










写这篇文章的目的是为了总结我之前看的标定,相机模型以及单目测距的内容,如果有错误,还请不吝赐教。
参考链接:
相机模型、相机标定及基于yolov5的单目测距实现
深度学习目标检测目标追踪单目测距
单目测距+代码部署(目标检测+车辆/行人等测距)
单镜头视觉系统检测车辆的测距方法
相机模型与视觉测距不完全指南
单目测距(yolo目标检测+标定+测距代码)
【markdown】 数学公式
老规矩先上参考链接!感谢大佬们的无私奉献!!
代码链接
对代码的部分说明:
1.能跑通最新版本的yolov5就肯定能跑通我的这份代码,就是参考最新代码修改的。
2.权重和数据我就直接放仓库里了,clone下来直接跑,在inference/output里看结果。
3.觉得有用欢迎fork and star!
文章目录
1 前言
在摄像头成像过程中,物体反射的光线通过摄像头的凸透镜打在成像器件上,形成一张图片。这是一个三维物体转换为二维图像的过程。在这个过程中,丢失了物体的深度信息,所以单目摄像头很难测距。但是,我们可以通过一个强假设,来简单计算物体的距离,即假设物体是处于地面上。具体意思下面再详细说。
2 相机模型及单目测距原理
相机模型可以简单看成一个凸透镜成像的模型。下图中,XcYcZc是相机坐标系,其原点为光心O,是相机凸透镜的中心点。x-o1-y坐标系是图像坐标系。
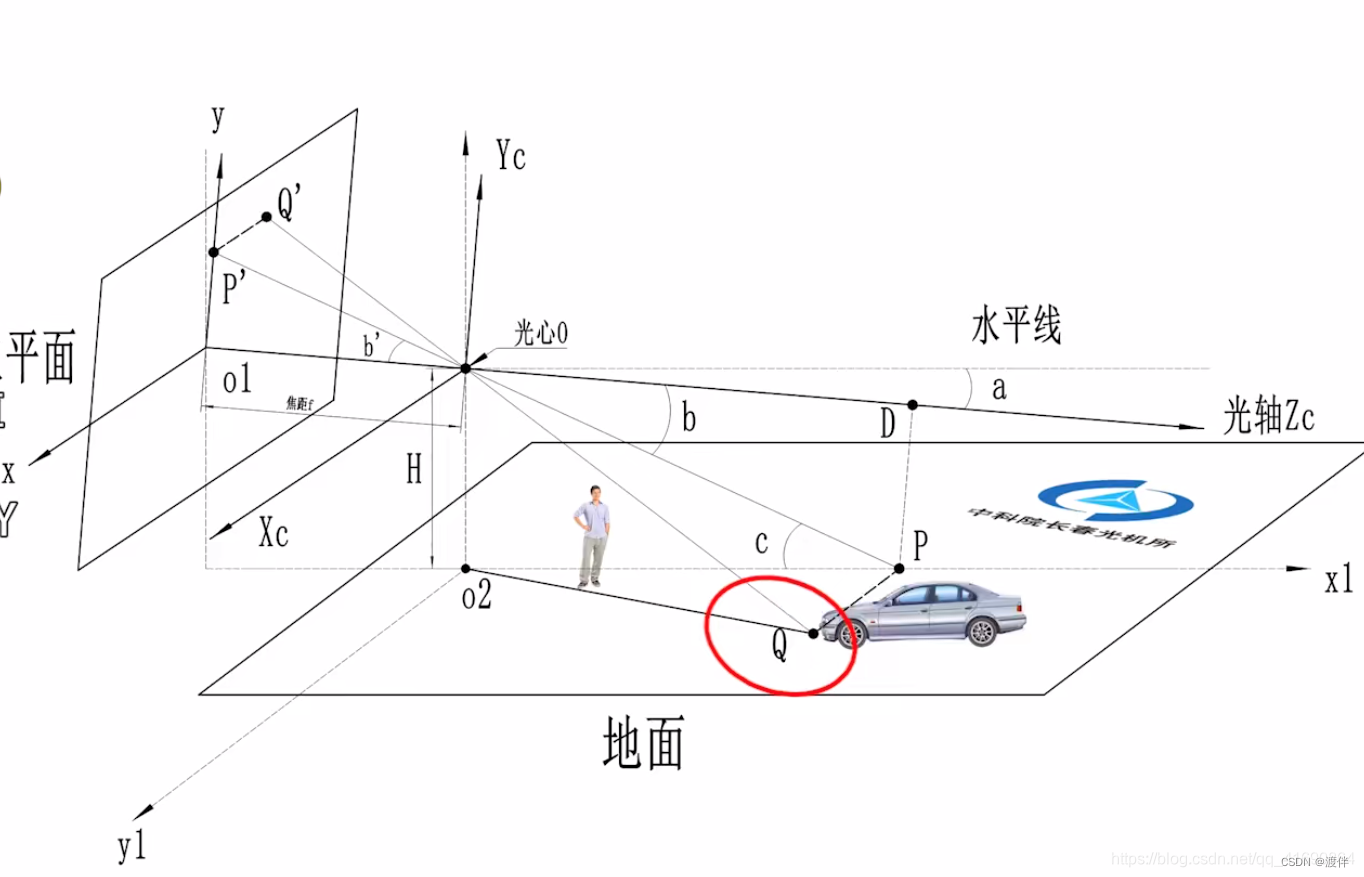
