







序列模型RNN
对于文本样本及声音信号使用序列模型的原因:
1.文本及声音信号每个训练样本长度不一致,传统的神经网络要求训练样本有固定的输入输出
2.样本特征之间独立,无法建立关联性
RNN
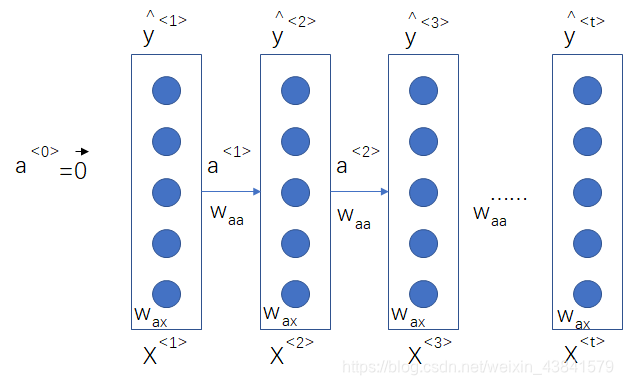
基本RNN网络的输入与输出个数相同,“多对多”的结构,如输入5个单词,预测输出5个结果,在基本RNN网络的基础上根据不同的应用场景,也会有
T
x
!
=
T
y
T_x != T_y
Tx!=Ty,由此延伸出不同的RNN架构。首先,我们还是从基本的RNN网络看起,rnn网络是同时将上个时间步的激活值与当前时间步的x值作为输入,输出
y
^
\hat y
y^和当前时间步隐层的激活值
a
a
a,网络参数传递如下图所示:
a
<
t
>
=
g
1
(
w
a
a
a
<
t
−
1
>
+
w
a
x
X
<
t
>
+
b
a
)
a^{<t>} = g_1(w_{aa}a^{<t-1>}+w_{ax}X^{<t>}+b_a)
a<t>=g1(waaa<t−1>+waxX<t>+ba)
y
^
<
t
>
=
g
2
(
w
a
y
a
<
t
>
+
b
y
)
\hat y^{<t>} = g_2(w_{ay}a^{<t>}+b_y)
y^<t>=g2(waya<t>+by)
向量参数做以下化简
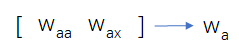
a
<
t
>
=
g
1
(
w
a
[
a
<
t
−
1
>
,
X
<
t
>
]
+
b
a
)
a^{<t>} = g_1(w_{a}[a^{<t-1>},X^{<t>}]+b_a)
a<t>=g1(wa[a<t−1>,X<t>]+ba)
y
^
<
t
>
=
g
2
(
w
y
a
<
t
>
+
b
y
)
\hat y^{<t>} = g_2(w_{y}a^{<t>}+b_y)
