







文章来源
[1703.10135] TACOTRON: TOWARDS END-TO-END SPEECH SYNTHESISX: A Review
ABSTRUCT

文本语音合成通常由多个阶段组成:文本分析前端、声学模型和音频合成模块。
构建这些模块通常需要广泛的领域专业知识,可能还包含脆弱的设计选择。
Tacotron介绍:
In this paper, we present Tacotron, an end-to-end generative text-to-speech model that synthesizes speech directly from characters.
Given <text, audio> pairs, the model can be trained completely from scratch with random initialization.(给定文本语音对,Tacotron可以完全从零开始训练、随机初始化)
Tacotron提出了几个关键技术,使seq2seq框架能够完成这个具有挑战性的任务
Tacotron的优越性:
Tacotron achieves a 3.82 subjective 5-scale mean opinion score on US English, outperforming a production parametric system in terms of naturalness. (Tractron在美式英语测试中得分为3.82(总分5分),在自然度方面优于生产参数系统)
In addition, since Tacotron generates speech at the frame level, it’s substantially faster than sample-level autoregressive methods.
1. INTRODUCTION
现代TTS流水线是比较复杂的:
For example, it is common for statistical parametric TTS to have a
- text frontend extracting various linguistic features
- a duration model
- an acoustic feature prediction model
- a complex signal-processing-based vocoder (Zen et al., 2009; Agiomyrgiannakis, 2015).
现代TTS流水线的问题:
- These components are based on extensive domain expertise and are laborious to design.
- They are also trained independently, so errors from each component may compound. (由于每个组件被单独训练,所以每个组件的错误可能会加剧)
- The complexity of modern TTS designs thus leads to substantial engineering efforts when building a new system.(现代TTS设计的复杂性导致在构建新系统时需要大量的工程工作)
正因如此,集成一个能在少量人工标注的<文本,语音>配对集上的端到端TTS系统,会有诸多优势。
- Such a system alleviates the need for laborious feature engineering, which may involve heuristics and brittle design choices. (可以缓解费力的特征工程的需要,而正是这些特征工程可能导致启发式错误和脆弱的模型选择)
- It more easily allows for rich conditioning on various attributes, such as speaker or language, or high-level features like sentiment. This is because conditioning can occur at the very beginning of the model rather than only on certain components. (这样的系统允许基于各种属性来进行多样化的调节,比如不同说话人,不同语言,或者像情感这样的高层特征,这是因为调节不只是出现在特定几个组件中,而是在模型的最开始就发生了)
- Similarly, adaptation to new data might also be easier. (拟合新数据也变得容易)
- Finally, a single model is likely to be more robust than a multi-stage model where each component’s errors can compound.(相比于会出现错误叠加的多阶段模型,单一模型的鲁棒性会更好)
These advantages imply that an end-to-end model could allow us to train on huge amounts of rich, expressive yet often noisy data found in the real world.(这些优势意味着端到端模型能够允许我们在现实世界容易获取的大量丰富、有表现力的但是却经常有噪音的数据上进行训练)
TTS合成中的困难点:
TTS is a large-scale inverse problem: a highly compressed source (text) is “decompressed” into audio.(TTS是一个大规模的逆问题:将高度压缩的文本源解压成语音)
Since the same text can correspond to different pronunciations or speaking styles, this is a particularly difficult learning task for an end-to-end model: it must cope with large variations at the signal level for a given input.(由于相同的文本可以对应不同的发音或说话风格,所以对于一个端到端模型这是一个非常困难的任务:对于给定的输入端到端模型必须处理在信号层次的大量变化)
Moreover, unlike end-to-end speech recognition (Chan et al., 2016) or machine translation (Wu et al., 2016), TTS outputs are continuous, and output sequences are usually much longer than those of the input. (和端到端语音识别或者机器翻译不同,TTS的输出是连续的,而且输出序列经常比输入序列更长)
These attributes cause prediction errors to accumulate quickly.
Tacotron介绍:
Tacotron is an end-to-end generative TTS model based on the sequence-to-sequence (seq2seq) (Sutskever et al., 2014) with attention paradigm (Bahdanau et al., 2014).(Tacotron是一个带有注意力范式基于seq2seq的生成式TTS端到端模型)
Our model takes characters as input and outputs raw spectrogram, using several techniques to improve the capability of a vanilla seq2seq model. (该模型使用了几个可以改善普通seq2seq模型能力的技术,直接将字符作为输入、输出原始声谱图)
Given <text, audio> pairs, Tacotron can be trained completely from scratch with random initialization.(给定<文本,音频>配对数据,Tacotron可以直接随机初始化从头开始训练)
It does not require phoneme-level alignment, so it can easily scale to using large amounts of acoustic data with transcripts.(该模型不需要音素级对齐,所以能够很容易使用大量带有转录文本的声学数据)
With a simple waveform synthesis technique, Tacotron produces a 3.82 mean opinion score (MOS) on an US English eval set, outperforming a production parametric system in terms of naturalness.(通过简单的波形语音合成技术,Tacotron在美式英语评估数据集上获得了3.82的平均意见得分(MOS),在合成自然度方面已经超过了在生产中应用的参数系统)
2. RELATED WORK
-
WaveNet
WaveNet (van den Oord et al., 2016) is a powerful generative model of audio.