图片从b站up主(uid:109364003)的视频中截图的
图中有一个车辆,且车辆在地面上,其接地点Q必定在地面上。那么Q点的深度便可以求解出来。具体求解步骤懒得打公式了,就截图了。在单目测距过程中,实际物体上的Q点在成像的图片上对应Q’点,Q’点距离o1点沿y轴的距离为o1p’。这个距离o1p’除以y轴像素焦距fy (单位为pixel) ,再求arctan即可得到角度b’。然后按图中步骤很容易理解了。

在按图中步骤求解深度OD时,如果相机高度H、相机光轴与水平线的夹角a没有准确测量的话,会对测距精准度造成较大影响。所以用于自动驾驶时,随着车身抖动,测距精度会很低。如果路面不是水平的,而是具有曲率的,那该方法也将失效。
这部分我还是想加点内容进来。解答了我的疑惑。
2.1 单目测距能精确测距么?
那么有一个问题,在已知所有相机参数K, R, T 的情况下,能否通过图像坐标 p 反推出对应的世界坐标 P 呢?
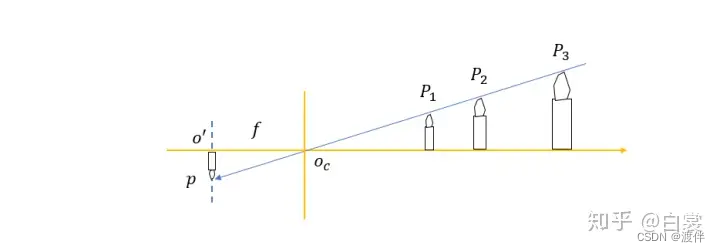
这里我们从几何关系上看:只要世界中的点 P 在
o
c
P
1
→
\overrightarrow{o_{c}P_{1}}
ocP1 射线上,那么最终都会通过相机投影到图像中 p 的点,所以单摄像头无法精确测距。相机模型本质是一种从世界坐标系3D
→
\rightarrow
→像素坐标系2D的投影变换,在投影变换中丢失了深度信息。
大佬这段写的特别好!
