









 InstructGPT是通过人类反馈微调GPT-3,以提高模型遵循用户意图的能力。通过有监督学习和基于人工排序的强化学习(使用PPO算法),InstructGPT在减少参数量的情况下,其性能超过了未经优化的GPT-3。文章强调了强化学习在大型语言模型中的应用价值。
InstructGPT是通过人类反馈微调GPT-3,以提高模型遵循用户意图的能力。通过有监督学习和基于人工排序的强化学习(使用PPO算法),InstructGPT在减少参数量的情况下,其性能超过了未经优化的GPT-3。文章强调了强化学习在大型语言模型中的应用价值。
最近抽空想梳理下GPT的相关工作,现在大模型越来越重要了,可以解决很多很复杂的问题。这里简单梳理一下InstructGPT的相关工作,论文链接:https://arxiv.org/pdf/2203.02155.pdf。
一、前言
InstructGPT做了什么,从论文的摘要来描述是:
使语言模型变得更大并不意味着它们本身就能更好地遵循用户的意图。 例如,大型语言模型可能会生成不真实、有毒或对用户毫无帮助的输出。 换句话说,这些模型与其用户不一致。 在本文中,我们展示了一种通过根据人类反馈进行微调,使语言模型与用户在各种任务上的意图保持一致的途径。 从一组标记器编写的提示和通过 OpenAI API 提交的提示开始,我们收集了所需模型行为的标记器演示数据集,我们使用该数据集通过监督学习来微调 GPT-3。 然后,我们收集模型输出排名的数据集,用于通过人类反馈的强化学习进一步微调该监督模型。 我们将生成的模型称为 InstructGPT。 在对我们的即时分布的人类评估中,1.3B 参数 InstructGPT 模型的输出优于 175B GPT-3 的输出,尽管参数少了 100 倍。
简单总结就是:我们能从现实中获取的数据普遍质量不高,导致模型没法深层次理解人类的意图从而输出了一些意义不是很深的结果,这个问题没法通过模型的结构或者参数量进行修复。为此,引入了人工强化学习,直接借助人工提取出更高质量的,能够更深层次反应人类意图的数据信息。
二、InstructGPT 做了什么
先看模型的整体训练流程:
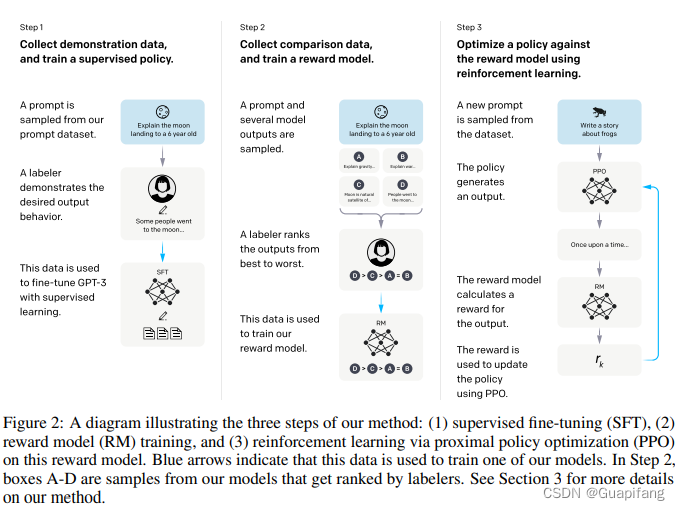
InstructGPT训练流程中,涉及到两套训练数据集的获取:一套用于有监督微调训练得到一个基础的GPT模型,另外一套用于人工排序训练得到一个激励模型reward model (RM)。
InstructGPT展示了3个训练流程:
(1)先有监督微调训练得到一个基础GPT模型;
(2)人工排序数据集训练得到一个激励模型reward model (RM);
(3)利用步骤(1)的GPT模型和步骤(2)激励模型RM反复交替训练,进行人工强化训练。
步骤(1)就是简单的有监督微调,没啥说的,重点说下步骤(2)和步骤(3)。
步骤(2)中当给定一段输入和对应的4个答案输出ABCD,会让人工进行排序,排序觉得更符合自己期望的答案的在前面。如框架图中展示的D>C>A=B。
现在来到重点,激励模型怎么训练呢?根据上面这个人工排好的顺序,类似于做了一个对比学习,激励模型输出的分数答案靠前的要大于答案靠后的,比如Score_D > Score_C.

训练好得到激励模型RM后,开始进入步骤(3),步骤(3)就是采用的人工强化学习中的PPO算法进行训练。整体流程结束。

三、简单总结
总体来说InstructGPT不管在模型的结构上还是训练方式上都没有很大的创新,模型结构保持了GPT的传统结构,仅仅使用了transformer的解码器进行深度堆叠。训练方式上也是直接沿用了传统的强化学习的PPO算法。
InstructGPT最大的贡献是验证了强化学习对当前大模型的重要影响和意义,因为回顾近几年大模型的工作,无非就是两个方向:数据越来越大、模型越来越大。而强化学习属于很早就存在的算法,近几年有些冷门,没怎么受到重要,只是可能很多人都没有想到引入强化学习后可以对大模型带来这么巨大的影响,这是一个很有魄力的尝试。
希望我的分享对你的学习有所帮助,如果有问题请及时指出,谢谢~

















 1222
1222

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