It works well for TTS, but is slow due to its sample-level autoregressive nature. It also requires conditioning on linguistic features from an existing TTS frontend, and thus is not end-to-end: it only replaces the vocoder and acoustic model.(WaveNet是一个强大的音频生成模型。它在TTS中表现良好,但是由于它样本级自回归的特性导致其速度很慢。它还要求在既存的TTS前端生成的语言特征上进行调节,因此它并不是端到端的:它只替换了声码器与声学模型部分。)
-
DeepVoice
Another recently-developed neural model is DeepV oice (Arik et al., 2017), which replaces every component in a typical TTS pipeline by a corresponding neural network. However, each component is independently trained, and it’s nontrivial to change the system to train in an end-to-end fashion.(DeepVoice使用神经网络替换了经典TTS流水线中的所有组件,但是它的每个组件都是单独训练的,将系统改变为端到端的形式进行训练并不容易。)
-
一个最早使用带有注意力的seq2seq的端到端TTS
To our knowledge, Wang et al. (2016) is the earliest work touching end-to-end TTS using seq2seq with attention.
However, it requires a pre-trained hidden Markov model (HMM) aligner to help the seq2seq model learn the alignment.(但是它需要一个预训练好的隐式马尔科夫对齐器来帮助seq2seq模型学习对齐)
It’s hard to tell how much alignment is learned by the seq2seq per se.(很难说seq2seq本身学习到了多少对齐能力)
Second, a few tricks are used to get the model trained, which the authors note hurts prosody.(在训练中使用的一些技巧有损于合成韵律)
Third, it predicts vocoder parameters hence needs a vocoder.(它预测了声码器参数作为中间特征表达,因此需要一个声码器)
Furthermore, the model is trained on phoneme inputs and the experimental results seem to be somewhat limited.(模型训练时输入的音素,并且在实验结果也有一定的局限性)
-
Char2Wav
Char2Wav (Sotelo et al., 2017) is an independently-developed end-to-end model that can be trained on characters.(Char2Wav是一个可以在字符上进行训练的独立开发的端到端模型)
However, Char2Wav still predicts vocoder parameters before using a SampleRNN neural vocoder (Mehri et al., 2016), whereas Tacotron directly predicts raw spectrogram.(但是该模型仍在使用SampleRNN神经声码器之前预测声码器参数,而Tacotron直接预测原始声谱图)
Also, their seq2seq and SampleRNN models need to be separately pre-trained, but our model can be trained from scratch.(Char2Wav的seq2seq和SampleRNN需要单独与预训练)
Finally, we made several key modifications to the vanilla seq2seq paradigm. As shown later, a vanilla seq2seq model does not work well for character-level inputs.(Tacotron对普通的seq2seq进行了一些关键修改,普通的seq2seq模型不适用于字符输入)
3 MODEL ARCHITECTURE
The backbone of Tacotron is a seq2seq model with attention (Bahdanau et al., 2014; Vinyals et al., 2015).
图一描述了Tacotron模型,包括一个编码器,一个基于注意力的解码器和后处理网络
从high-level上看,Tacotron直接将字符作为输入,然后产生声谱帧,之后再将它们转为波形
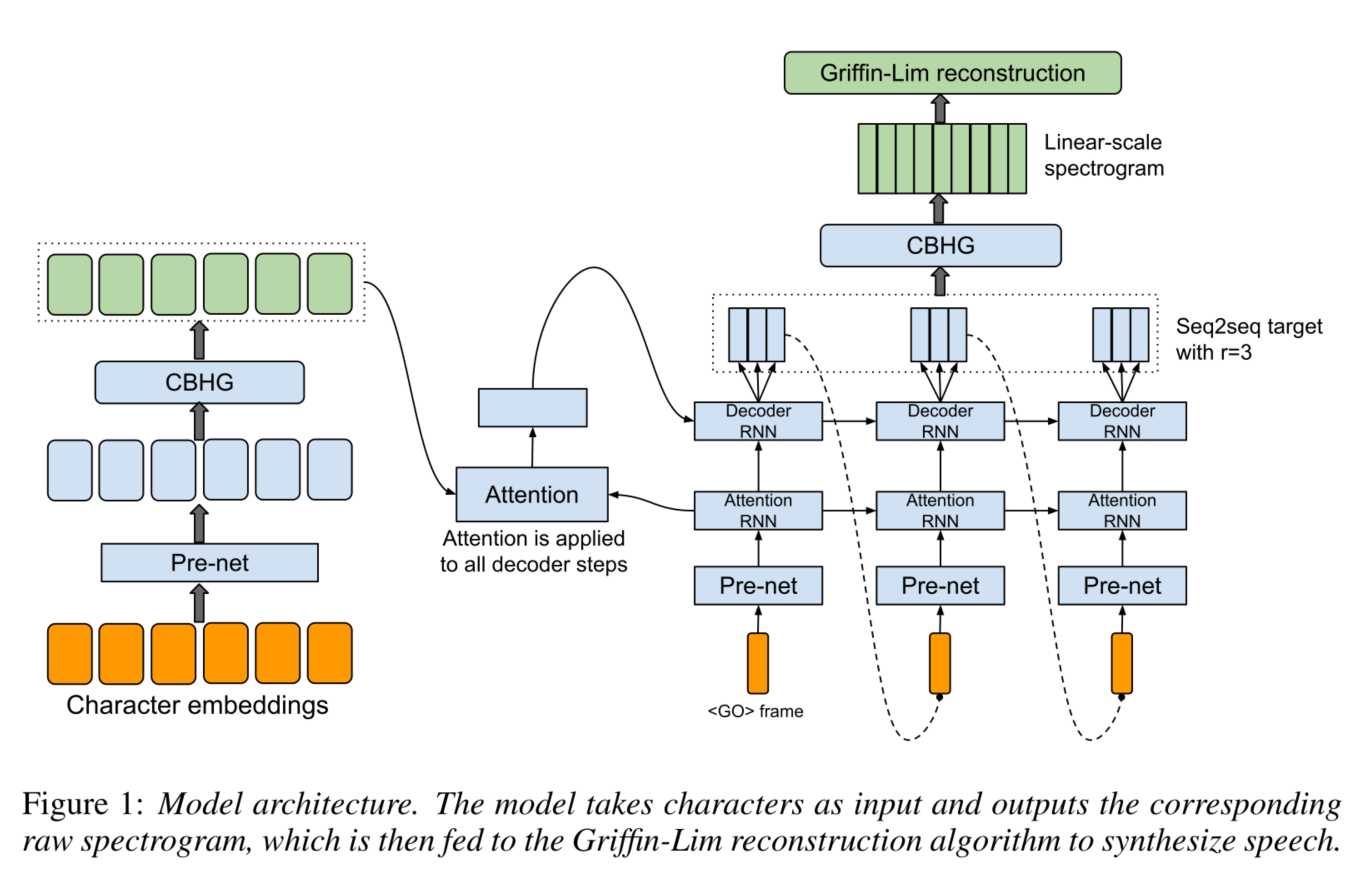
3.1 CBHG MODULE
CBHG is a powerful module for extracting representations from sequences.
