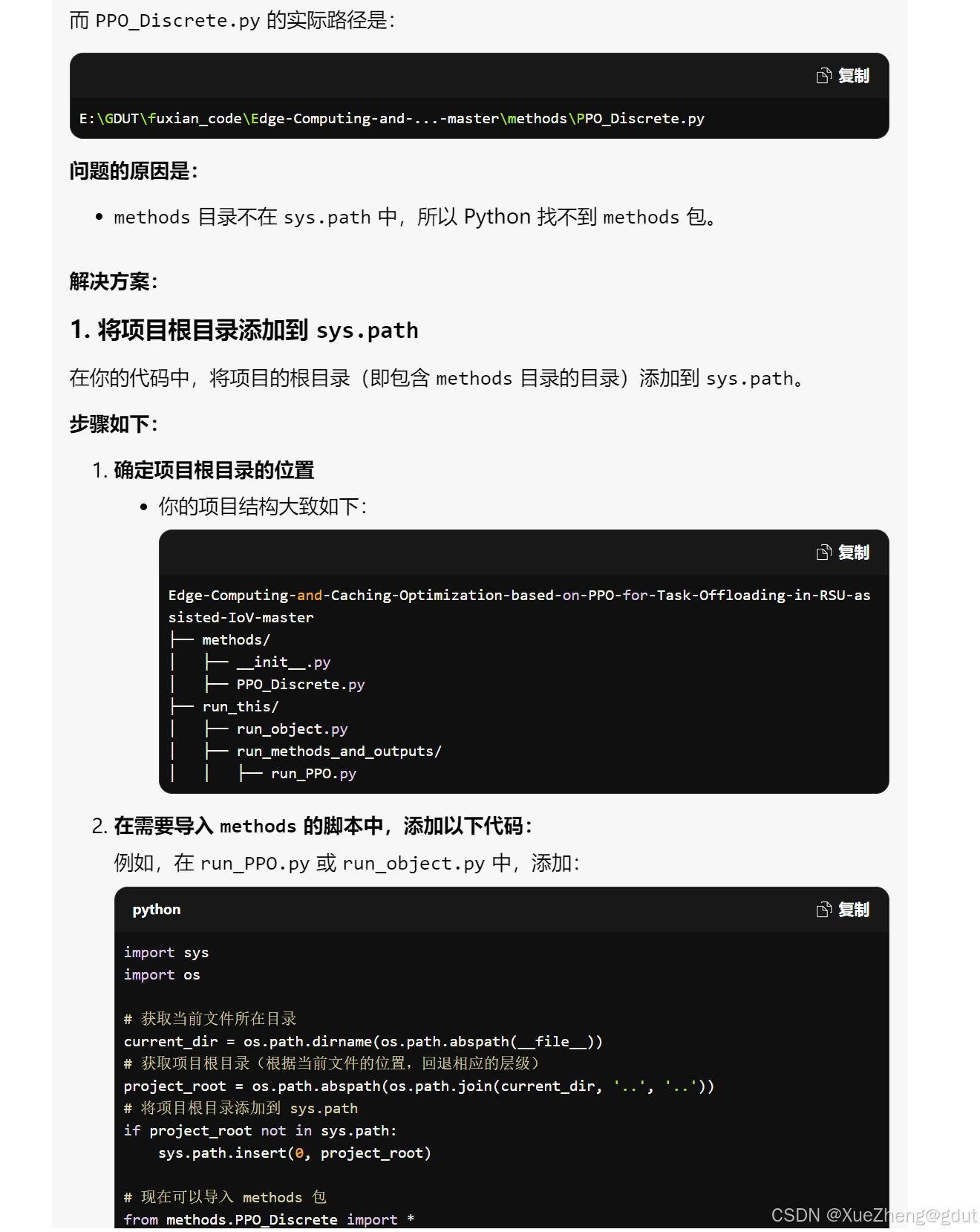



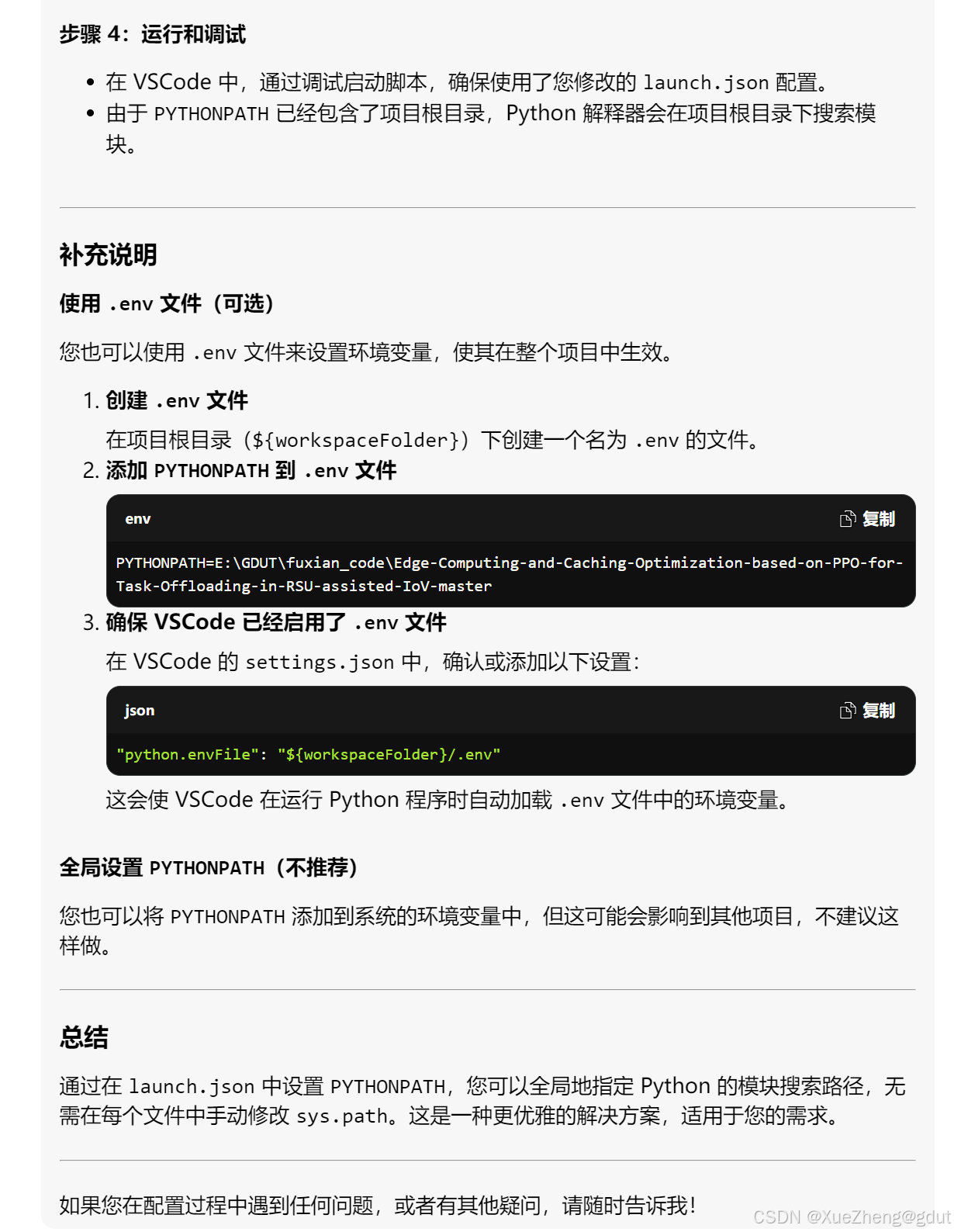
- 我觉得不够优雅,再次提问:


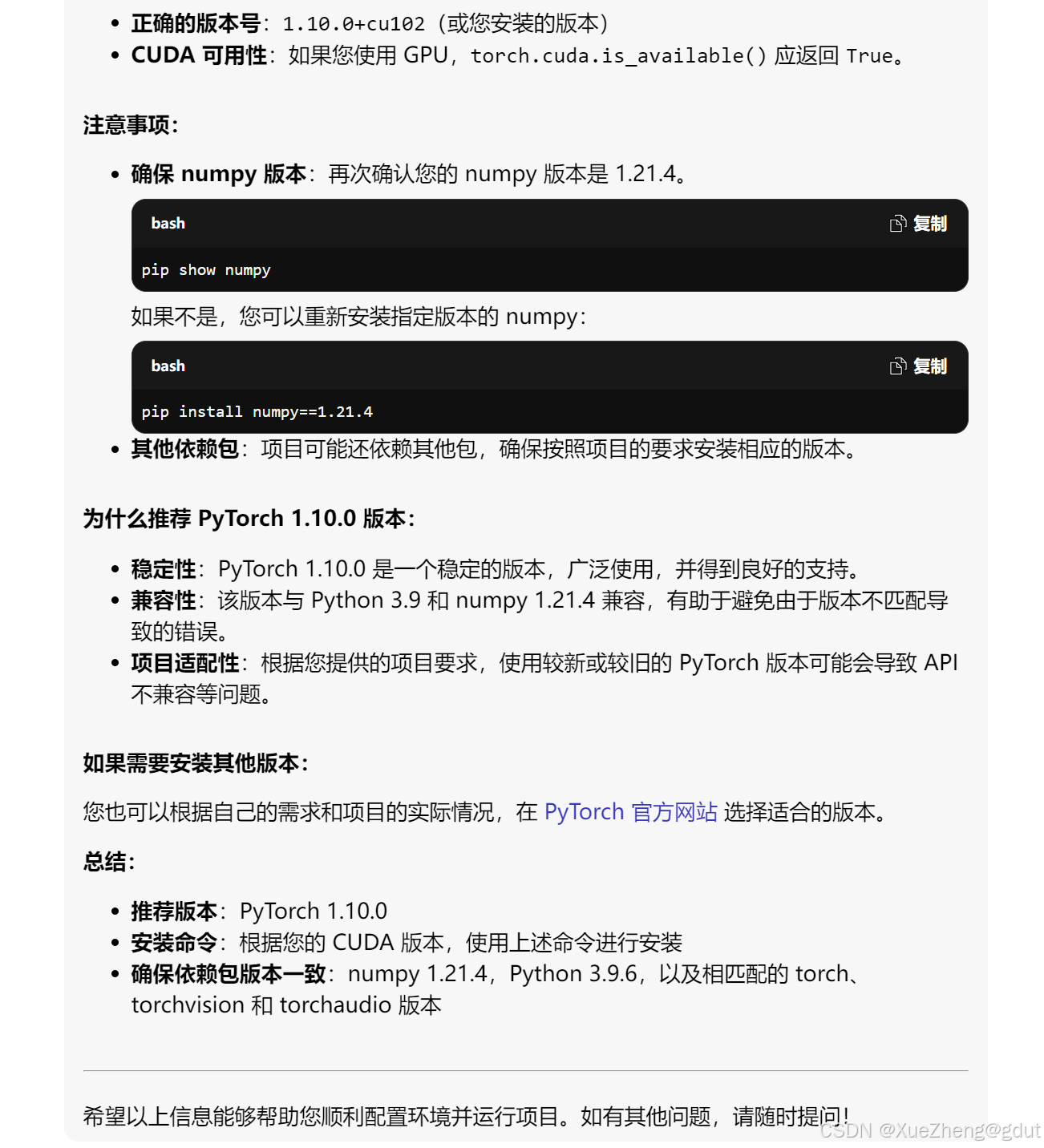
推荐依赖包的版本
- 由于其他包的版本不清楚,直接让gpt推荐了


- 告诉你分为cpu和gpu版本,
-
- 下载仍然出错,继续发问:
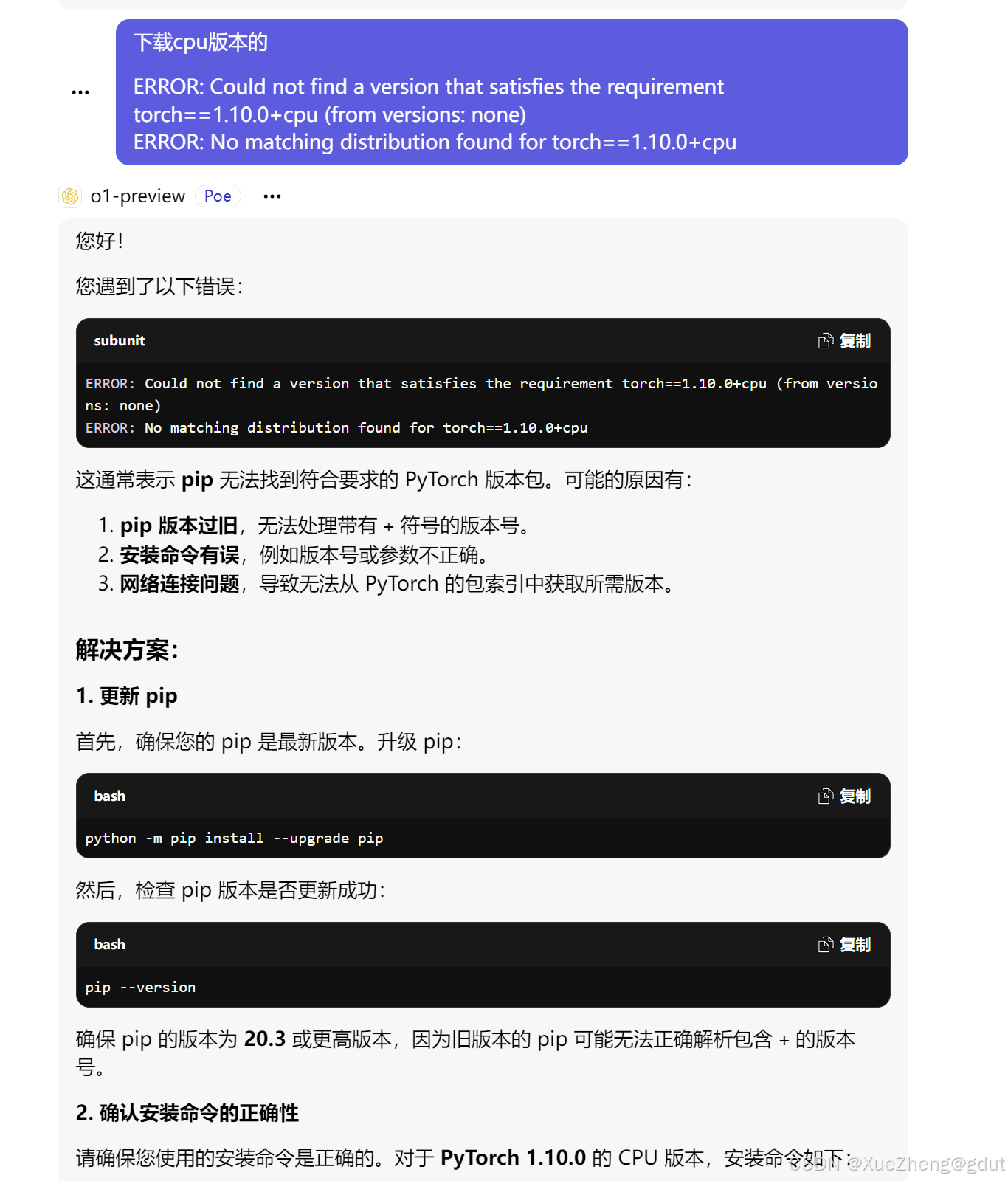

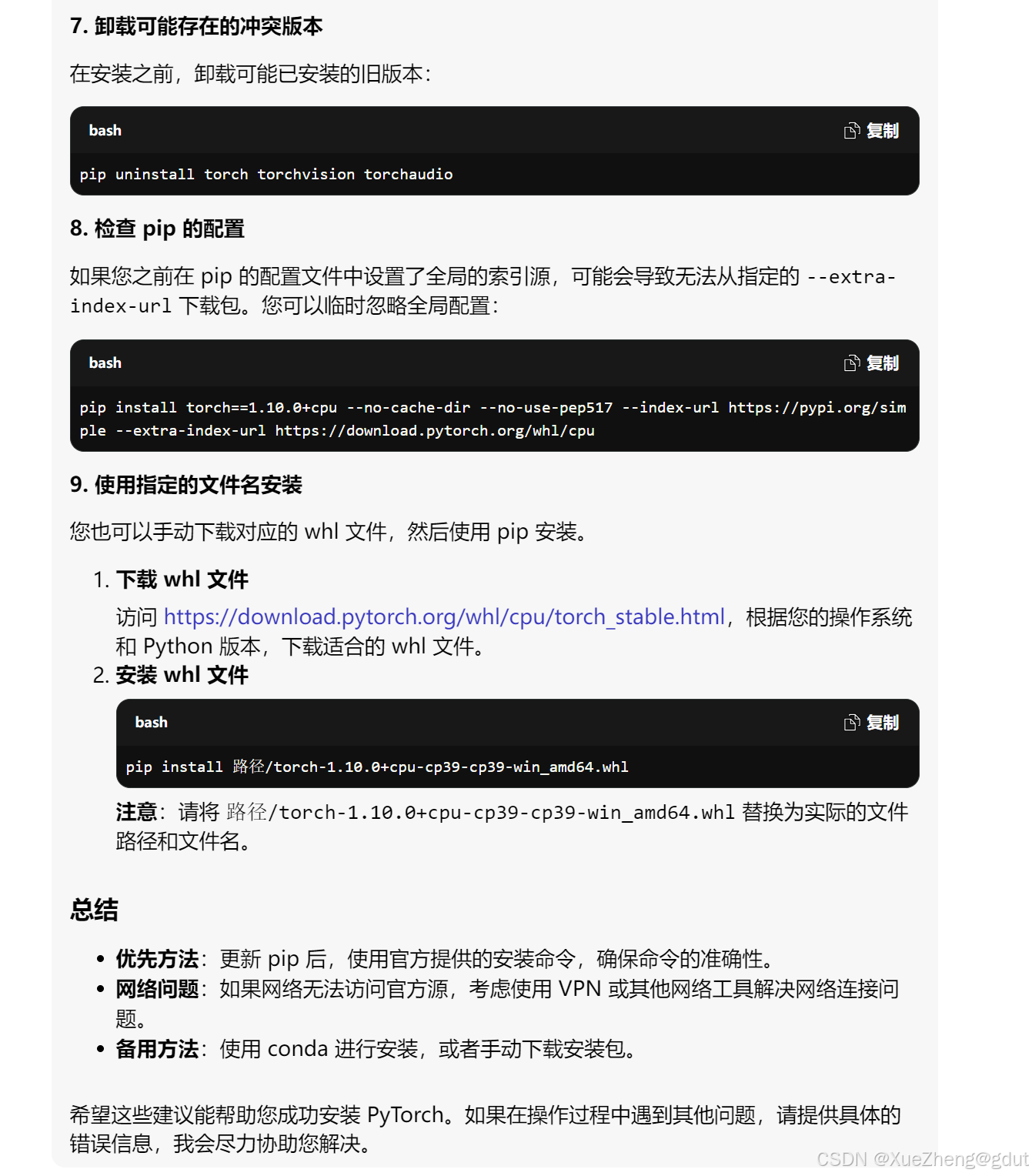
- 继续让其推荐gym的版本:

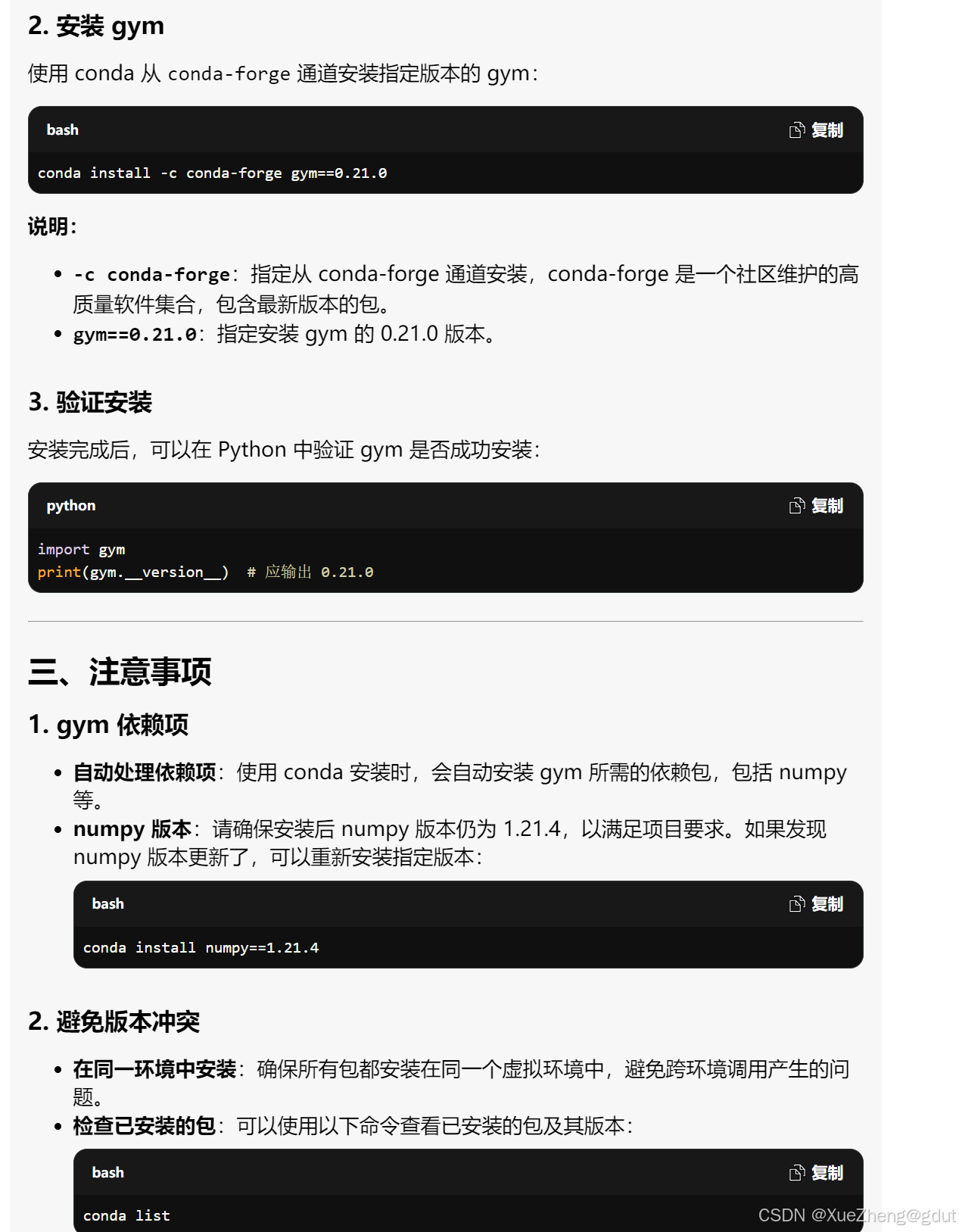

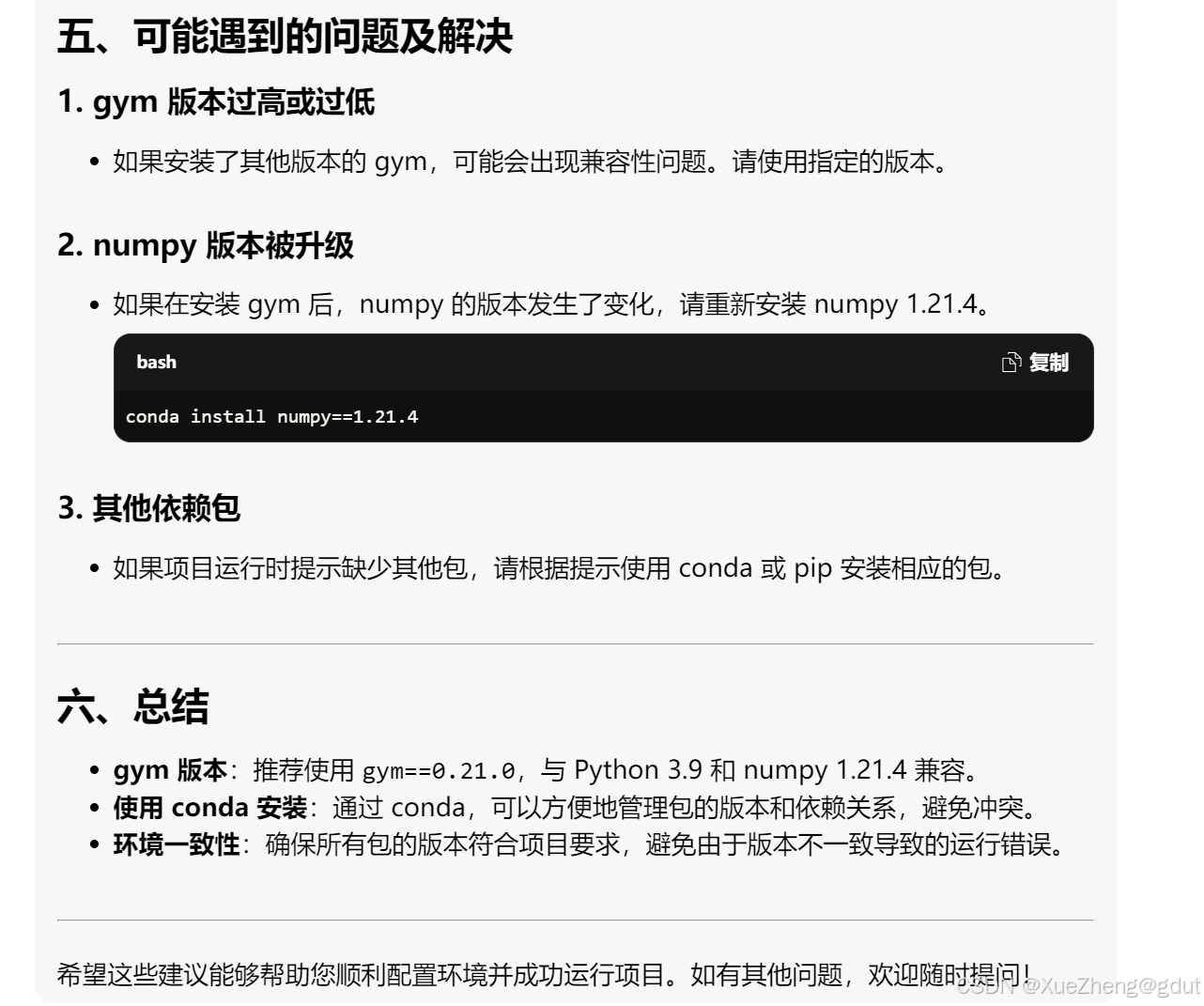
- 报错,继续发问

- 路径问题是遇到的最多的,直接问:

run_object.py完整运行
原本的代码:
from run_this.run_methods_and_outputs.run_PPO import *
from utils import *