y^<t>=g2(wya<t>+by)
这里的前向传播过程与神经网络的前向传播相同,包括隐含层,输出层及激活函数
反向传播计算(backpropagation through timee)
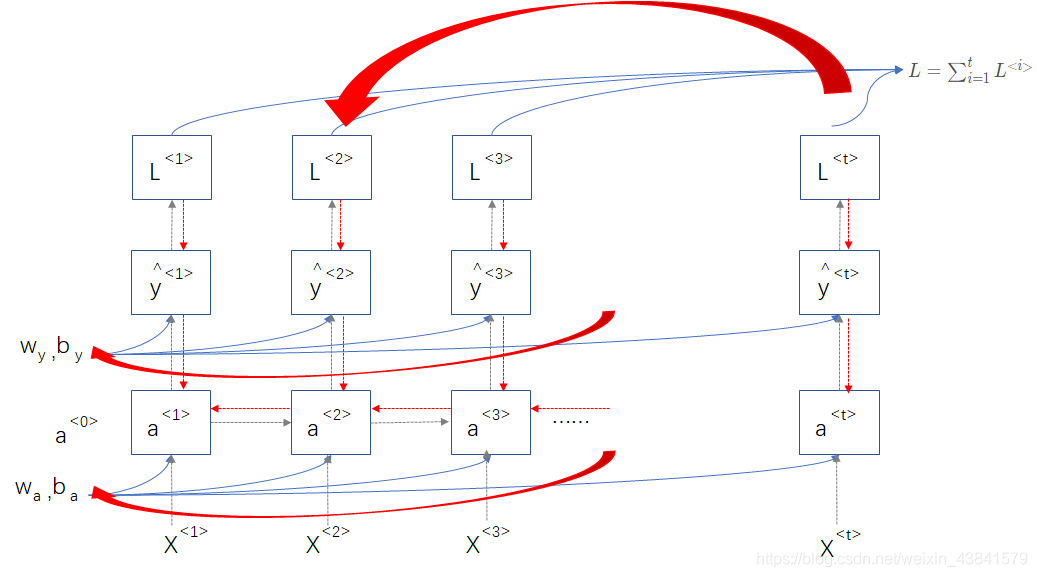
在反向传播过程中,RNN网络的参数矩阵
W
y
,
b
y
,
W
a
,
b
a
W_y,b_y,W_a,b_a
Wy,by,Wa,ba根据上图中损失函数的梯度计算更新
RNN 网络架构
上文内容介绍了传统RNN网络的计算过程,下面将介绍在不同应用场景中的RNN结构变体
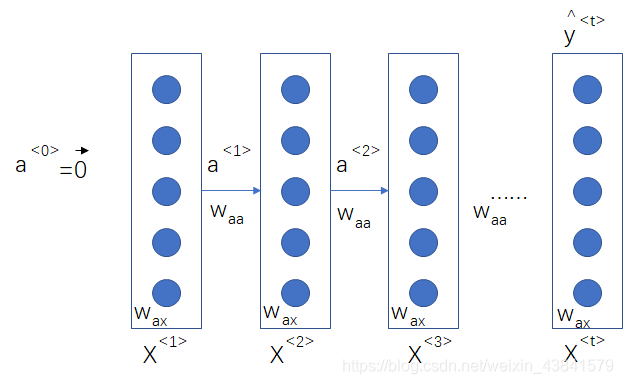
多对一结构(many to one)
在情感分析类场景中,会根据一段评论获取对某事件的星级评分或者是正负面评价,则只需要在最后一个时间步有输出
一对多(one to many)
在音乐合成的场景中,跟据零输入或很少的输入信息,生成一段音乐,就要用到一对多的RNN序列模型
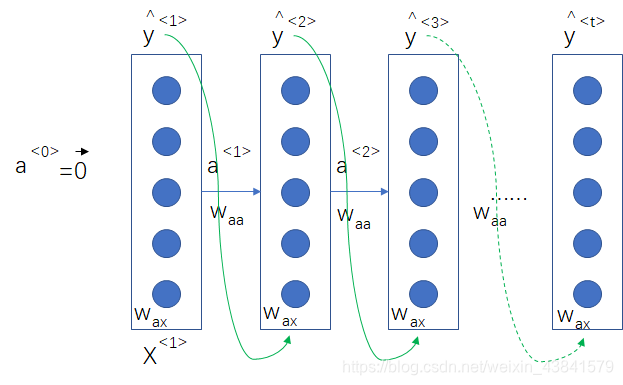
单个输入 X < 1 > X^{<1>} X<1>可以代表想要生成的音乐类型,一般也会把前一时间步的输出作为下一步的输入进行一对多模型的生成
多对多(many to many)
传统的RNN网络也属于多对多的结构,是一种输入与输出个数严格相等的架构,常用于命名实体识别,在一些场景中如机器翻译,输入一种语言,翻译成另一种语言,输入与输出的含义相同,但包含的单词个数一般不同,这也是一种多对多的结构
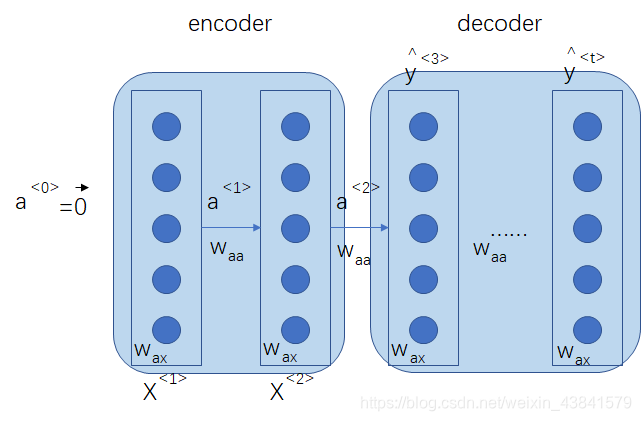
用RNN训练语言模型
语言模型对一段文本的概率进行估计以判断是不是一条自然语言,常用于信息检索、机器翻译、语音识别等任务。
一段文本的概率根据联合概率公式
p
(
w
1
,
w
2
,
w
3
,
.