CBHG is inspired from work in machine translation (Lee et al., 2016), where the main differences from Lee et al. (2016) include using non-causal convolutions(非因果卷积), batch normalization, residual connections, and stride=1 max pooling.
We found that these modifications improved generalization.
CBHG的功能是从输入中提取有价值的特征,有利于提高模型的泛化能力。
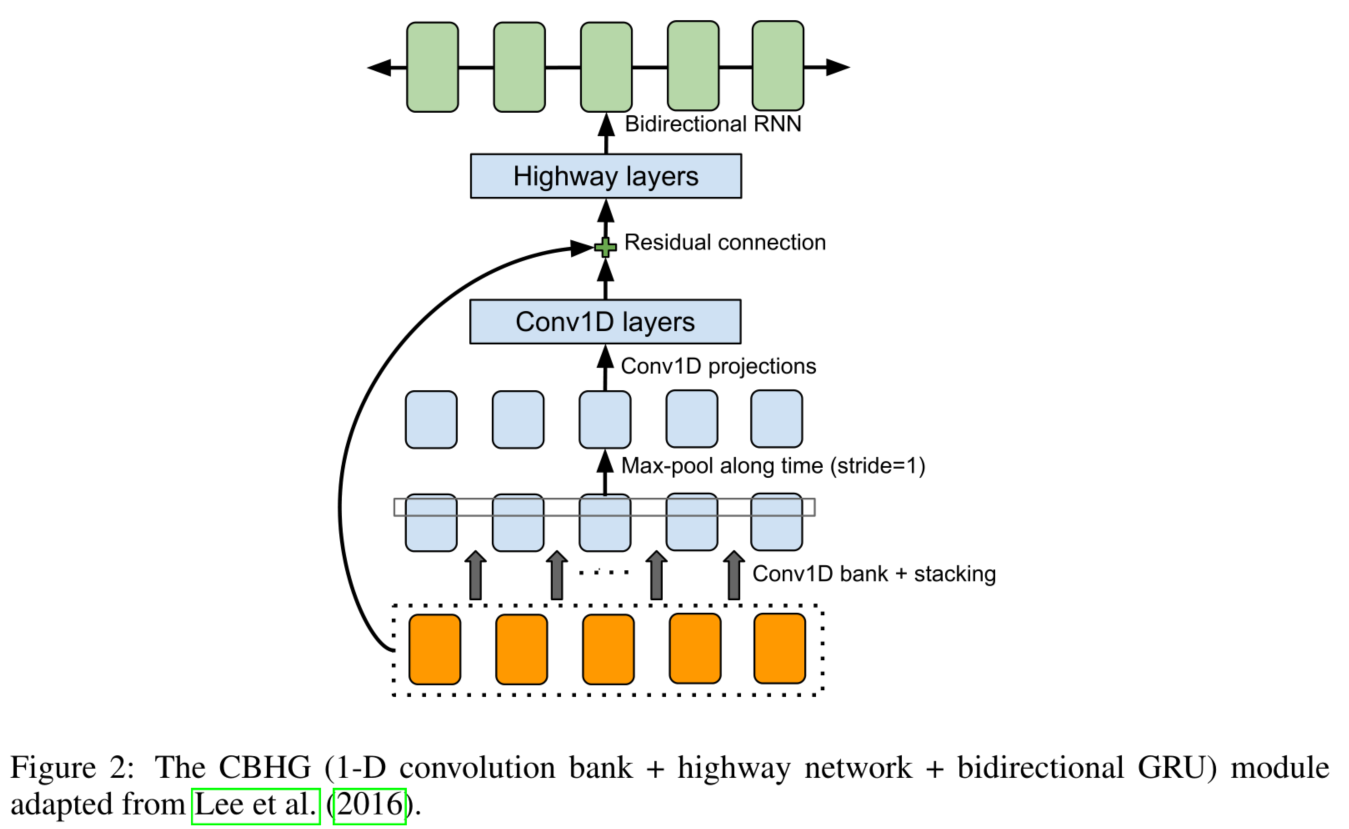
CBHG的组成:(Cov1d Bank、卷积层、残差连接、Highway、双向GRU)
CBHG consists of a bank of 1-D convolutional filters, followed by highway networks (Srivastava et al., 2015) and a bidirectional gated recurrent unit (GRU) (Chung et al., 2014) recurrent neural net (RNN).(CBGH包含一个一维卷积滤波器组,后跟一个高速公路网络和一个双向GRU)
CBHG is a powerful module for extracting representations from sequences.
