







 本文深入介绍了决策树在机器学习中的应用,包括其在sklearn库中的实现。通过红酒数据集展示了如何使用sklearn的DecisionTreeClassifier进行训练、测试和评估,并讨论了重要参数如criterion(信息熵和基尼系数)的影响。同时,文章还提到了在泰坦尼克号幸存者预测问题中的应用,指导读者实践决策树模型的构建和参数调优。
本文深入介绍了决策树在机器学习中的应用,包括其在sklearn库中的实现。通过红酒数据集展示了如何使用sklearn的DecisionTreeClassifier进行训练、测试和评估,并讨论了重要参数如criterion(信息熵和基尼系数)的影响。同时,文章还提到了在泰坦尼克号幸存者预测问题中的应用,指导读者实践决策树模型的构建和参数调优。
1 概述
决策树( Decision Tree )是一种非参数的有监督学习方法,它能够从一系列有特征和标签的数据中总结出决策规 则
并用树状图的结构来呈现这些规则,以解决分类和回归问题。决策树算法容易理解,适用各种数据,在解决各 种问题时都有良好表现
尤其是以树模型为核心的各种集成算法,在各个行业和领域都有广泛的应用。
1.1 sklearn中的决策树
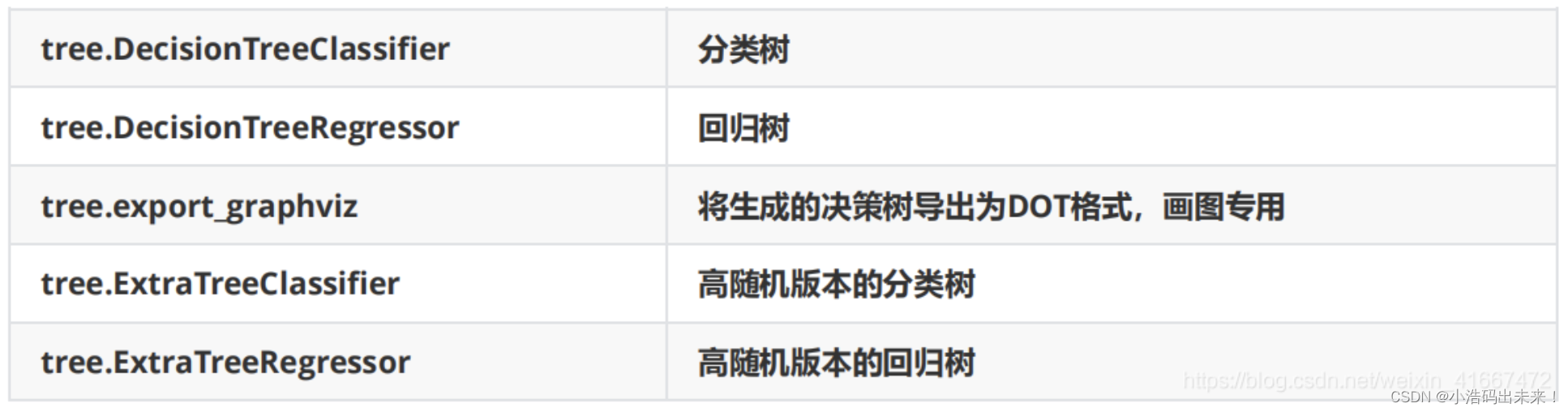
在sklearn模块中决策树是 sklearn.tree
sklearn 中决策树的类都在 ”tree“ 这个模块之下。这个模块总共包含五个类:
在开始敲代码之前,我们先看看sklearn建模的基本流程:
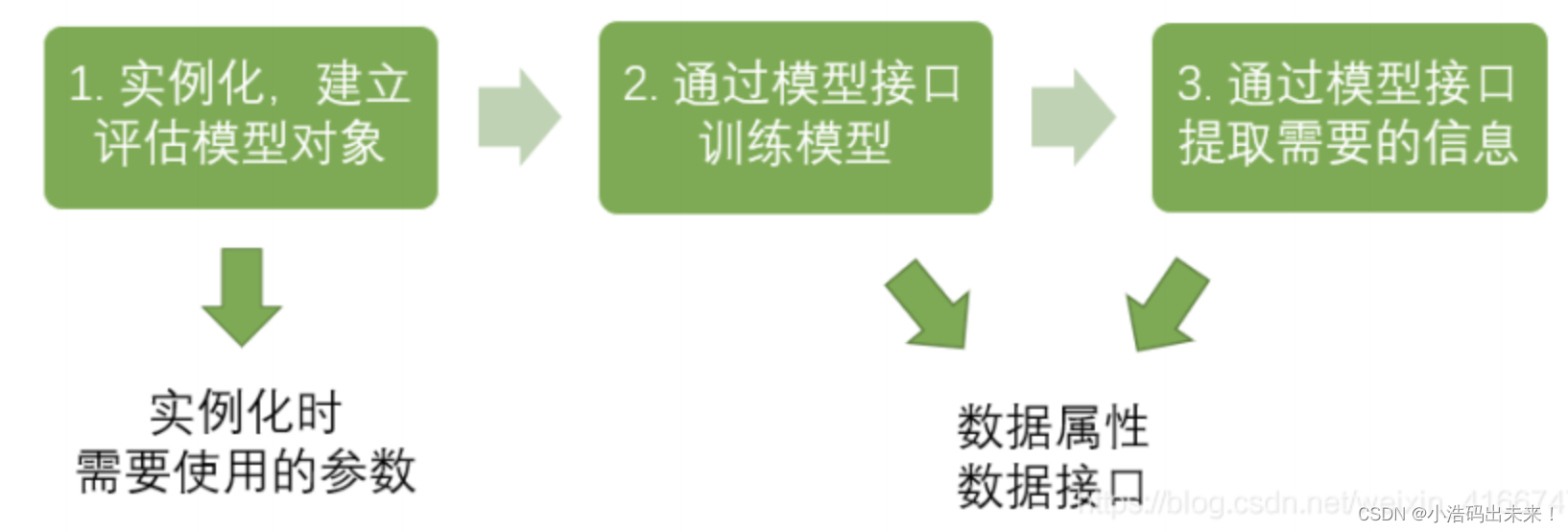
如果按照上图的流程,分类树的建模流程就是:
from sklearn import tree #导入需要的模块
clf = tree.DecisionTreeClassifier() #实例化
clf = clf.fit(X_train,y_train) #用训练集数据训练模型
result = clf.score(X_test,y_test) #导入测试集,从接口中调用需要的信息是不是只用了三行呢?!
下面我们用一个具体的例子来讲解分类树
2 DecisionTreeClassififier与红酒数据集
我们先看看分类树的参数:

是不是傻眼了?这么多,看到都脑阔疼。
没关系,接下来我们挑选其中重要的参数配合实际的例子来讲清楚。
2.1 重要参数
2.1.1 criterion
为了要将表格转化为一棵树,决策树需要找出最佳节点和最佳的分枝方法,对分类树来说,衡量这个 “ 最佳 ” 的指标 叫做“ 不纯度 ” 。
通常来说,不纯度越低,决策树对训练集的拟合越好。现在使用的决策树算法在分枝方法上的核心 大多是围绕在对某个不纯度相关指标的最优化上。
不纯度基于节点来计算,树中的每个节点都会有一个不纯度,并且子节点的不纯度一定是低于父节点的,也就是 说,在同一棵决策树上,叶子节点的不纯度一定是最低的。
Criterion 这个参数正是用来决定不纯度的计算方法的。 sklearn 提供了两种选择:
1 )输入 ”entropy“ ,使用 信息熵 ( Entropy )
2 )输入 ”gini“ ,使用 基尼系数 ( Gini Impurity )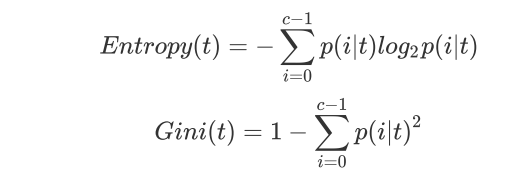
其中 t 代表给定的节点, i 代表标签的任意分类, 代表标签分类i 在节点 t 上所占的比例。
注意,当使用信息熵 时,sklearn 实际计算的是基于信息熵的信息增益 (Information Gain) ,即父节点的信息熵和子节点的信息熵之
 最低0.47元/天 解锁文章
最低0.47元/天 解锁文章
















 458
458











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