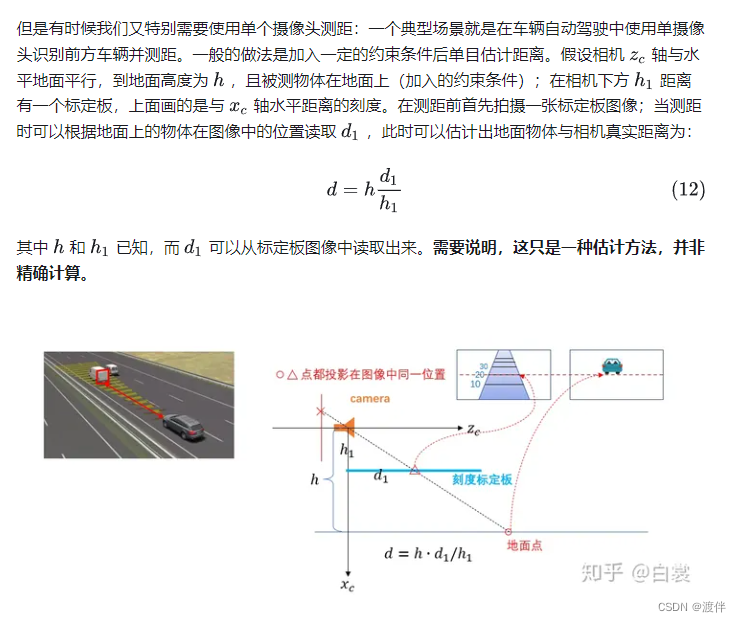
2.2 测距非常重要的几个公式和原理
2.2.1 相机成像模型
想要得到距离信息需要获得三维真实世界里的点,而由于处理的对像是摄像 头捕捉后的二维平面图像,因此如何将二维图像上的某个点转换为三维世界里的 点是值得考虑的问题。进一步的,把图像上的点转换到真实世界的点,就需要进行 像素坐标系、图像坐标系、相机坐标系以及世界坐标系 之间的相互转换。四种 坐标系之间的相互关系如图所示。坐标系描述如下:
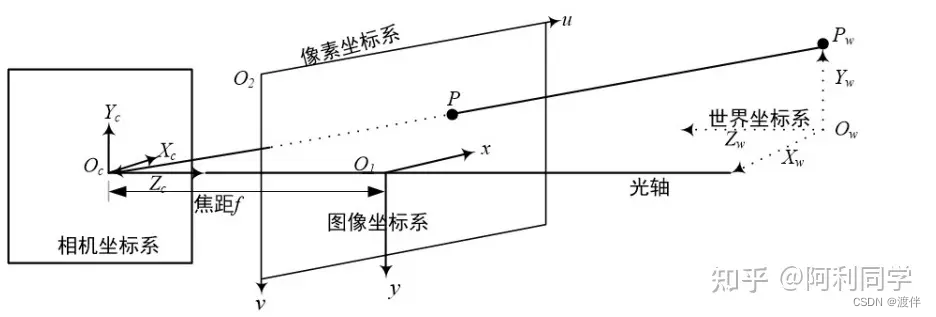
(1)像素坐标系。数字图像一般是三维图像并且由众多像素点组合而成的,像 素坐标系的原点为 O2,以宽度方向为 u 轴,以高度方向为 v 轴。
(2)图像坐标系。图像坐标原点为 O1,并且像素坐标系和图像坐标系是平行的, 以图像宽度方向为 x 轴,以高度方向为 y 轴,长度单位为 mm。
(3)相机坐标系。相机坐标系原点 Oc,Xc轴、Yc 轴分别是与图像坐标系下的 x 轴、y 轴相互平行,相机 Zc轴和摄像头光轴重合。
(4)世界坐标系。我们所处的环境即是在世界坐标系之下,也就是图中 Xw-Yw-Zw 平面。Pw 通过真实世界上的一点至图像上的 P 点,完成从世界坐标到 图像上坐标的转换。
我看了很多遍原理,这部分是真正让我醍醐灌顶的。
2.2.1 坐标系转换
(1)像素坐标系转换到图像坐标系 像素坐标系是以像素来表示各个像素位置信息的,但是它不能够表达出图像 中物体的物理大小,因此需要进行坐标系之间的转换。略
(2)图像坐标系变换到相机坐标系 略
(3)相机坐标系变换到世界坐标系
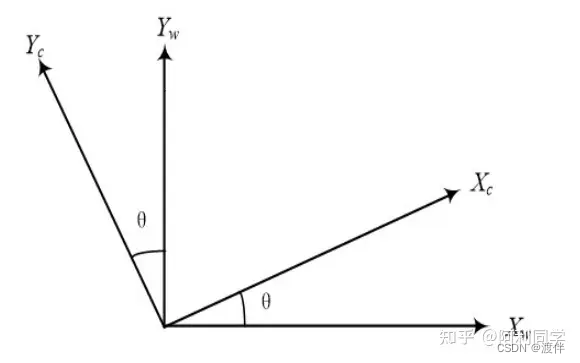
相机坐标系变换到世界坐标系可以描述为一个旋转平移的过程,分别将旋转 和平移的分量加起来就是整个坐标系转换的全过程了。对于旋转过程,假设相机 坐标系的 Z
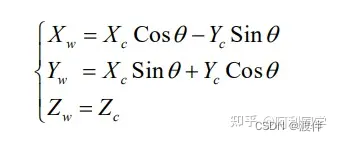
同理,绕 X 轴旋转会得到如下关系
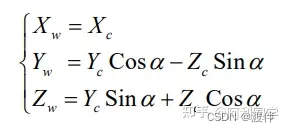
绕 Y 轴旋转会得到如下关系:
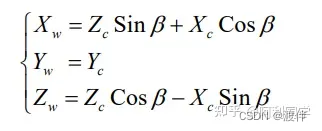
对于平移分量来说,可以表达为:
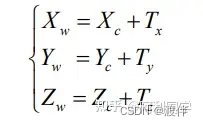
这部分公式很赞!