CBHG工作过程:
1. 卷积部分:Cov1d Bank + 卷积层 + residual connection
The input sequence is first convolved with K sets of 1-D convolutional filters, where the k-th set contains Ck filters of width k (i.e. k = 1, 2, . . . , K). These filters explicitly model local and contextual information (akin to modeling unigrams, bigrams, up to K-grams).
(输入序列首先会经过一个卷积层,注意这个卷积层,它有K个大小不同的1维的filter,其中filter的大小为1,2,3…K。这些大小不同的卷积核提取了长度不同的上下文信息。 其实就是n-gram语言模型的思想,K的不同对应了不同的gram, 例如unigrams, bigrams, up to K-grams。)(K由输入决定)
The convolution outputs are stacked together and further max pooled along time to increase local invariances. Note that we use a stride of 1 to preserve the original time resolution.
然后,将经过不同大小的k个卷积核的输出堆积在一起(注意:在做卷积时,运用了padding,因此这k个卷积核输出的大小均是相同的),也就是把不同的gram提取到的上下文信息组合在一起,下一层为最大池化层,stride为1,width为2。
We further pass the processed sequence to a few fixed-width 1-D convolutions, whose outputs are added with the original input sequence via residual connections (He et al., 2016).
经过池化之后,会再经过两层一维的卷积层。第一个卷积层的filter大小为3,stride为1,采用的激活函数为ReLu;第二个卷积层的filter大小为3,stride为1,没有采用激活函数(在这两个一维的卷积层之间都会进行bn)
经过卷积层之后,会进行一个residual connection。也就是把卷积层输出的和embeding之后的序列相加起来。
Batch normalization (Ioffe & Szegedy, 2015) is used for all convolutional layers.
每一个卷积层都使用Batch normalization。
2. highway network:
作用:The convolution outputs are fed into a multi-layer highway network to extract high-level features.
之后将结果输入到highway layers,highway nets的每一层结构为:把输入同时放入到两个一层的全连接网络中,这两个网络的激活函数分别采用了ReLu和sigmoid函数。
假定输入为input,ReLu的输出为output1、sigmoid的输出 output2,那么highway layer的输出为output=output1∗output2+input∗(1−output2)。论文中使用了4层highway layer。
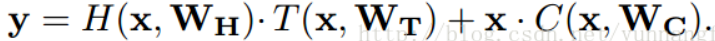
其中C等于1-T,x为输入, y 为对应的输出,T为transfer gate,C为carry gate,其实就是让网络的输出由两部分组成,分别是网络的直接输入以及输入变形后的部分。
使用highway network的原因:是一种减少缓解网络加深带来过拟合问题,以及减少较深网络的训练难度的一个trick。它主要受到LSTM门限机制的启发。
3. 双向GRU:
作用:We stack a bidirectional GRU RNN on top to extract sequential features from both forward and backward context.
3.2 ENCODER
Encoder的目标:
The goal of the encoder is to extract robust sequential representations of text.
Encoder的过程:
Encoder embed layer:
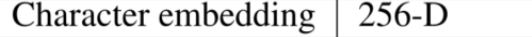
The input to the encoder is a character sequence, where each character is represented as a one-hot vector and embedded into a continuous vector.
Encoder pre-net module:
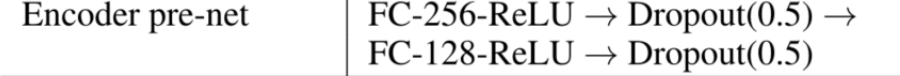
We then apply a set of non-linear transformations, collectively called a “pre-net”, to each embedding.
We use a bottleneck layer with dropout as the pre-net in this work, which helps convergence and improves generalization.
embeding layer之后是一个encoder pre-net模块,它有两个隐藏层,层与层之间的连接均是全连接;第一层的隐藏单元数目与输入单元数目一致,第二层的隐藏单元数目为第一层的一半;两个隐藏层采用的激活函数均为ReLu,并保持0.5的dropout来提高泛化能力。
CBHG:
A CBHG module transforms the pre-net outputs into the final encoder representation used by the attention module.
CBHG模块将pre-net输出转化为注意力模块使用的最终编码器表示。
Tacotron中Encoder的优势:
We found that this CBHG-based encoder not only reduces overfitting, but also makes fewer mispronunciations than a standard multi-layer RNN encoder (see our linked page of audio samples).
3.3 DECODER
decoder模块主要分为三部分:
- pre-net
- Attention-RNN
- Decoder-RNN
1. pre-net:
Pre-net的结构与encoder中的pre-net相同,主要是对输入做一些非线性变换。
2. Attention RNN:
Attention-RNN的结构为一层包含256个GRU的RNN,它将pre-net的输出作为输入,经过GRU单元后输出到decoder-RNN中。
3. Decoder RNN:
Decode-RNN为两层residual GRU。每层同样包含了256个GRU单元。第一步decoder的输入为all-zero frame( frame),之后都会把第t步的输出作为第t+1步的输入。(这里paper中使用了一个trick,就是每次decoder的时候,不仅仅预测1帧的数据,而是预测多个非重叠的帧。相邻的帧其实是有一定的关联性的,所以每个字符在发音的时候,可能对应了多个帧,因此每个GRU单元输出为多个帧的音频文件。)
Decoder介绍:
Attention的query:
We use a content-based tanh attention decoder (see e.g. Vinyals et al. (2015)), where a stateful recurrent layer produces the attention query at each decoder time step.
使用一个基于内容的tanh注意力decoder(加性模型),在每个时间步上都产生一次Attention query。
Decoder RNN的输入:
We concatenate the context vector and the attention RNN cell output to form the input to the decoder RNNs.