reward, ma_hit_rate, time, ma_all_hit_rate, args = run_ppo();
# 保存reward曲线
with open("./data/reward.txt", "a") as file:
file.write(str(reward) + "\n")
# 保存hitrate曲线
with open("./data/hitrate.txt", "a") as file:
file.write(str(ma_hit_rate) + "\n")
# 保存time曲线
with open("./data/time.txt", "a") as file:
file.write(str(time) + "\n")
# 保存all hit ratio曲线
with open("./data/all_hitrate.txt", "a") as file:
file.write(str(ma_all_hit_rate) + "\n")
plot_rewards(reward, args, tag="train") # 画出结果
plot_hit_rate(ma_hit_rate, args, tag="train")
plot_time(time, args, tag="train")
plot_all_hit_rate(ma_all_hit_rate, args, tag="train")
他的这个路径我也是无法读取,其次,这个代码跑一次出图,但数据又没有保存,我想保存数据,直接画出上一次跑的结果的功能无法实现,每次想出图就得重跑仿真,所以修改了代码,方便保存数据,需要直接出图就直接读取数据,需要重新仿真的就选择重跑!修改后的代码如下:
import os
import pickle # 用于保存和读取 args
import ast
from run_methods_and_outputs.run_PPO import *
from utils import *
# 定义读取数据的函数
def read_data(file_path):
if os.path.exists(file_path) and os.path.getsize(file_path) > 0: # 确保文件存在且不为空
data = []
with open(file_path, "r") as file:
for line in file:
stripped_line = line.strip()
print(f"Reading line: '{stripped_line}'") # 打印每行内容
if stripped_line: # 确保行不是空的
