







 本文介绍了偏度和峰度在数据统计中的意义,偏度反映分布对称性,峰度表示数据分布的尖锐程度。通过Python实验,创建正态分布数据并人为增加偏度和峰度,然后使用自然对数消除异常值,观察统计特性变化。同时指出网上部分计算skewness和kurtosis的Python代码存在的错误,并提供了修正后的正确代码。
本文介绍了偏度和峰度在数据统计中的意义,偏度反映分布对称性,峰度表示数据分布的尖锐程度。通过Python实验,创建正态分布数据并人为增加偏度和峰度,然后使用自然对数消除异常值,观察统计特性变化。同时指出网上部分计算skewness和kurtosis的Python代码存在的错误,并提供了修正后的正确代码。
晚上看神经网络的feature工程看到对偏度数据进行处理,已经忘了。。。查阅了一些资料,顺便写个小程序比较一下,记录下来
关于偏度和峰度的定义不再赘述,有很多文章
简单来说对于数据统计:
-
偏度能够反应分布的对称情况,右偏(也叫正偏),在图像上表现为数据右边脱了一个长长的尾巴,这时大多数值分布在左侧,有一小部分值分布在右侧。
-
峰度反应的是图像的尖锐程度:峰度越大,表现在图像上面是中心点越尖锐。在相同方差的情况下,中间一大部分的值方差都很小,为了达到和正太分布方差相同的目的,必须有一些值离中心点越远,所以这就是所说的“厚尾”,反应的是异常点增多这一现象。
Python的实验:
a. 先构造一个正态分布的随机100个数
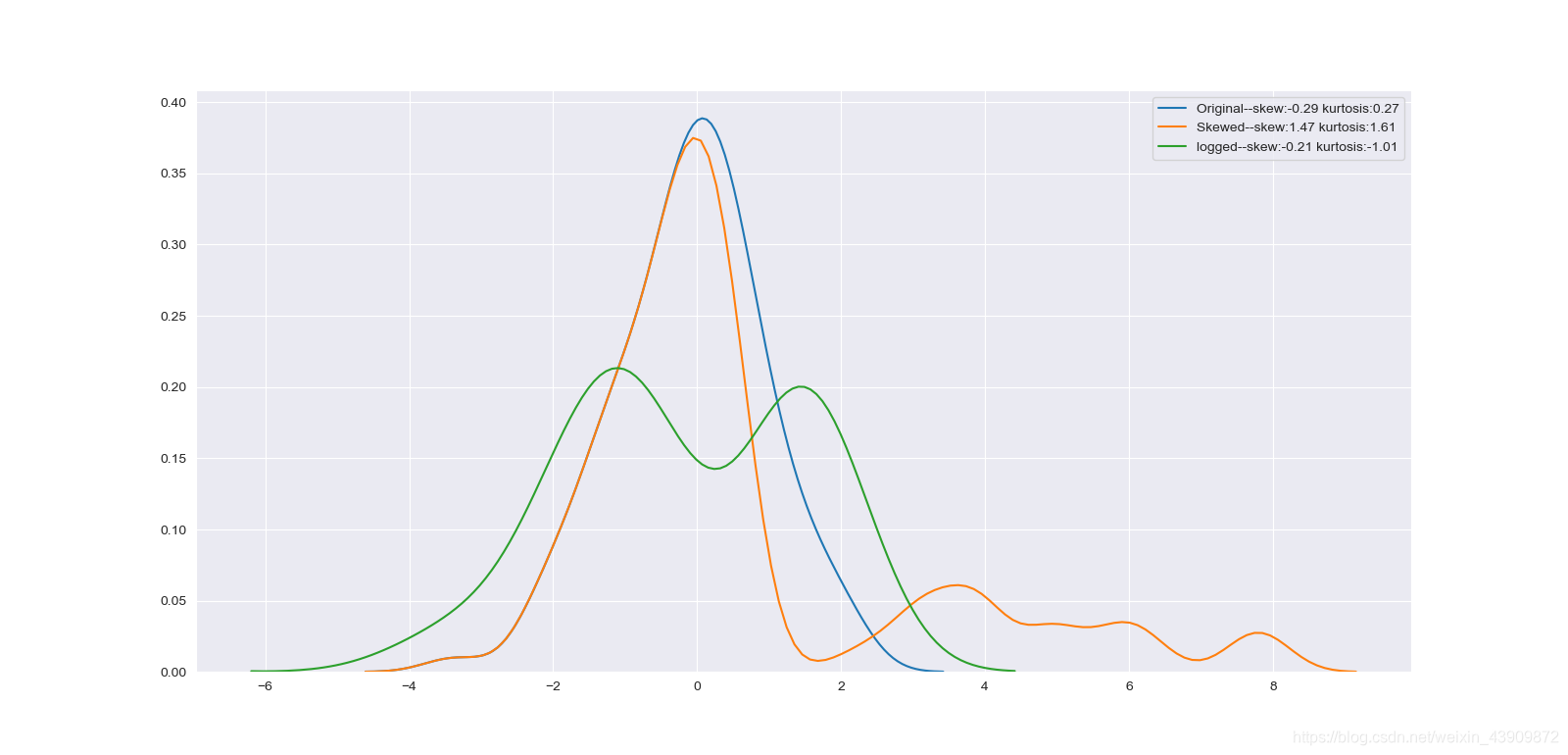
b. 把排序后比较大的20个数*4,造成偏度和峰度都变大的数据
c. 把所有数据都取自然对数,再看偏度和峰度
实验结果:
可以看到b操作增加了右边的尾巴厚度,直接增大了skewness和kurtosis的值,造成了正偏分布,而对所有数取log又把数据的概率密度扁平化了,减小了这两个值
PS:网上流传最多的直接用python计算skewness和kurtosis的代码是有错误的,下面贴了改动后的正确代码,这个例子是直接用pandas自带的函数算的
实验代码:
 最低0.47元/天 解锁文章
最低0.47元/天 解锁文章


















 1510
1510

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









