







 本文探讨了在MNIST数据集上实施后门攻击,通过LeNet-5模型训练,并验证了攻击对模型性能的影响,结果显示后门不影响正常任务学习,但攻击成功率接近100%。
本文探讨了在MNIST数据集上实施后门攻击,通过LeNet-5模型训练,并验证了攻击对模型性能的影响,结果显示后门不影响正常任务学习,但攻击成功率接近100%。
加载数据集
# 载入MNIST训练集和测试集
transform = transforms.Compose([
transforms.ToTensor(),
])
train_loader = datasets.MNIST(root='data',
transform=transform,
train=True,
download=True)
test_loader = datasets.MNIST(root='data',
transform=transform,
train=False)
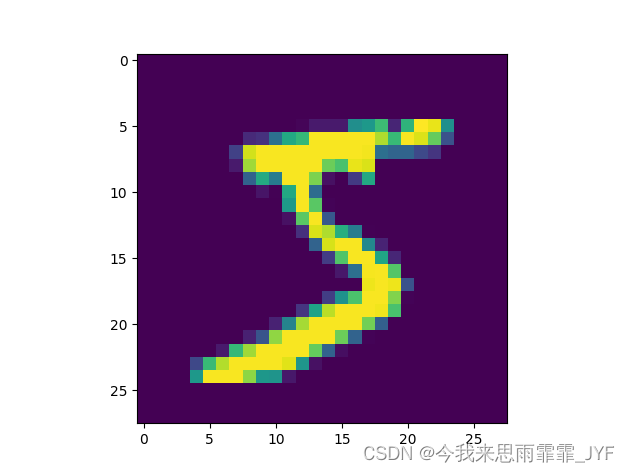
# 可视化样本 大小28×28
plt.imshow(train_loader.data[0].numpy())
plt.show()
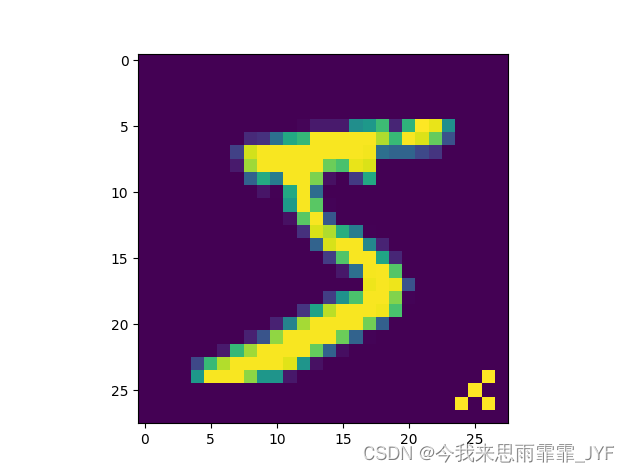
在训练集中植入5000个中毒样本
# 在训练集中植入5000个中毒样本
for i in range(5000):
train_loader.data[i][26][26] = 255
train_loader.data[i][25][25] = 255
train_loader.data[i][24][26] = 255
train_loader.data[i][26][24] = 255
train_loader.targets[i] = 9 # 设置中毒样本的目标标签为9
# 可视化中毒样本
plt.imshow(train_loader.data[0].numpy())
plt.show()
训练模型
data_loader_train = torch.utils.data.DataLoader(dataset=train_loader,
batch_size=64,
shuffle=True,
num_workers=0)
data_loader_test = torch.utils.data.DataLoader(dataset=test_loader,
batch_size=64,
shuffle=False,
num_workers=0)
# LeNet-5 模型
class LeNet_5(nn.Module):
def __init__(self):
super(LeNet_5, self).__init__()
self.conv1 = nn.Conv2d(1, 6, 5, 1)
self.conv2 = nn.Conv2d(6, 16, 5, 1)
self.fc1 = nn.Linear(16 * 4 * 4, 120)
self.fc2 = nn.Linear(120, 84)
self.fc3 = nn.Linear(84, 10)
def forward(self, x):
x = F.max_pool2d(self.conv1(x), 2, 2)
x = F.max_pool2d(self.conv2(x), 2, 2)
x = x.view(-1, 16 * 4 * 4)
x = self.fc1(x)
x = self.fc2(x)
x = self.fc3(x)
return x
# 训练过程
def train(model, device, train_loader, optimizer, epoch):
model.train()
for idx, (data, target) in enumerate(train_loader):
data, target = data.to(device), target.to(device)
pred = model(data)
loss = F.cross_entropy(pred, target)
optimizer.zero_grad()
loss.backward()
optimizer.step()
if idx % 100 == 0:
print("Train Epoch: {}, iterantion: {}, Loss: {}".format(epoch, idx, loss.item()))
torch.save(model.state_dict(), 'badnets.pth')
# 测试过程
def test(model, device, test_loader):
model.load_state_dict(torch.load('badnets.pth'))
model.eval()
total_loss = 0
correct = 0
with torch.no_grad():
for idx, (data, target) in enumerate(test_loader):
data, target = data.to(device), target.to(device)
output = model(data)
total_loss += F.cross_entropy(output, target, reduction="sum").item()
pred = output.argmax(dim=1)
correct += pred.eq(target.view_as(pred)).sum().item()
total_loss /= len(test_loader.dataset)
acc = correct / len(test_loader.dataset) * 100