将Attention的输出(上下文向量)和Decoder中的Attention RNN的输出结合作为Decoder RNNs的输入。
Decoder RNN的组成:
We use a stack of GRUs with vertical residual connections (Wu et al., 2016) for the decoder.
Decoder RNN使用两层residual GRU。
We found the residual connections speed up convergence.(可以加快收敛速度)
Decoder的target选择:
The decoder target is an important design choice.
While we could directly predict raw spectrogram, it’s a highly redundant representation for the purpose of learning alignment between speech signal and text (which is really the motivation of using seq2seq for this task). (虽然我们可以直接预测原始频谱(直接从Decoder RNN输出raw spectrogram),但对于学习语音信号和文本之间的对齐方式来说,它是一个高度冗余的表示)
Because of this redundancy, we use a different target for seq2seq decoding and waveform synthesis.(选取不同的target)
We use 80-band mel-scale spectrogram as the target, though fewer bands or more concise targets such as cepstrum could be used.(使用80-band Mel-scale spectrogram == mel-spectrogram作为目标,尽管可以使用更少的波段或更简洁的目标,如倒频谱。)
spectrogram的size通常是很大的,因此直接生成会非常耗时,而mel-spectrogram虽然损失了信息,但是相比spectrogram就小了很多,且由于它是针对人耳来设计的,因此对最终生成的波形的质量不会有很多影响。
Tacotron中预测的trick:
We use a simple fully-connected output layer to predict the decoder targets.
An important trick we discovered was predicting multiple, non-overlapping output frames at each decoder step.
Predicting r frames at once divides the total number of decoder steps by r, which reduces model size, training time, and inference time.
More importantly, we found this trick to substantially increase convergence speed, as measured by a much faster (and more stable) alignment learned from attention.
一个重要技巧,每一步解码同时预测r个语音帧,减小了模型大小、训练和推断时间、大幅加快收敛速度。这样也可使Attention模块快速对齐,可能是因为每个字符通常对应了多个语音帧而相邻的语音帧具有相关性,同时输出多帧允许注意力在训练中更早向前移动。
Decoder各个时间步的输入:
The first decoder step is conditioned on an all-zero frame, which represents a frame.
Inference
In inference, at decoder step t, the last frame of the r predictions is fed as input to the decoder at step t + 1. (在推理中,在解码器的步骤t,r个预测得到的frame的最后一帧被作为输入输入到步骤t+1的解码器。)
Note that feeding the last prediction is an ad-hoc choice here – we could use all r predictions.
Training
Feed every r-th ground truth frame to the decoder. The input frame is passed to a pre-net as is done in the encoder.
3.4 POST-PROCESSING NET AND WAVEFORM SYNTHESIS
post-processing net的介绍:
和seq2seq网络不同的是,tacotron在decoder-RNN输出之后并没有直将其作为输出通过Griffin-Lim算法合成音频,而是添加了一层post-processing模块。
增加后处理网络的原因:
首先是因为我们使用了Griffin-Lim重建算法,根据频谱生成音频。
Griffin-Lim原理是:我们知道相位是描述波形变化的,我们从频谱生成音频的时候,需要考虑连续帧之间相位变化的规律,如果找不到这个规律,生成的信号和原来的信号肯定是不一样的,Griffin-Lim算法解决的就是如何不弄坏左右相邻的幅度谱和自身幅度谱的情况下,求一个近似的相位,因为相位最差和最好情况下天壤之别,所有应该会有一个相位变化的迭代方案会比上一次更好一点,而Griffin-Lim算法找到了这个方案。这里说了这么多,其实就是Griffin-Lim算法需要看到所有的帧。post-processing可以在一个线性频率范围内预测幅度谱(spectral magnitude)。
其次,post-processing能看到整个解码的序列,而不像seq2seq那样,只能从左至右的运行。它能够通过正向传播和反向传播的结果来修正每一帧的预测错误。
post-processing net的任务:
As mentioned above, the post-processing net’s task is to convert the seq2seq target to a target that can be synthesized into waveforms.
Since we use Griffin-Lim as the synthesizer, the post-processing net learns to predict spectral magnitude sampled on a linear-frequency scale.
声码器采用的是Griffin-lim,由于其需要输入的是线性声谱图,而我们decoder的输出时mel谱图,故利用CBHG模块进行一步转换。
In contrast to seq2seq, which always runs from left to right, it has both forward and backward information to correct the prediction error for each individual frame.