try:
# 使用 ast.literal_eval 将字符串解析为 Python 列表
parsed_list = ast.literal_eval(stripped_line)
# 检查解析后的内容是否为列表,并且其中的元素都是浮点数或整数
if isinstance(parsed_list, list):
# 将列表中的每个元素转换为浮点数并添加到 data 中
data.extend([float(x) for x in parsed_list])
else:
print(f"Warning: Parsed content is not a list: {parsed_list}")
except (ValueError, SyntaxError):
print(f"Warning: Could not convert line to list: '{stripped_line}'")
print(f"Data read: {data}")
return data if data else None # 如果读取到有效数据则返回,否则返回 None
else:
print(f"File {file_path} does not exist or is empty.")
return None
# 定义读取和保存 args 的函数
def save_args(args, file_path):
with open(file_path, "wb") as f:
pickle.dump(args, f)
def load_args(file_path):
if os.path.exists(file_path):
with open(file_path, "rb") as f:
return pickle.load(f)
return None
# 获取当前脚本所在的目录
base_dir = os.path.dirname(os.path.abspath(__file__))
# 构建 data 目录的绝对路径
data_dir = os.path.join(base_dir, "data")
# 确保 data 目录存在
os.makedirs(data_dir, exist_ok=True)
# 构建文件路径
reward_file_path = os.path.join(data_dir, "reward.txt")
hitrate_file_path = os.path.join(data_dir, "hitrate.txt")
time_file_path = os.path.join(data_dir, "time.txt")
all_hitrate_file_path = os.path.join(data_dir, "all_hitrate.txt")
args_file_path = os.path.join(data_dir, "args.pkl") # 保存 args 的文件路径
def run_or_load_data(force_run=False):
# 读取已有数据
reward = read_data(reward_file_path)
ma_hit_rate = read_data(hitrate_file_path)
time = read_data(time_file_path)
ma_all_hit_rate = read_data(all_hitrate_file_path)
args = load_args(args_file_path) # 尝试读取保存的 args
# 如果文件不存在或强制要求重跑,运行 run_ppo() 生成数据
# 如果文件不存在或强制要求重跑,或者读取的数据无效,运行 run_ppo() 生成数据
if force_run :
print("Running PPO to generate data...")