.
.
,
w
m
)
=
p
(
w
1
)
p
(
w
2
∣
w
1
)
p
(
w
3
∣
w
1
,
w
2
)
.
.
.
p
(
w
m
∣
w
1
,
w
2
,
w
3
,
.
.
.
w
m
−
1
)
p(w_1,w_2,w_3,...,w_m) = p(w_1)p(w_2|w_1)p(w_3|w_1,w_2)...p(w_m|w_1,w_2,w_3,...w_{m-1})
p(w1,w2,w3,...,wm)=p(w1)p(w2∣w1)p(w3∣w1,w2)...p(wm∣w1,w2,w3,...wm−1)
通过最大化
l
o
g
(
p
(
w
1
,
w
2
,
w
3
,
.
.
.
,
w
m
)
)
log(p(w_1,w_2,w_3,...,w_m))
log(p(w1,w2,w3,...,wm))优化网络参数,这里引入log可以将小数的乘积运算转为加法运算,并且单调性不变。
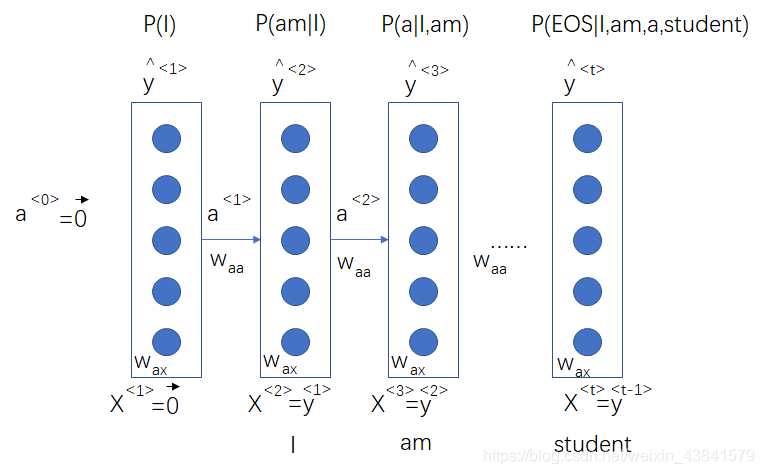
这里介绍一个语言模型训练的例子,输入为
I am a student. <EOS>
首先将文本向量化,就是映射到词库中,用向量表示,然后就是采用RNN训练语言模型了,这里RNN的输入X其实是用y来代替的,因为我们训练的目标就是要使这个句子的概率最大化
语言模型训练之后,也可使用随机采样生成文本序列
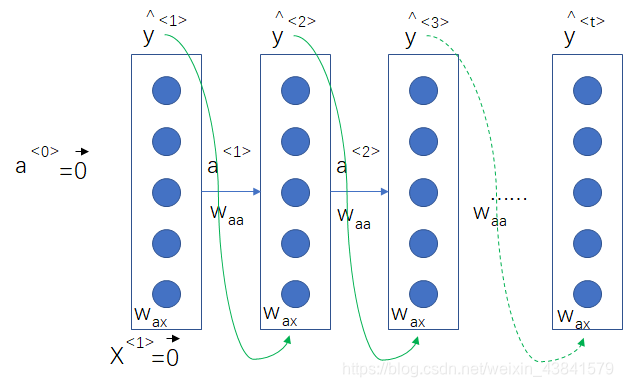
上图中
y
^
<
1
>
\hat y^{<1>}
y^<1>可以是词库中任何一个词的概率,可以通过随机采样一个词作为下一个时间步的输入,得到输出后,继续随机采样,直到生成结束标志。
RNN中的梯度消失问题
在传统的神经网络中,我们知道,随着网络层数的加深,会有梯度消失或者梯度爆炸问题的产生,对于梯度爆炸,我们可以很容易通过参数更新观察到NaN值,然后才取一些方法比如梯度修剪,对计算出来的梯度进行缩减,使得反向传播到输入端层的时候不会产生NaN,而对于梯度消失的问题,我们一般很难观察到,下面一个实例描述了可能产生梯度消失问题的现象。
例如要训练下面语句的语言模型
the cat,which eat …,was full
the cats,which eat…,were full
单词was 与were的选择与最前面的词 cat 或 cats有关,而中间隔着很多的单词,对应到RNN网络中就是指网络后端层的梯度要更新到前端,但是有很多中间层,容易产生梯度消失,这样就没办法正确更新前端层的参数。
GRU(gate recurrent unit)
在基础RNN网络层中,我们的参数计算公式为
a
<
t
>
=
g
1
(
w
a
[
a
<
t
−
1
>
,
X
<
t
>
]
+
b
a
)