print("Test Loss: {}, Accuracy: {}".format(total_loss, acc))
def main():
# 超参数
num_epochs = 10
lr = 0.01
momentum = 0.5
model = LeNet_5().to(device)
optimizer = torch.optim.SGD(model.parameters(),
lr=lr,
momentum=momentum)
# 在干净训练集上训练,在干净测试集上测试
# acc=98.29%
# 在带后门数据训练集上训练,在干净测试集上测试
# acc=98.07%
# 说明后门数据并没有破坏正常任务的学习
for epoch in range(num_epochs):
train(model, device, data_loader_train, optimizer, epoch)
test(model, device, data_loader_test)
continue
if __name__=='__main__':
main()
测试攻击成功率
# 攻击成功率 99.66% 对测试集中所有图像都注入后门
for i in range(len(test_loader)):
test_loader.data[i][26][26] = 255
test_loader.data[i][25][25] = 255
test_loader.data[i][24][26] = 255
test_loader.data[i][26][24] = 255
test_loader.targets[i] = 9
data_loader_test2 = torch.utils.data.DataLoader(dataset=test_loader,
batch_size=64,
shuffle=False,
num_workers=0)
test(model, device, data_loader_test2)
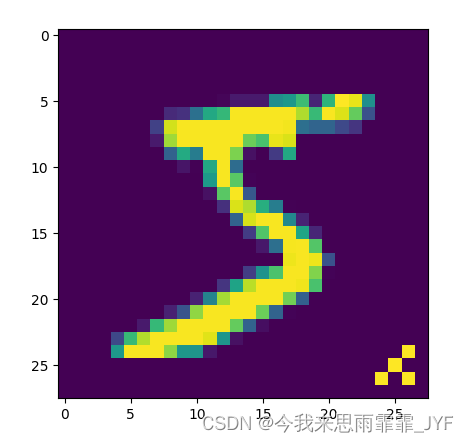
plt.imshow(test_loader.data[0].numpy())
plt.show()
可视化中毒样本,成功被预测为特定目标类别“9”,证明攻击成功。

完整代码
from packaging import packaging
from torchvision.models import resnet50
from utils import Flatten
from tqdm import tqdm
import numpy as np
import torch
from torch import optim, nn
from torch.utils.data import DataLoader
import torch.nn.functional as F
import matplotlib.pyplot as plt
from torchvision import datasets, transforms
use_cuda = True
device = torch.device("cuda" if (use_cuda and torch.cuda.is_available()) else "cpu")
# 载入MNIST训练集和测试集
transform = transforms.Compose([
transforms.ToTensor(),
])
train_loader = datasets.MNIST(root='data',
transform=transform,
train=True,
download=True)
test_loader = datasets.MNIST(root='data',
transform=transform,
train=False)
# 可视化样本 大小28×28
# plt.imshow(train_loader.data[0].numpy())
# plt.show()
# 训练集样本数据
print(len(train_loader))
# 在训练集中植入5000个中毒样本
''' '''
for i in range(5000):
train_loader.data[i][26][26] = 255
train_loader.data[i][25][25] = 255
train_loader.data[i][24][26] = 255
train_loader.data[i][26][24] = 255
train_loader.targets[i] = 9 # 设置中毒样本的目标标签为9
# 可视化中毒样本
plt.imshow(train_loader.data[0].numpy())
plt.show()
data_loader_train = torch.utils.data.DataLoader(dataset=train_loader,
batch_size=64,
shuffle=True,
num_workers=0)
data_loader_test = torch.utils.data.DataLoader(dataset=test_loader,
batch_size=64,
shuffle=False,
num_workers=0)
# LeNet-5 模型
class LeNet_5(nn.Module):
def __init__(self):
super(LeNet_5, self).__init__()
self.conv1 = nn.Conv2d(1, 6, 5, 1)
self.conv2 = nn.Conv2d(6, 16, 5, 1)
self.fc1 = nn.Linear(16 * 4 * 4, 120)
self.fc2 = nn.Linear(120, 84)