post-processing能看到整个解码的序列,而不像seq2seq那样,只能从左至右的运行。它能够通过正向传播和反向传播的结果来修正每一帧的预测错误。
4 MODEL DETAILS
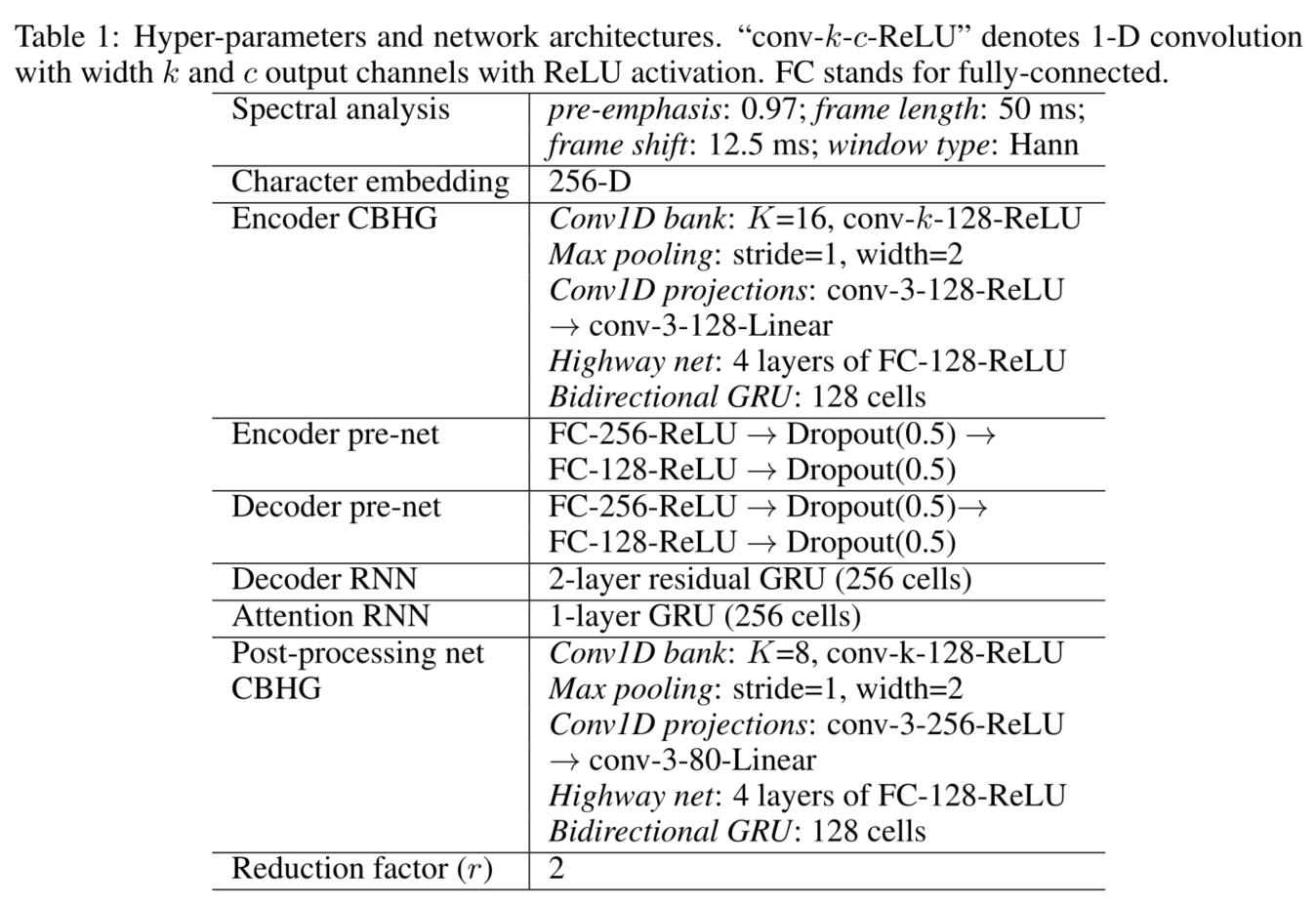
Table 1 lists the hyper-parameters and network architectures.
We use log magnitude spectrogram with Hann windowing, 50 ms frame length, 12.5 ms frame shift, and 2048-point Fourier transform.(我们使用对数幅度谱图,采用汉恩开窗,50毫秒帧长,12.5毫秒帧移,2048点傅里叶变换。)
We also found pre-emphasis (0.97) to be helpful.(**我们还发现预加重(0.97)是有帮助的)
We use 24 kHz sampling rate for all experiments.(我们在所有的实验中使用24kHz的采样率)
We use r = 2 (output layer reduction factor) for the MOS results in this paper, though larger r values
(e.g. r = 5) also work well.(在本文的MOS结果中,我们使用r = 2,尽管更大的r值(如r = 5)也很好)We use the Adam optimizer (Kingma & Ba, 2015) with learning rate decay, which starts from 0.001 and is reduced to 0.0005, 0.0003, and 0.0001 after 500K, 1M and 2M global steps, respectively.(我们使用Adam优化器,学习率衰减,从0.001开始,经过500K、1M和2M的全局步骤,分别减少到0.0005、0.0003和0.0001。)
We use a simple ‘1 loss for both seq2seq decoder (mel-scale spectrogram) and post-processing net (linear-scale spectrogram).(我们对seq2seq解码器(mel-scale spectrogram)和后处理网(linear-scale spectrogram)都使用一个简单的’1损失。)
The two losses have equal weights.
