






一、赛题说明
赛题使用公开数据的问卷调查结果,选取其中多组变量,包括个体变量(性别、年龄、地域、职业、健康、婚姻与政治面貌等等)、家庭变量(父母、配偶、子女、家庭资本等等)、社会态度(公平、信用、公共服务等等),来预测其对幸福感的评价。
二、数据说明
考虑到变量个数较多,部分变量间关系复杂,数据分为完整版和精简版两类。先从精简版入手熟悉赛题后,使用完整版挖掘更多信息。complete文件为变量完整版数据,abbr文件为变量精简版数据。index文件中包含每个变量对应的问卷题目,以及变量取值的含义。
survey文件是数据源的原版问卷,作为补充以方便理解问题背景。
精简版数据如下:

完整版数据如下:

三、代码实践
Step 1 库函数导入
import numpy as np;
import pandas as pd;
import matplotlib.pyplot as plt;
import seaborn as sns;
import datetime as dt;
Step 2 读入数据
# 读入数据
data_train = pd.read_csv(r'C:\Users\Camel\Desktop\lx\happiness_train_abbr.csv',encoding='gbk')
data_test = pd.read_csv(r'C:\Users\Camel\Desktop\lx\happiness_test_abbr.csv',encoding='gbk')
data_train.shape
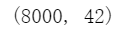
data_test.shape
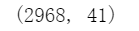
Step 3 数据可视化
#通过绘图观察数据分布
f,ax=plt.subplots(1,2,figsize=(18,8))
data_train['happiness'].value_counts().plot.pie(autopct='%1.1f%%',ax=ax[0])#autopct控制饼图内百分比设置
sns.countplot('happiness',data=data_train,ax=ax[1])#画条形图

Step 4 数据预处理
#训练集和测试集都添加年龄特征
data_train['age']=pd.to_datetime(data_train['survey_time']).dt.year-data_train['birth']
data_test['age']=pd.to_datetime(data_train['survey_time']).dt.year-data_test['birth']
#根据相关性系数选取特征
b=data_train.corr()['happiness']#计算happiness和各个特征的相关性
b=b[abs(b)>0.05];#取相关性系数大于0.05的特征,共20个
data_train=data_train[b.index];
#数据准备
#根据相关性系数选取特征
a=data_train.isnull().sum();
data_train=data_train.drop(columns=a[a>0].index);#删除有缺失值的列
x=data_train.drop(columns=['happiness']);
y=data_train['happiness'];
Step 5 模型建立
#GBDT集成学习梯度提升树算法
from sklearn.ensemble import GradientBoostingRegressor#GBDT的回归类
from sklearn.metrics import mean_squared_error#计算均方误差
from sklearn.externals import joblib#Joblib可以将模型保存到磁盘并可在必要时重新运行
from sklearn.model_selection import KFold#k-交叉验证
kfold = KFold(n_splits=15, shuffle = True, random_state= 12)
model = GradientBoostingRegressor(alpha=0.9, criterion='friedman_mse', init=None,
learning_rate=0.051, loss='ls', max_depth=4, max_features=10,
max_leaf_nodes=None, min_impurity_decrease=0.0,
min_impurity_split=None, min_samples_leaf=1,
min_samples_split=2, min_weight_fraction_leaf=0.0,
n_estimators=600, presort='auto', random_state=3,
subsample=0.98, verbose=0, warm_start=False)
mse = []
i = 0
for train, test in kfold.split(x):
X_train = x.iloc[train]
y_train = y.iloc[train]
X_test = x.iloc[test]
y_test = y.iloc[test]
model.fit(X_train,y_train)
y_pred = model.predict(X_test)
gbdt_mse = mean_squared_error(y_true=y_test,y_pred=y_pred)
mse.append(gbdt_mse)
#print("gbdt",gbdt_mse)
joblib.dump(filename="gbdt"+str(i),value=model)
i+=1
print("end=gbdt",np.mean(mse),mse)
















 9816
9816











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