a^{<t>} = g_1(w_{a}[a^{<t-1>},X^{<t>}]+b_a)
a<t>=g1(wa[a<t−1>,X<t>]+ba)
y
^
<
t
>
=
g
2
(
w
y
a
<
t
>
+
b
y
)
\hat y^{<t>} = g_2(w_{y}a^{<t>}+b_y)
y^<t>=g2(wya<t>+by)
可用下面图中的单元表示每层参数的计算
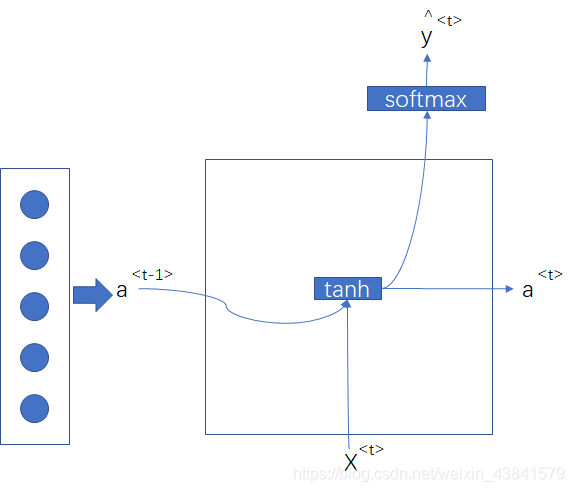
对于前面提到的长期依赖,层数加深导致的梯度消失问题,可以用新增符号细胞隐藏状态
C
C
C-memory cell来解决,原理如下面的公式计算过程:
C
^
<
t
>
=
t
a
n
h
(
w
c
[
C
<
t
−
1
>
,
X
<
t
>
]
+
b
c
)
\hat C^{<t>} = tanh(w_{c}[C^{<t-1>},X^{<t>}]+b_c)
C^<t>=tanh(wc[C<t−1>,X<t>]+bc)
Γ
u
=
s
i
g
m
o
i
d
(
w
u
[
C
<
t
−
1
>
,
X
<
t
>
]
+
b
u
)
\Gamma _u = sigmoid(w_{u}[C^{<t-1>},X^{<t>}]+b_u)
Γu=sigmoid(wu[C<t−1>,X<t>]+bu)
C
<
t
>
=
Γ
u
∗
C
^
<
t
>
+
(
1
−
Γ
u
)
∗
C
<
t
−
1
>
C^{<t>}= \Gamma _u * \hat C^{<t>} + (1-\Gamma _u)* C^{<t-1>}
C<t>=Γu∗C^<t>+(1−Γu)∗C<t−1>
给每个时间步的 C ^ < t > \hat C^{<t>} C^<t>加一个门控信号 Γ u \Gamma _u Γu(u:update)控制是否更新隐藏状态,如果当前时间步的状态对后面有影响则设置 Γ u = 1 \Gamma _u=1 Γu=1,相应的,当前的 C ^ < t > \hat C^{<t>} C^<t>会延续到后面时间步;如果当前时间步的状态对后面没有影响则设置 Γ u = 0 \Gamma _u=0 Γu=0,即当前时间步不对 C < t > C^{<t>} C<t>进行更新, C < t > = C < t − 1 > C^{<t>}=C^{<t-1>} C<t>=C<t−1>
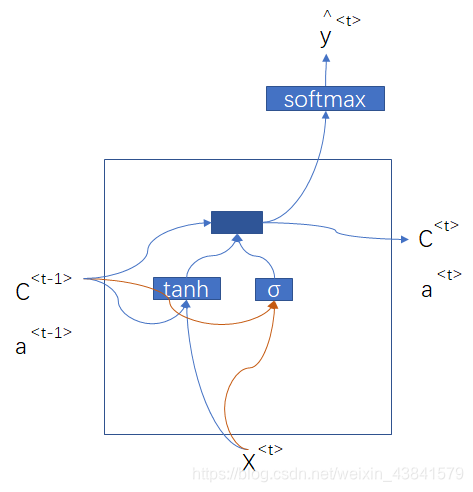
上面的公式版本是一个简化的门控单元版本,在实际应用中,还会考虑
C
<
t
−
1
>
C^{<t-1>}
C<t−1>与
C
^
<
t
>
\hat C^{<t>}
C^<t>的相关性,进而又设置了
Γ
r
\Gamma _r
Γr(r:reset)门控信号,成为现在常用的GRU的标准版本