reward, ma_hit_rate, time, ma_all_hit_rate, args = run_ppo()
# 保存数据
with open(reward_file_path, "w") as file:
file.write(str(reward) + "\n")
with open(hitrate_file_path, "w") as file:
file.write(str(ma_hit_rate) + "\n")
with open(time_file_path, "w") as file:
file.write(str(time) + "\n")
with open(all_hitrate_file_path, "w") as file:
file.write(str(ma_all_hit_rate) + "\n")
# 保存 args
save_args(args, args_file_path)
else:
# 数据已经存在,直接读取
print("Loading saved data...")
# 返回数据
return reward, ma_hit_rate, time, ma_all_hit_rate, args
# 选择是否强制重跑(例如通过用户输入)
force_run = False # 如果你想强制重跑,将其改为 True
# 获取数据(运行或读取)
reward, ma_hit_rate, time, ma_all_hit_rate, args = run_or_load_data(force_run)
# 画出结果
plot_rewards(reward, args, tag="train")
plot_hit_rate(ma_hit_rate, args, tag="train")
plot_time(time, args, tag="train")
plot_all_hit_rate(ma_all_hit_rate, args, tag="train")
其他的run_this中的代码也需要对应的去修改,
# 选择是否强制重跑(例如通过用户输入) force_run = False # 如果你想强制重跑,将其改为 True这句代码去控制是否重跑。
- 出图就是一些训练收敛曲线
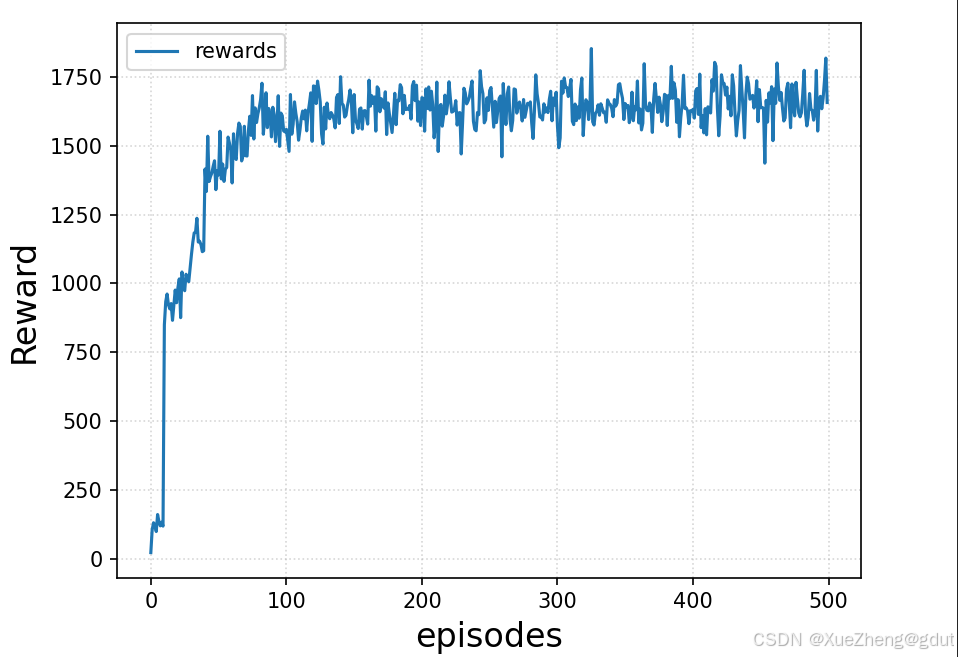
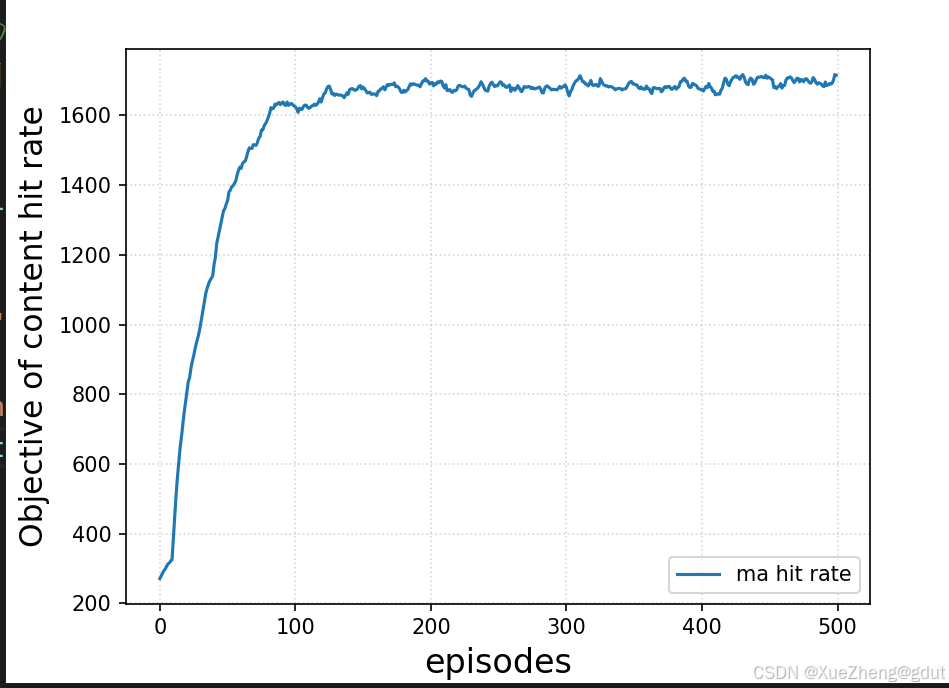
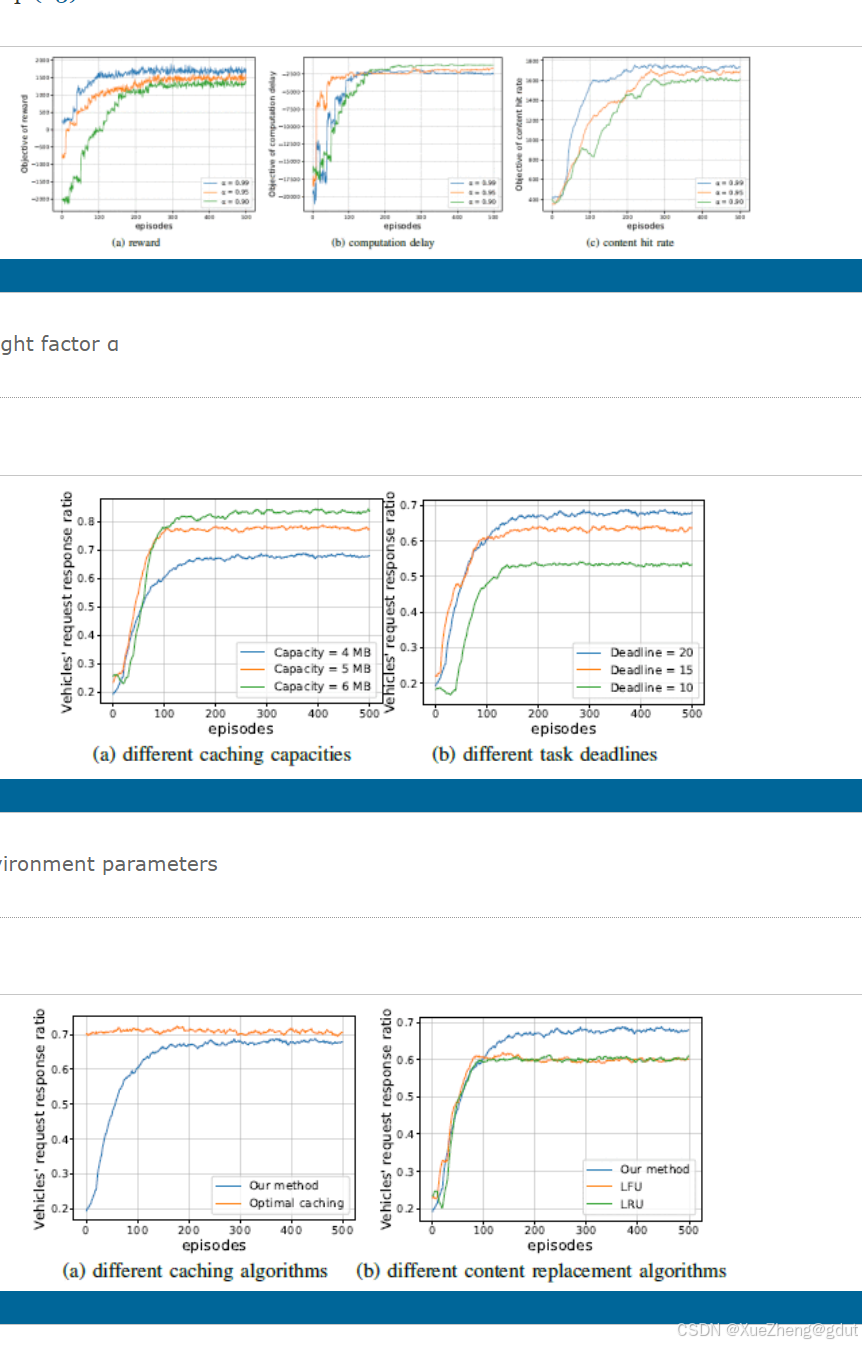
- 原文展示的也就是一些收敛曲线:
总结
AIGC的强大,使得复现论文似乎没有那么困难了,直接帮你匹配问题的答案,想当年,可得去一堆搜索引擎的结果中去翻答案呢,但又不一定是符合自己需求的,别人的环境可能还和自己的不太一样,不清楚这里面可能会有哪些信息差,内容也参差不齐,很可能就会放弃,严重打击自信心,并陷入自我能力怀疑,有没有同感的?总之对小白不太友好,如今AI似乎让小白进步的路线似乎清晰了一些,不再有太多阻隔,祝大家论文复现顺利!

















 1027
1027

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