3 相机内参和外参的标定
这部分优秀文献特别多,等我闲的时候再来加。
4 基于yolov5的单目测距实现及关键代码
estimate_distance.py为主程序。该程序中有一个DistanceEstimation类,该类的主要成员函数有camera_parameters(), object_point_world_position(), distance(), Detect(). 在Detect函数中调用yolov5检测得到目标框后,便可以提取目标框的底边的中点作为2中所述的测距所需的Q’点。然后按照2中所述原理,便可以求得到Q点的Xw和Yw坐标。取Xw和Yw的坐标的平方和,再开根号便得到了目标的直线距离。
4.1 单目测距模型
在完成了相机畸变矫正和相机内外参数的求取之后,建立了如下的单目测距 模型,再结合第四章目标检测获取的矩形框就可以进行距离的求取。
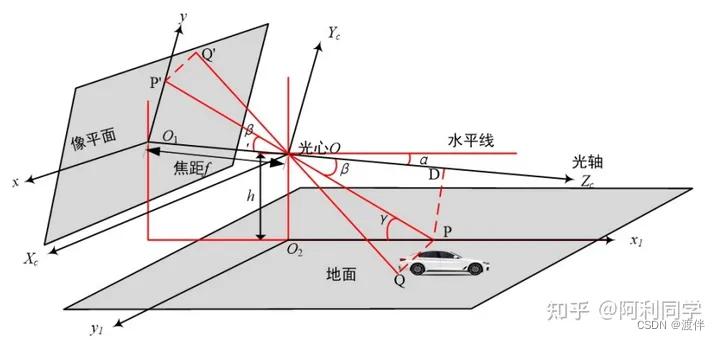
测距模型可以看作是一个凸透镜成像的过程。上图中,Xc-Yc-Zc是相机坐标系, xO1y是图像坐标系,O1O为焦距f,x1O2y1是地面坐标系,OO2为摄像头安装高度h。 图中有一辆车在地面上,那么其接地点Q必定在地面上。在单目测距过程中,实际 物体上的Q点在成像的图片上对应Q'点,Q'点在y轴上的投影为P'点。水平线 与Zc轴的夹角为α,Zc光轴与PP'的夹角为β,直线OP与地面x1轴的夹角为γ。
4.2 目标点的选取
根据目标检测框,并且已知相机内外参数, 将其联合起来就可以得到测距值。具体的本文首先要选取参考点(目标点),拟选取目标框底部中点位置作为参考点,并根据大量目标框的获取结果。观察到目标矩形框比目标物实际尺寸略大,因此采取偏移的方式对目标参考点进行矫正以保证 测距精确度。本文采取让参考点向上偏移d个像素点,并且获取的是目标框的左上角和右下角坐标,因此参考点坐标可以表示为:
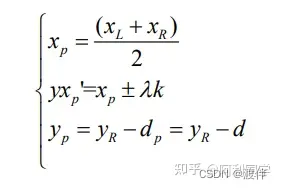
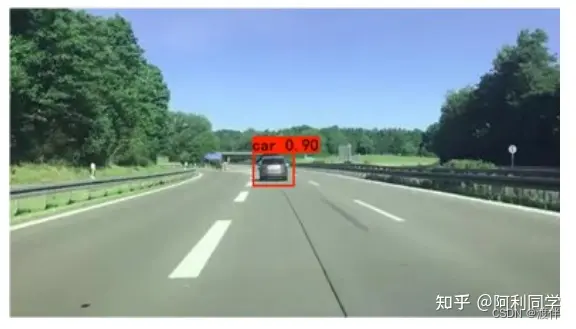
然而上述目标点适合前方物体在本车正前方的场景,当面对上图场景时, 目标物会出现在本车侧方位置。如果再把目标框下部中点作为测距目标点,会出 现目标点严重偏离车辆正下方的问题,存在目标点出现在汽车中心位置左侧或中 心右侧的现象,这会造成测距精度不高的缺点。因此,进一步的对其进行改进, 当目标点(xp,yp)与图像下部中点斜率k满足阈值δ时,就会更新xp'的值,新的xp' 可以表示为:
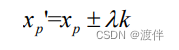
其中λ为偏移权重系数,当k值为负时,λ为负;当k值为正时,λ也为正。

4.3 距离的求取
由上面求得的内参矩阵可得fx,fy。由测距模型可以推得Zc 光轴与PP'的夹角β:
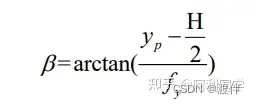