C
^
<
t
>
=
t
a
n
h
(
w
c
[
Γ
r
∗
C
<
t
−
1
>
,
X
<
t
>
]
+
b
c
)
\hat C^{<t>} = tanh(w_{c}[\Gamma _r*C^{<t-1>},X^{<t>}]+b_c)
C^<t>=tanh(wc[Γr∗C<t−1>,X<t>]+bc)
Γ
u
=
s
i
g
m
o
i
d
(
w
u
[
C
<
t
−
1
>
,
X
<
t
>
]
+
b
u
)
\Gamma _u = sigmoid(w_{u}[C^{<t-1>},X^{<t>}]+b_u)
Γu=sigmoid(wu[C<t−1>,X<t>]+bu)
Γ
r
=
s
i
g
m
o
i
d
(
w
r
[
C
<
t
−
1
>
,
X
<
t
>
]
+
b
r
)
\Gamma _r = sigmoid(w_{r}[C^{<t-1>},X^{<t>}]+b_r)
Γr=sigmoid(wr[C<t−1>,X<t>]+br)
C
<
t
>
=
Γ
u
∗
C
^
<
t
>
+
(
1
−
Γ
u
)
∗
C
<
t
−
1
>
C^{<t>}= \Gamma _u * \hat C^{<t>} + (1-\Gamma _u)* C^{<t-1>}
C<t>=Γu∗C^<t>+(1−Γu)∗C<t−1>
a
<
t
>
=
C
<
t
>
a^{<t>} = C^{<t>}
a<t>=C<t>
LSTM(long short term memory unit)
GRU单元可以解决长期依赖的问题,LSTM则是一个更加强大的版本,不仅考虑前期依赖时间步,而且考虑当前时间步控制隐藏状态的更新,并且控制其输出
C
^
<
t
>
=
t
a
n
h
(
w
c
[
a
<
t
−
1
>
,
X
<
t
>
]
+
b
c
)
\hat C^{<t>} = tanh(w_{c}[a^{<t-1>},X^{<t>}]+b_c)
C^<t>=tanh(wc[a<t−1>,X<t>]+bc)
Γ
u
=
s
i
g
m
o
i
d
(
w
u
[
a
<
t
−
1
>
,
X
<
t
>
]
+
b
u
)
\Gamma _u = sigmoid(w_{u}[a^{<t-1>},X^{<t>}]+b_u)
Γu=sigmoid(wu[a<t−1>,X<t>]+bu)
Γ
f
=
s
i
g
m
o
i
d
(
w
f
[
a
<
t
−
1
>
,
X
<
t
>
]
+
b
f
)
\Gamma _f = sigmoid(w_{f}[a^{<t-1>},X^{<t>}]+b_f)
Γf=sigmoid(wf[a<t−1>,X<t>]+bf)
Γ
o
=
s
i
g
m
o
i
d
(
w
o
[
a
<
t