We train using a batch size of 32, where all sequences are padded to a max length.(我们使用32个批次的大小进行训练,其中所有的序列都被填充到最大长度。)
It’s a common practice to train sequence models with a loss mask, which masks loss on zero-padded frames.(用损失掩码训练序列模型是一种常见的做法,它掩盖了零填充帧的损失。)
However, we found that models trained this way don’t know when to stop emitting outputs, causing repeated sounds towards the end.(然而,我们发现这样训练出来的模型不知道什么时候停止输出,导致重复的声音接近尾声)
One simple trick to get around this problem is to also reconstruct the zero-padded frames.(绕过这个问题的一个简单的技巧是也要重建零填充的帧。)
5 EXPERIMENTS
训练使用的数据集:
We train Tacotron on an internal North American English dataset, which contains about 24.6 hours of speech data spoken by a professional female speaker. The phrases are text normalized, e.g. “16” is converted to “sixteen”.(我们在一个内部的北美英语数据集上训练Tacotron,该数据集包含一个专业的女性演讲者所讲的大约24.6小时的语音数据。这些短语经过了文本规范化处理,例如 "16 "被转换为 “十六”。)
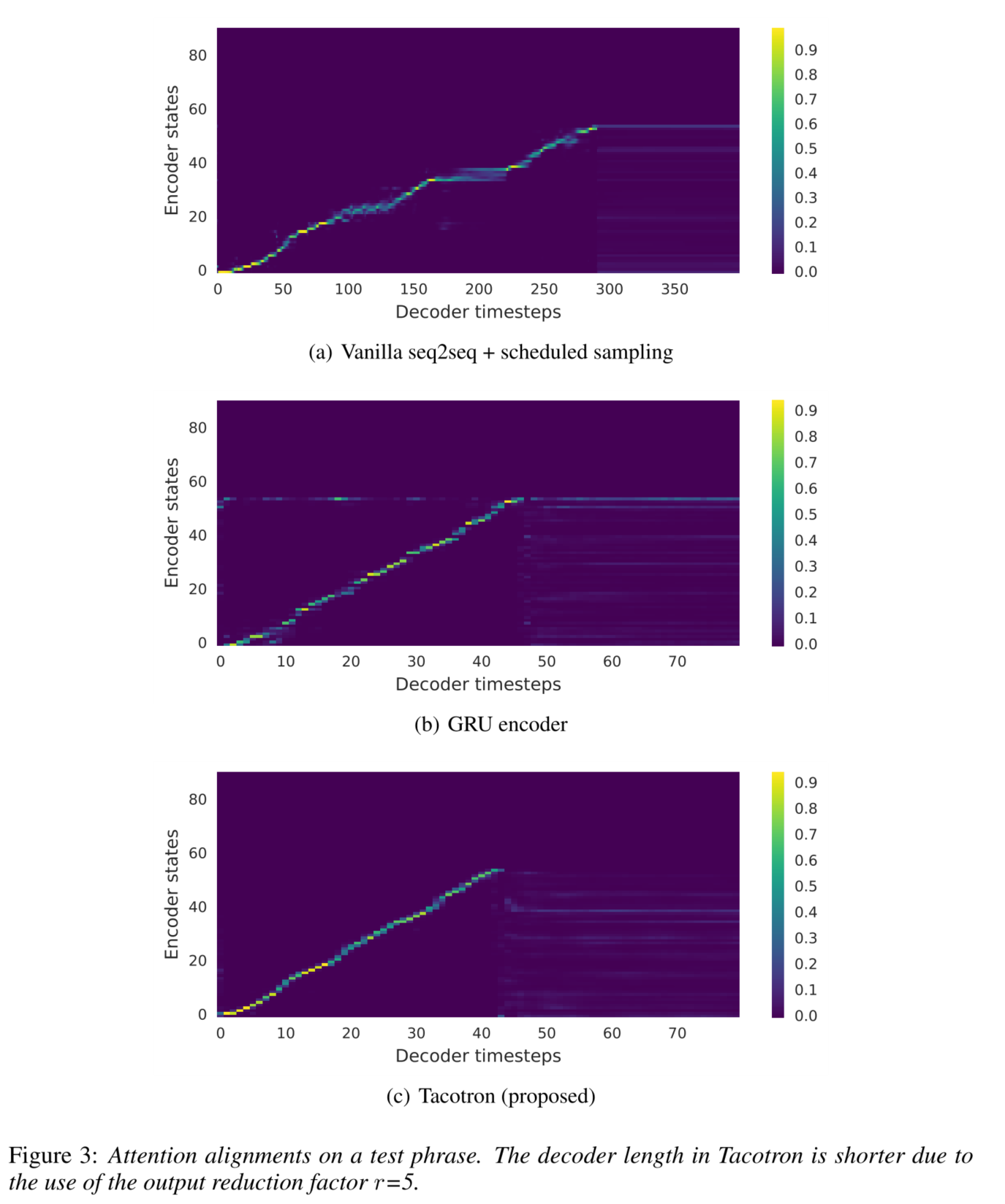
5.1 ABLATION ANALYSIS(消融分析)
消融分析的方法是从最佳表现出发,逐步去除这些特征,观察算法的准确率变化
1. vanilla seq2seq model:
First, we compare with a vanilla seq2seq model. Both the encoder and decoder use 2 layers of residual RNNs, where each layer has 256 GRU cells (we tried LSTM and got similar results).
No pre-net or post-processing net is used, and the decoder directly predicts linear-scale log magnitude spectrogram.
首先,我们与一个普通的seq2seq模型进行比较。编码器和解码器都使用2层残余RNNs,其中每层有256个GRU单元(我们尝试了LSTM,得到了类似的结果)。没有使用前网或后处理网,解码器直接预测线性谱图。
We found that scheduled sampling (sampling rate 0.5) is required for this model to learn alignments and generalize. (scheduled sampling(0.5)是必须的)
We show the learned attention alignment in Figure 3.
Figure 3(a) reveals that the vanilla seq2seq learns a poor alignment.
One problem is that attention tends to get stuck for many frames before moving forward, which causes bad speech intelligibility in the synthesized signal. The naturalness and overall duration are destroyed as a result.(注意力在向前移动之前会卡住很多帧,导致合成的语音可理解性较差。自然性和整体持续时间被破坏)
In contrast, our model learns a clean and smooth alignment, as shown in Figure 3©.
