






摘要:基于脉冲的神经形态的硬件承诺去减少图片分类和其他学习应用的能量消耗,尤其在手机和其他边缘设备上。然而,深度脉冲神经网络的直接训练是困难的,并且先前将被训练的人工神经网络转变到脉冲神经网络的方法是无效的因为神经元不得不发出太多脉冲。我们展示了一个大体上更有效转变提升,当以这个为目的优化脉冲神经元模型,以至于它不仅仅与一个神经元发放多少脉冲的信息转变有关也许什么时候它发放这些脉冲有关。这个进步精度能用脉冲神经元来做图像分类能被达到,并且结果网络需要平均每个脉冲神经元仅仅两个脉冲去分类图片。额外的,我们和的心转变方法提升潜在因素和结果脉冲网络的吞吐量。
脉冲神经网络作为最近在边缘设备中现代AI的更广泛使用的障碍被探索尽可能多的解决方案。大的最先进的人工神经网络的能量消耗被深度学习所生产。
最广泛使用在图片分类上的是卷积神经网络,当然也用在其他应用域。这些人工神经网络不得不是足够大的去达到顶级的表现,因为他们需要有一个足够大数量的参数为了从他们训练过的大数据集中去吸引足够的信息。这些大的人工神经网络的标准硬件实现的推论是无力的。
脉冲神经元已经聚焦在用一个彻底地减少能量预算的新奇的计算硬件的AI发展,尤其因为这个大脑的巨大SNN-由大约1000亿个神经元组成-仅仅20w的功率消耗。刻板形象的脉冲也叫做脉冲的脉冲神经元输出训练。因此他们的输出是和持续的一个人工神经网络神经元的生产作为输出是非常不同的。大多数的被考虑在神经元形态上的硬件的实现被大脑中的脉冲神经元的简单模型所激发。然而,这些简单神经元模型不捕获生物神经元的能力去被不同的短暂脉冲模式去编码不同的输入,不仅仅通过他们的发放率。

不同输入值的编码(不同振幅的电流阶跃)在一个生物神经元里的短暂脉冲模式。
而大的人工神经网络,在巨大的数据集上用甚至更复杂的深度学习算法训练,在几个智能分类接近有时候超越人类的表现,基于脉冲的神经形态的硬件的最近几代的表现发展滞后。希望通过循环排重神经网络的例子能使差距缩小,因为那些能被训练去达到循环人工神经网络的大多数表现。
但是生产达到和只有一些脉冲的人工神经网络相似表现的SNNs坚持使用前馈网络。达到真正好的图像分类精度的前馈CNNs往往是非常深和非常大的,并且训练相应的深度和大的前馈脉冲神经网络还没有能够到达相似的分类精度。在结果脉冲神经网络更高水平上的脉冲的时间和发放率的精度问题已经被引用尽可能多的原因。一个吸引人的可替换物失去简单的用一个执行好的被训练的卷积神经网络并且转变它进入一个脉冲神经网络,用相同的连接和权重。最普遍的,到目前为止最好执行的,转换方式是基于速度编码的主意的,一个人工神经网络单元的模拟输出被一个脉冲神经元的发放率所仿真。这个方法是被生成的到目前为止最好的图片分类的脉冲神经元结果。但是一个通过一个发放率的模拟值的转变往往要求一个相当大地脉冲数量,这也减少了潜在因素和网络的吞吐量。此外,作为结果的脉冲神经网络往往生产很多在没有脉冲的硬件上的能源优势丢失的脉冲。最后一个基于速度的人工神经网络转变到脉冲神经网络的转换不能被应用到哪些最近在ImageNet、EfficientNets上达到最高精度的人工神经网络,因为这些用了一个拥有正负值的激活函数:SiLu函数。
我们介绍了一种新的ANN-to-SNN转变我们叫做FS-转变,因为它要求了一个脉冲神经元去引起一些脉冲(FS = Few Spikes)。这个方法与基于速度的转换完全不同,并且开发了用脉冲模式短暂编码的选项,一个脉冲的时间传输了额外的信息。
短暂编码的最早被提出的形式,结果是困难的去有效地在神经形态硬件里去实现因为他们要求在脉冲和顺流的神经元之间去传输好的时差。形成对比的,一个FS-转换能被实现用仅仅log N个不同的脉冲时间的值,并且最多log N个脉冲用来传输在1到N之间。事实上,脉冲的被要求的数量能够被做甚至更低因为不是所有的N个值都发生平等的频繁。然后FS-转换要求一个被修改的脉冲神经元模型,这个FS-神经元有一个内部的动态变化那被优化给用一些脉冲仿真的人工神经网络神经元的特别的种类。我们证明了来自卷积神经网络的FS-转换脉冲神经网络的表现,在两个最先进的图像分类的数据集上:ImageNet2012和CIFAR10。这个被优化的脉冲神经元模型能作为神经元形态硬件的下一代的引导服务。
通过一个拥有一些脉冲的脉冲神经元来模拟一个人工神经网络
从人工神经网络到脉冲神经网络的FS-转换需要标准神经元模型的变异系数,我们把它称之为FS-神经元。在一个人工神经网络里一个一般的人工神经元的计算步骤被一个FS神经元的K次步骤模拟。他的内部动态特性被固定的参数T(t)、h(t)、d(t)for t=1,…,K定义。这些被优化通过一个脉冲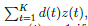
的权重总和,其中z(t)表示这个神经元生成的脉冲序列去模拟被给的人工神经网络神经元激活函数f(x)。更精确的:z(t)=1如果这个神经元在第t步发放,否则z(t)=0.在时间t的时候引出一个脉冲,一个神经元细胞膜电势v(t)不得不超过它的发放阈值电流值T(t)。我们认为细胞膜电势v(t)没有泄露,但是在时间t的脉冲之后被初始化到v(t)-h(t).用公式表达,这个细胞膜电势v(t)开始用值v(1)=x,x是门输入,在K步期间发展进化按照
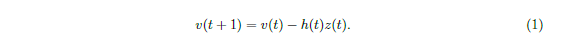
这个一个FS-神经元的门输入x的脉冲输出z(t)能被简洁地紧密地定义
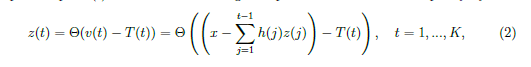
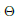 表示阶跃函数。这个来自这些K个时间步骤的FS-神经元的完全的输出f(x),它们会被下一层的FS神经元所收集,能被写作
表示阶跃函数。这个来自这些K个时间步骤的FS-神经元的完全的输出f(x),它们会被下一层的FS神经元所收集,能被写作