self.fc3 = nn.Linear(84, 10)
def forward(self, x):
x = F.max_pool2d(self.conv1(x), 2, 2)
x = F.max_pool2d(self.conv2(x), 2, 2)
x = x.view(-1, 16 * 4 * 4)
x = self.fc1(x)
x = self.fc2(x)
x = self.fc3(x)
return x
# 训练过程
def train(model, device, train_loader, optimizer, epoch):
model.train()
for idx, (data, target) in enumerate(train_loader):
data, target = data.to(device), target.to(device)
pred = model(data)
loss = F.cross_entropy(pred, target)
optimizer.zero_grad()
loss.backward()
optimizer.step()
if idx % 100 == 0:
print("Train Epoch: {}, iterantion: {}, Loss: {}".format(epoch, idx, loss.item()))
torch.save(model.state_dict(), 'badnets.pth')
# 测试过程
def test(model, device, test_loader):
model.load_state_dict(torch.load('badnets.pth'))
model.eval()
total_loss = 0
correct = 0
with torch.no_grad():
for idx, (data, target) in enumerate(test_loader):
data, target = data.to(device), target.to(device)
output = model(data)
total_loss += F.cross_entropy(output, target, reduction="sum").item()
pred = output.argmax(dim=1)
correct += pred.eq(target.view_as(pred)).sum().item()
total_loss /= len(test_loader.dataset)
acc = correct / len(test_loader.dataset) * 100
print("Test Loss: {}, Accuracy: {}".format(total_loss, acc))
def main():
# 超参数
num_epochs = 10
lr = 0.01
momentum = 0.5
model = LeNet_5().to(device)
optimizer = torch.optim.SGD(model.parameters(),
lr=lr,
momentum=momentum)
# 在干净训练集上训练,在干净测试集上测试
# acc=98.29%
# 在带后门数据训练集上训练,在干净测试集上测试
# acc=98.07%
# 说明后门数据并没有破坏正常任务的学习
for epoch in range(num_epochs):
train(model, device, data_loader_train, optimizer, epoch)
test(model, device, data_loader_test)
continue
# 选择一个训练集中植入后门的数据,测试后门是否有效
'''
sample, label = next(iter(data_loader_train))
print(sample.size()) # [64, 1, 28, 28]
print(label[0])
# 可视化
plt.imshow(sample[0][0])
plt.show()
model.load_state_dict(torch.load('badnets.pth'))
model.eval()
sample = sample.to(device)
output = model(sample)
print(output[0])
pred = output.argmax(dim=1)
print(pred[0])
'''
# 攻击成功率 99.66%
for i in range(len(test_loader)):
test_loader.data[i][26][26] = 255
test_loader.data[i][25][25] = 255
test_loader.data[i][24][26] = 255
test_loader.data[i][26][24] = 255
test_loader.targets[i] = 9
data_loader_test2 = torch.utils.data.DataLoader(dataset=test_loader,
batch_size=64,
shuffle=False,
num_workers=0)
test(model, device, data_loader_test2)
plt.imshow(test_loader.data[0].numpy())
plt.show()
if __name__=='__main__':
main()

















 391
391

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









