







基本信息
title:
X-Pool: Cross-Modal Language-Video Attention for Text-Video Retrieval
source:
CVPR2022
field:
video retrieval
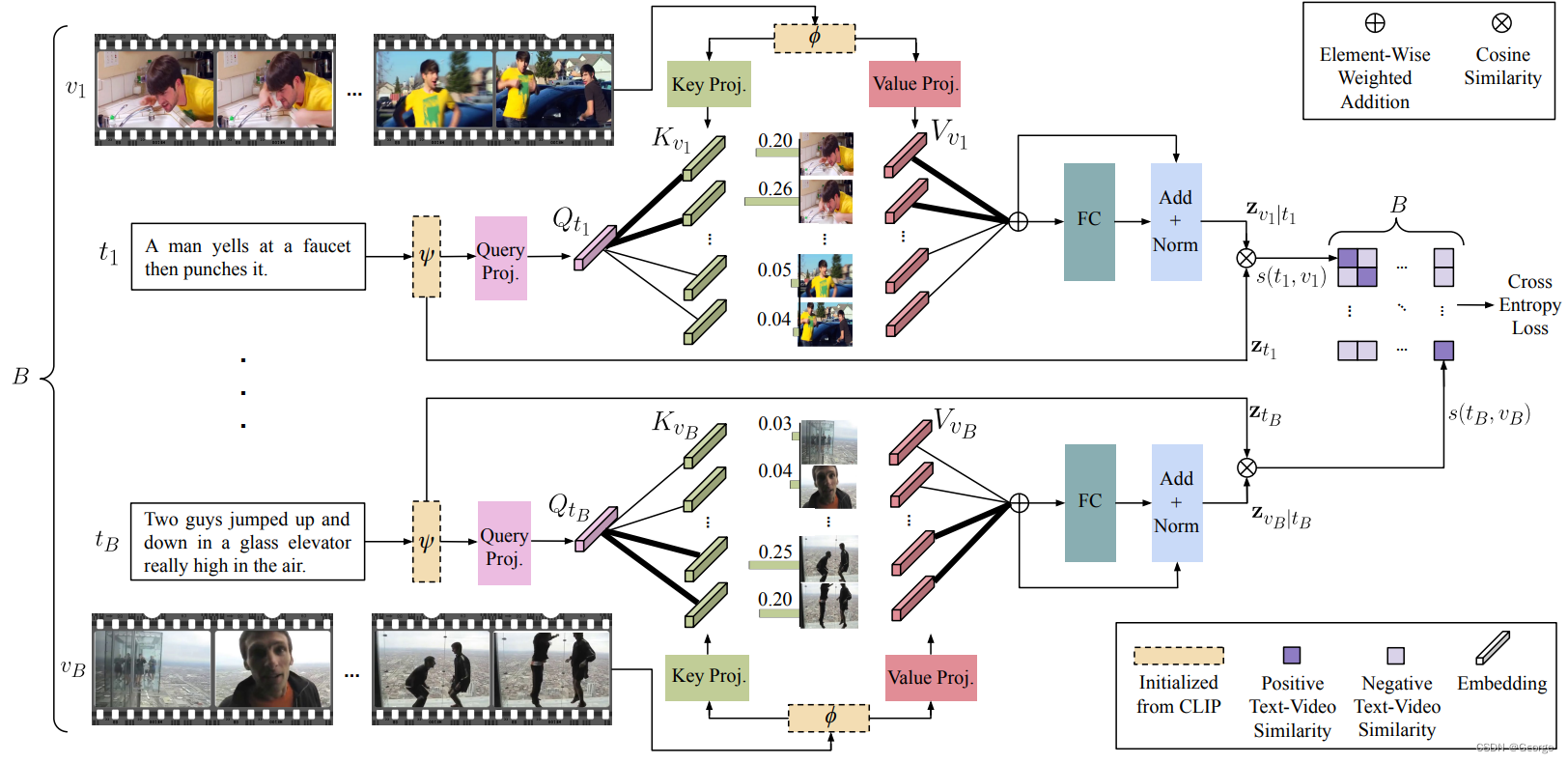
一句话亮点
用文本Query对视频K,V的attention定位具体片段
Motivation
视频承载的信息远多于文本,一句文本query往往只表达了一个视频的部分帧的部分区域信息,因此,同一个视频可以对应多个query。之前的研究大多是将视频看作一个整体,使用mean pooling或者self attention提取视频特征,再与文本query匹配,这样的视频特征携带的信息很杂,甚至有误导性。
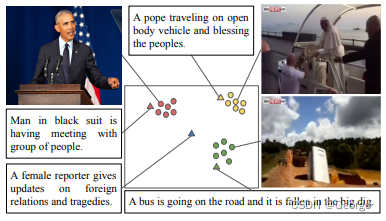
下图为同一个视频:
Contribution
提出了video retrieval任务中文本query对视频pooling的指导意义,并构建了cross attention模型以验证以上理论,在MSR-VTT, MSVD以及LSMDV数据集上取得了sota。
(相当于把temporal action localization任务的思路结合到video retrieval任务中)
模型结构
起始
为了实现对视频sub regions的选择,作者构建了一个top-k aggregation 方法:

其中:

直接选择与文本相似度最高的k个帧来聚合成为最终的video feature,这样做相对于baseline已经有了显著提高。
x-pool模型
cross-modal attention
用文本query的embedding做Q,用video frames的embeddings做K和V

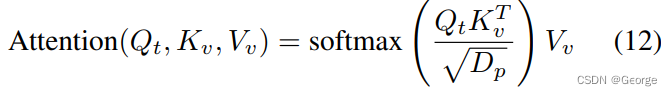
含义解释:映射自文本embedding的Q和映射自视频embedding的K做点积,作为权重矩阵,用来找出与文本相似度高的视频frame;映射自视频embedding的V作为被aggregate的对象,与前述权重矩阵相乘,得到最终的依赖于文本query语境的video表示。
最终的pooling:
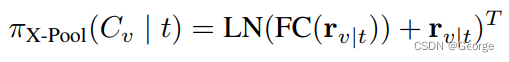
其中:
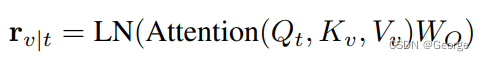
损失函数
交叉熵



其中
s
(
t
i
,
v
j
)
s(t_i, v_j)
s(ti,vj)是
t
i
t_i
ti和
v
j
v_j
vj的余弦相似度,B是batch size,
λ
\lambda
λ是可学习参数
实验
三个数据集:MSR-VTT, MSVD, LSMDC
metric: recall@1, recall@5, recall@10, median rank(MdR), mean rank(MnR)
backbone: CLIP
结果
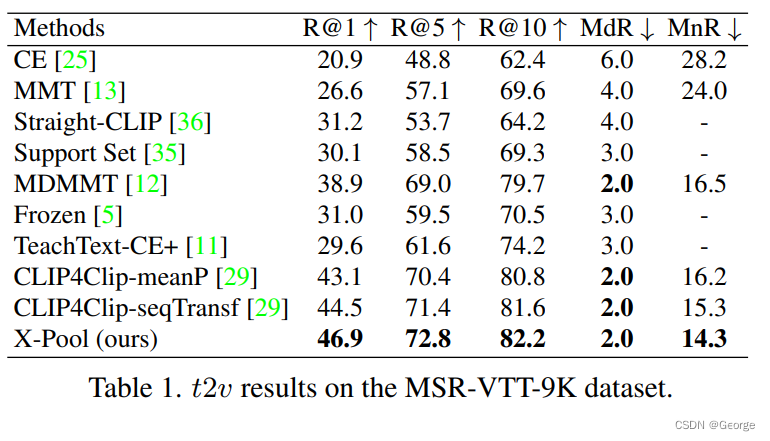

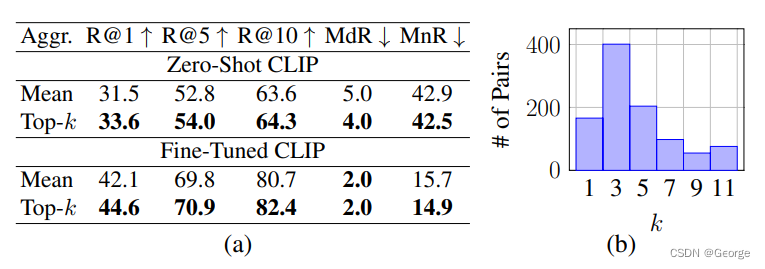
top-k方法的结果:
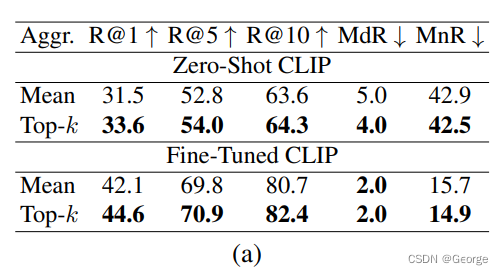
k的选择:

视频场景变化对模型的影响对比
为了验证motivation的合理性,由于现有数据集大多是经过剪裁的场景单一的短视频,作者通过在一个视频中插入其他视频的片段来引入场景变化,构建出新的场景变化数据集。对比了xpool模型和mean pool模型在这个数据集上的表现:

定性结果

关于实际应用
实际应用时,由于无法提前得知所有文本query,所以不能提前得到所有文本指导的视频embedding。如果还是按照训练阶段的流程,使用文本query来指导数据库中每个视频的特征pooling,然后再计算相似度,那样时间复杂度达到O(TV)(T为文本query个数,V为视频个数),效率太低。
为此,可以采用两阶段的检索方法,首先使用一个高召回率的模型,快速筛选出P个候选视频,然后对这P个视频使用X-pool的方法排序,最终取topk相似度最高的结果,时间复杂度可以达到O(TP),其中P<<V。原文中的主要实验结果就是采用这种方式得到的。实际上,相较于常见的学习common space的方法,这样做的效率还是比较低。
原文补充材料中描述如下:

















 522
522











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