一个模型的例证能被发现在Fig.2b中。

图二:一个人工神经网络神经元转变到一个FS神经元
a)一个一般的拥有激活函数f(x)的人工神经网络被模拟。
b)在K个时间步骤里模拟这个人工神经网络的FS神经元。它的输出脉冲训练被z(t)定义。
为了模拟ReLU激活函数,它能选择FS神经元的参数以至于他们定义一个由粗到精的过程策略给所有的输入值x定位在一些上边界的下面,就像在方法部分描述的一样。为了模拟EffcientNet的SiLU函数,它达到了一个更好的FS-转换如果参数被选择以这样一种他们能迭代的方式-并且从而更加精确-处理输入的范围在(-2,2),那发生地最频繁的就像门输入x哎EffcientNet。这用SiLU激活函数的和sigmoid激活函数的例子的FS神经元的结果动态被阐明在图三。
所有模拟人工神经网络拥有相同的激活函数的FS神经元能用相同的参数T(t)、h(t)和d(t),而他们的输出脉冲的权重中因素w是简单在被训练的人工神经网络中从相应的突触连接被拿起来。

第一排描述了FS神经元到一个低输入值的反应(x=-0.5)并且第二行展示了一个高输入的反应(x=0.5)。这第一列展示了一个SiLU的FS神经元的反应,而第二列是一个sigmoid的FS神经元。这T(t)的相关值和离散时间步数t的v(t)是被平滑地篡改例证。
注意到那个神经元的数量和网络中的连接是不被提升的通过FS-转换。然而一个拥有L层的前馈人工神经网络的计算步数L被因素K所提升。但是人工神经网络的计算能用一种流水线的行为被模拟,在这里一个新的网络输入被脉冲神经网络处理每2k次。在这个例子里,当FS神经元计算的时候,FS神经元的参数在长度K的时期里周期地改变。在FS神经元未激活的时间里这些K个时间步骤里跟着K个时间步骤,而在下一层的FS神经元收集了他们的脉冲输入给模拟下一个计算步骤或者人工神经网络的层。注意那个因为所有的拥有相同激活函数的模拟人工神经网络的FS-神经元都能用相同的参数T(t)、h(t)和d(t),他们要求只有一点点额外的记忆在一个神经形态的切片上。
TensorFlow代码和FS神经元的被选择的参数都在线可获得。















 3029
3029











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