−
1
>
,
X
<
t
>
]
+
b
o
)
\Gamma _o = sigmoid(w_{o}[a^{<t-1>},X^{<t>}]+b_o)
Γo=sigmoid(wo[a<t−1>,X<t>]+bo)
C
<
t
>
=
Γ
u
∗
C
^
<
t
>
+
Γ
f
∗
C
<
t
−
1
>
C^{<t>}= \Gamma _u * \hat C^{<t>} +\Gamma _f * C^{<t-1>}
C<t>=Γu∗C^<t>+Γf∗C<t−1>
a
<
t
>
=
Γ
o
∗
C
<
t
>
a^{<t>} = \Gamma _o * C^{<t>}
a<t>=Γo∗C<t>
还有另外一个图解版本解释GRU和LSTM,可做参考
在运用上面,两者各有优势,LSTM更加灵活,有三个门;GRU只有两个门,但相应的参数计算也少,比较适合大规模应用。
双向RNN(BRNN)
上面介绍了循环神经网络的计算过程,网络输出值由当前时间步及之前的输入决定,但是在一些场景如命名实体识别中,一些命名实体的判断还依赖于该时间步之后的信息,这就要引入双向RNN
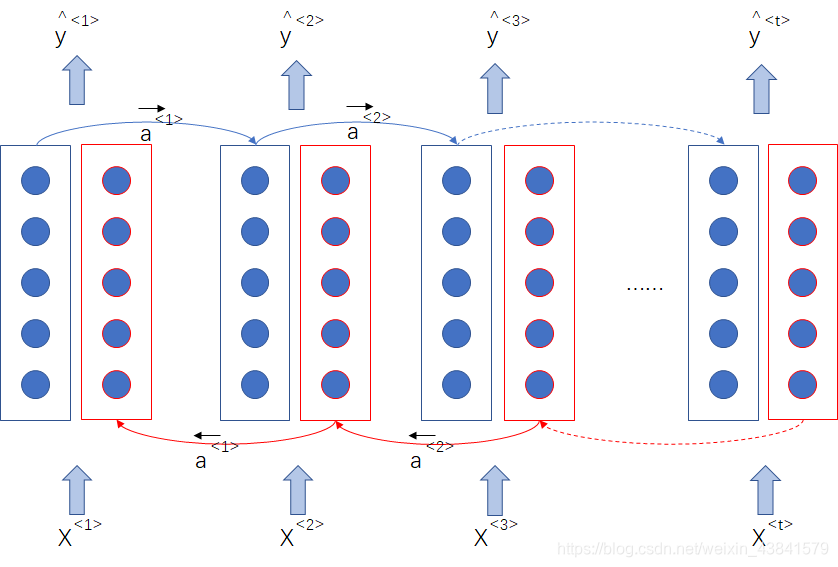
在单向RNN中,每个时间步的输出为:
y
^
<
t
>
=
g
2
(
w
y
a
<
t
>
+
b
y
)
\hat y^{<t>} = g_2(w_{y}a^{<t>}+b_y)
y^<t>=g2(wya<t>+by)
在双向RNN中,每个时间步的输出包含前向和后向:
y
^
<
t
>
=
g
2
(
w
y
[
a
→
<
t
>
,
a
←
<
t
>
]
+
b
y
)
\hat y^{<t>} = g_2(w_{y}[a^\rightarrow{<t>},a^\leftarrow{<t>}]+b_y)
y^<t>=g2(wy[a→<t>,a←<t>]+by)
双向RNN要求一个完整的序列输入,因为每个时间步的输出都包含前向和后向输入的计算
深层RNN网络
深层RNN网络类似于DNN网络的多层,但是一般最多设置3层循环,网络架构如下图所示:
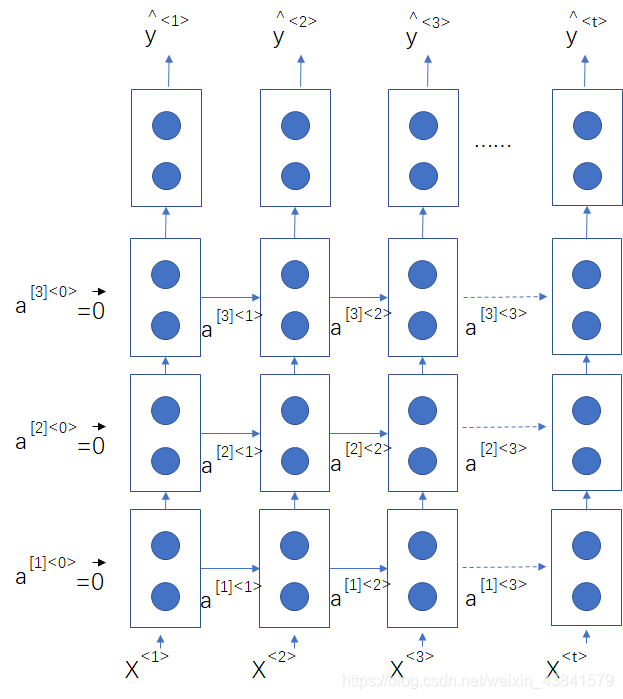
其中
a
[
2
]
<
t
>
=
g
(
w
a
[
a
[
2
]
<
t
−
1
>
,
a
[
1
]
<
t
>
]
+
b
a
)
a^{[2]<t>}=g(w_a[a^{[2]<t-1>},a^{[1]<t>]}+b_a)
a[2]<t>=g(wa[a[2]<t−1>,a[1]<t>]+ba)














 1800
1800











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