直线OP与地面x1轴的夹角γ可以看作是水平线与PP'的夹角
Z
c
{Z_{c}}
Zc 深度公式可以表示为:
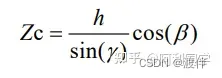
把图像坐标点(xp,yp)转换为相机坐标系上的点可以表示为:
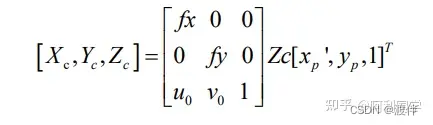

得到最后的距离公式为:
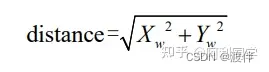
核心代码:
cam_H = 1 # 相机离地的高度
angle_a = 0 # 相机光轴与水平线的夹角a
angle_b = math.atan((v1 - self.H / 2) / fy)
angle_c = angle_b + angle_a
print('angle_b', angle_b)
depth = (cam_H / np.sin(angle_c)) * math.cos(angle_b)#目标深度
print('depth', depth)
k_inv = np.linalg.inv(in_mat)#K^-1 内参矩阵的逆
p_inv = np.linalg.inv(out_mat)#R^-1 外参矩阵的逆
print("out---:",p_inv)
point_c = np.array([x_d, y_d, 1]) ##图像坐标
point_c = np.transpose(point_c)#目标的世界坐标
print('point_c', point_c)
print('in----', k_inv)
##相机坐标系和图像坐标系下物体坐标可按照下式转换。
c_position = np.matmul(k_inv, depth * point_c)#Zc*[u,v,1].T*ins^-1==[Xc,Yc,Zc].T #坐标转换
别人的实验结果和分析:
为了验证方法的合理性,本文将实测距离与仿真结果进行对比验证。因为目 标物的距离不同会造成预测的精度也不同,具体实验流程如下:
(1) 用棋盘网格图对车载摄像头进行标定,将棋盘格图放在摄像头前的不同距 离以及倾斜不同的角度,将采集到的17张图像导入到软件中来求解相机内外参数 以及畸变系数。
(2)采集不同距离下的车、行人等图像,并将出现在图像中的目标物利用卷尺 对其真实距离进行测量。
(3)利用矫正公式将采集到的图像进行矫正,以获得良好的测试位置。
(4)将矫正后的图像数据集输入到目标检测模型和测距模型中进行仿真测距。
这部分 阿利同学 这位作者说自己的结果跟prescan仿真软件相比,结果误差5%。作者认为是可以用的,我并没有去验证这部分的精确性,但我认为作者原理部分写的很好。














 4064
4064











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