2. 使用2层residual GRU替代CBGH encoder:
Comparing Figure 3(b) and 3©, we can see that the alignment from the GRU encoder is noisier.(GRU编码器的对齐方式更嘈杂)
Listening to synthesized signals, we found that noisy alignment often leads to mispronunciations. (导致合成语音发音错误)
The CBHG encoder reduces overfitting and generalizes well to long and complex phrases.(CBHG编码器减少了过拟合,并且对长而复杂的短语可以很好的泛化。)
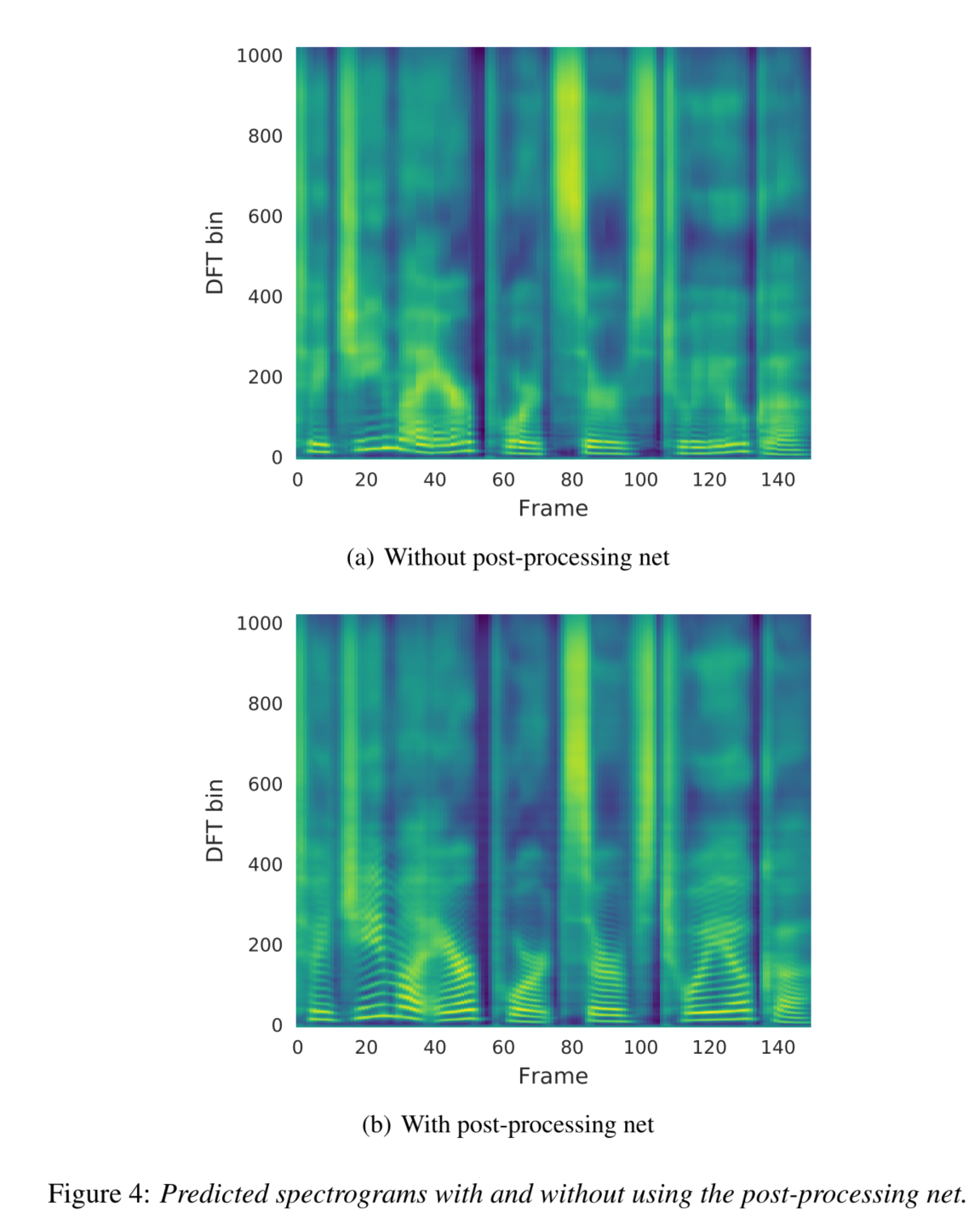
是否使用后处理网络的比较:
Figures 4(a) and 4(b) demonstrate the benefit of using the post-processing net.
We trained a model without the post-processing net while keeping all the other components untouched (except that the decoder RNN predicts linear-scale spectrogram).
With more contextual information, the prediction from the post-processing net contains better resolved harmonics (e.g. higher harmonics between bins 100 and 400) and high frequency formant structure, which reduces synthesis artifacts.
好处:有了更多的上下文信息,来自后处理网的预测包含了更好的解决谐波(例如,100和400分档之间的更高的谐波)和高频的声调结构,这减少了合成的伪影。
5.2 MEAN OPINION SCORE TESTS
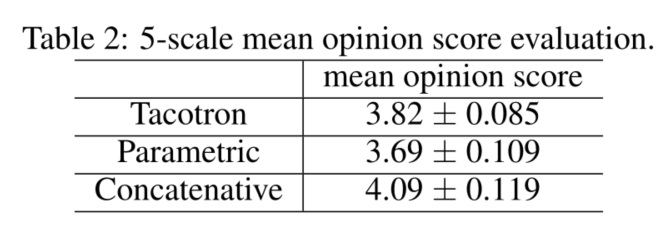
The MOS tests were crowdsourced from native speakers.
100 unseen phrases were used for the tests and each phrase received 8 ratings. (测试中使用100个没有见过的短语,每个短语有8个评分)
When computing MOS, we only include ratings where headphones were used. We compare our model with a parametric (based on LSTM (Zen et al., 2016)) and a concatenative system (Gonzalvo et al., 2016), both of which are in production.(当计算MOS时,我们只包括使用了耳机的评分。我们将我们的模型与一个基于LSTM参数化和一个连接系统进行比较,这两个系统都在使用中。)
As shown in Table 2, Tacotron achieves an MOS of 3.82, which outperforms the parametric system.
Given the strong baselines and the artifacts introduced by the Griffin-Lim synthesis, this represents a very promising result.















 1686
1686











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









