






Training language models to follow instructions with human feedback
论文相关信息:
2022.3.4 OpenAI NeurIps CCF A类



文章基本结构:
Abstract
1 Introduction
2 Related work
3 Methods and experimental details
3.1 High-level methodology
3.2 Dataset
3.3 Tasks
3.4 Human data collection
3.5 Models
3.6 Evaluation
4 Results
4.1 Results on the API distribution
4.2 Results on public NLP datasets
4.3 Qualitative results
5 Discussion
5.1 Implications for alignment research
5.2 Who are we aligning to?
5.3 Limitations
5.4 Open questions
5.5 Broader impacts
Acknowledgements
References
1、Introduction引言
通过训练语言模型按照用户意图行动,推动语言模型与用户的对齐
SFT+PPO算法最大化RM模型:使用RL方法对GPT-3进行微调,通过RLHF的标记数据和RM模型来使其遵循广泛的书面指令类别,从而实现对齐
标记器明显更喜欢InstructGPT的输出,而不是GPT-3的输出Labelers significantly prefer InstructGPT outputs over outputs from GPT-3.
InstructGPT模型在真实性方面优于GPT-3。InstructGPT models show improvements in truthfulness over GPT-3.
InstructGPT模型改善了有害性但不包括偏见性InstructGPT shows small improvements in toxicity over GPT-3, but not bias.
可以通过修改RLHF微调过程来最小化在公共NLP数据集上的性能退化。We can minimize performance regressions on public NLP datasets by modifying our RLHF fine-tuning procedure.
模型能泛化到训练数据外的标注者偏好——模型适用于没有产生任何训练数据的“留存”标注者的偏好。Our models generalize to the preferences of “held-out” labelers that did not produce any train- ing data.
公共NLP数据集不能反映我们语言模型的使用方式。Public NLP datasets are not reflective of how our language models are used.
InstructGPT模型在RLHF微调分布之外的指令上展现出了很好的泛化能力。InstructGPT models show promising generalization to instructions outside of the RLHF fine- tuning distribution.
InstructGPT仍然会犯一些简单的错误。InstructGPT still makes simple mistakes.
Overall—使用人类偏好微调大型语言模型显著提高其任务表现
2、Related work相关工作
对齐和从人类反馈中学习的研究。Research on alignment and learning from human feedback.
训练语言模型遵循指示可以提高下游性能。 Training language models to follow instructions.
评估语言模型的危害。Evaluating the harms of language models.
修改语言模型行为以减轻危害—数据过滤/阻止某些词汇/词嵌入正则化。Modifying the behavior of language models to mitigate harms.
3、Methods and experimental details方法和实验细节
3.1、High-level methodology高级方法—收集示范数据(SFT)+收集比较数据(RM)+优化策略(PPO)
3.2、Dataset数据集:SFT数据集+RM数据集+PPO数据集
3.3、Tasks任务:训练任务来源于标注者写的提示和API上提交的提示,目标是培养模型按照用户指令回应真实且无害
3.4、Human data collection人类数据收集:通过严格的标注者筛选,培养了能够根据任务需求,辨别有害输出的标注者团队,来训练和评估语言模型。
3.5、Models模型
T1、监督微调Supervised fine-tuning (SFT).
T2、奖励建模Reward modeling (RM).
T3、强化学习Reinforcement learning (RL).
基线Baselines.
3.6、Evaluation评估
API分布的评估Evaluations on API distribution.
公开NLP数据集的评估Evaluations on public NLP datasets.
4、Results结果
4.1、API分布的结果Results on the API distribution
我们的模型推广到“保留”标注员的偏好上,这些标注员没有产生任何训练数据。Our models generalize to the preferences of "held-out" labelers that did not produce any train- ing data.
公开的NLP数据集不能反映我们的语言模型的使用情况。Public NLP datasets are not reflective of how our language models are used.
我们认为我们的InstructGPT模型在两个方面优于FLAN和T0模型。We believe our InstructGPT model outperforms FLAN and T0 for two reasons
4.2、Results on public NLP datasets在公开的NLP数据集上的结果
与GPT-3相比,InstructGPT在毒性方面略有改善,但没有偏倚。InstructGPT shows small improvements in toxicity over GPT-3, but not bias.
我们可以通过修改RLHF微调过程来减少在公开的NLP数据集上的性能下降。We can minimize performance regressions on public NLP datasets by modifying our RLHF fine-tuning procedure.
4.3、Qualitative results定性结果
InstructGPT模型展示了对RLHF微调分布之外指令的有希望的泛化能力。InstructGPT models show promising generalization to instructions outside of the RLHF fine- tuning distribution.
InstructGPT仍然会犯简单错误InstructGPT still makes simple mistakes.
5、Discussion
5.1、Implications for alignment research对齐研究的意义
相对于预训练,增加模型对齐的成本性价比更高The cost of increasing model alignment is modest relative to pretraining
可知InstructGPT在我们不进行监督的设置中泛化了“按照指示”的能力We’ve seen some evidence that InstructGPT generalizes ‘following instructions’ to settings that we don’t supervise it in
降低对齐税—我们成功地减轻了我们的微调引入的大部分性能下降We were able to mitigate most of the performance degradations introduced by our fine-tuning
已在现实世界中验证了对齐技术的研究We’ve validated alignment techniques from research in the real world
5.2、Who are we aligning to?我们要对齐的对象是谁?
语言模型的最终行为受多个因素影响,包括模型本身、训练数据、调整方法,我们主要调整到标注者提供的偏好,但标注者代表性有限
5.3、Limitations局限性:基于有限代表性的标注者偏好进行训练和调整,模型存在不完全对齐和不完全安全的问题
5.4、Open questions开放问题:用对齐技术微调语言模型有利,但仍存在诸多开放问题和挑战需要解决
5.5、Broader impacts更广泛的影响:对齐技术不能解决安全问题,需要更完善的监管和安全机制
文章解读:
Abstract:

使语言模型变得更大并不会本质上使它们更擅长理解用户的意图。例如,大型语言模型可能生成不真实、有毒或对用户无帮助的输出。换句话说,这些模型与用户的意图不一致。在本文中,我们展示了一种通过使用人类反馈进行微调的方法,以在各种任务上将语言模型与用户意图对齐。我们首先从标签者编写的提示集和通过OpenAI API提交的提示开始,收集了一个标签者展示期望模型行为的数据集,然后我们使用这个数据集使用监督学习对GPT-3进行微调。然后,我们收集了模型输出的排名数据集,并使用人类反馈的强化学习进一步微调这个监督模型。我们将结果称为InstructGPT模型。在我们的提示分发的人工评估中,尽管参数仅为1.3B的InstructGPT模型的输出比175B的GPT-3更受欢迎,但InstructGPT模型在真实性方面有所改善,并减少了有害输出的生成,同时在公共NLP数据集上的性能退化最小。尽管InstructGPT仍然会犯一些简单的错误,但我们的结果表明,使用人类反馈进行微调是将语言模型与人类意图对齐的一个有前景的方向。
2015年的时候Google的照片服务将黑人的照片识别为Gorilla,导致了Google紧急将Gorilla这个词在模型中删除。

3年后,Google Photos将Gorilla这个词直接去掉了。

另外一个声音就是说训练一个特别大的模型,这样就不需要数据标注了,但是如果这样一条路走到底的话,算力总会有穷尽的时候;并且你的数据增长到一定程度后,可能仍然有覆盖不到的地方。这个时候在你想要模型拥有这个特性的地方适当的做一些人工标注,其实可能效果会更好。
1 Introduction
目前大语言模型存在的问题:

This is because the language modeling objective used for many recent large LMs—predicting the next token on a webpage from the internet—is different from the objective “follow the user’s instructions helpfully and safely”.
我们目前训练的模型的目标函数是预测来自互联网的文本上的下一个词(文字接龙),与我们想要的生成的模型的目标函数是不同的——follow the user’s instructions helpfully and safely(有帮助的并且安全的遵循人类的指令)。
所以模型真正的目标函数与我们想要的目标函数之间是存在差距的。

希望语言模型达到的目标:

InstructGPT的训练流程概述:

为什么用RLHF?
OpenAI作者是做强化学习出身的,并且后面的PPO强化学习算法也是作者中的其中一位做出来的,最终目的是让语言模型生成符合人偏好的答案,强化学习就是仿照人的。
训练过程:

step1: 假设问题为 Q1: explain the moon landing to a six year old 人工写的答案为 A1: some people want to the moon... ;以Q1为prompt输入到GPT-3中,A1为label进行有监督的fine tunne GPT-3模型 step2:通过openAI API选择一个更大的问题集,然后将问题依次送入到GPT-3中,GPT-3会输出多个答案,一个问题得到多个答案后,通过人工对这些答案进行排序,然后根据这些排序的问题答案对来训练一个奖励模型,输入问题及其答案,输出一个得分,最终要求奖励模型输出各个问题答案对的得分排序和人工标注的排序相同 step3:使用强化学习微调step1训练的GPT-3模型:输入一个问题,GPT3生成一个答案,将该问题答案对送入到step2训练好的奖励模型中得到一个得分,根据得分来优化GPT3模型使得GPT3模型输出的答案得分尽可能高
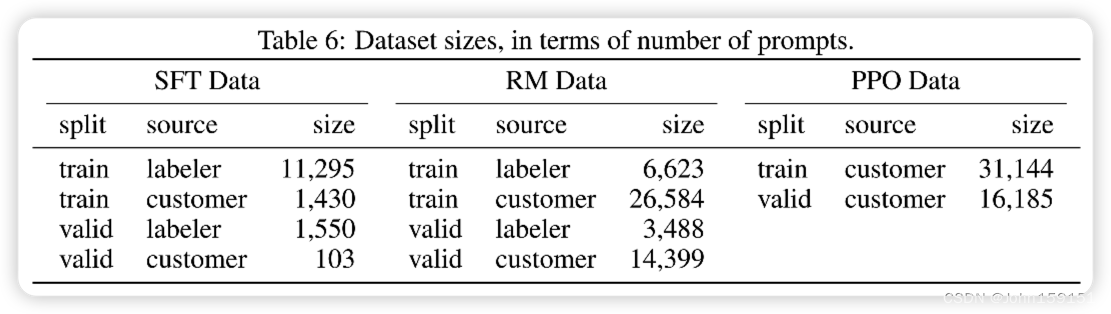
数据集大小:
SFT-13K-人工+API
RM-33K-人工+API
PPO-31K-API
是否一定需要step2强化学习这一步? 理论上如果step1这一步人工标注了足够多的数据,不需要强化学习,直接根据标注数据来训练应该是也能达到同样效果。但是这里考虑到step1中给定问题要求标注者写出所有的答案这种标注方式太难,标注成本很高,而step2这种判别式的标注方法显然简单很多,标注效率会大大提高,即同样的标注成本能够标注更多的数据,所以通过强化学习可以起到节约标注成本的作用。
技术要点:
1、 人工数据是怎么标注出来的?
2、排序的数据是怎么标注出来的?
3、RM模型怎么训练出来的?
4、有了RM模型后,怎样通过强化学习来训练?
主要结论:
Labelers significantly prefer InstructGPT outputs over outputs from GPT-3.
InstructGPT models show improvements in truthfulness over GPT-3.
InstructGPT shows small improvements in toxicity over GPT-3, but not bias.
We can minimize performance regressions on public NLP datasets by modifying our RLHF fine-tuning procedure.
Our models generalize to the preferences of “held-out” labelers that did not produce any training data.
Public NLP datasets are not reflective of how our language models are used.
InstructGPT models show promising generalization to instructions outside of the RLHF finetuning distribution.
InstructGPT still makes simple mistakes.
2 Related work
Research on alignment and learning from human feedback.
Training language models to follow instructions.
Evaluating the harms of language models.
Modifying the behavior of language models to mitigate harms.
3 Methods and experimental details

这个技术原本就有了,也是OpenAI之前的工作,只不过现在是在一个新的数据集上重新训练了一下。
数据集:
人工标注的要求:

简单:我们简单地要求标注员想出一个任意的任务,同时确保任务有足够的多样性。
•Few-shot:我们要求标注者提出一条指令,以及针对该指令的多个查询/响应对。
基于用户:我们在OpenAI API的等待列表应用程序中列出了许多用例。我们要求标注者提出与这些用例相对应的提示
有了这些数据就训练了第一个InstructGPT,然后将其放在了playground平台上,这样用户就会再次产生问题(对每个用户最多采用200个问题)。
训练集验证集测试集是根据用户ID来划分的,避免一个用户会问出类似的问题,出现在多个集里面,导致数据集有污染。
过滤了用户的隐私信息。

这是一个常见思路:
训练模型需要数据——一开始人工标注一些数据(但是这些数据肯定是与用户真正使用时候是有差距的)——训练一个模型出来,不需要多好(相当于测试版本)——发布出来让大家玩玩——得到更多数据。如此迭代。

产生三个数据集:
SFT-13K-人工+API
RM-33K-人工+API
PPO-31K-API
数据集Size:
用这个API的用户问的问题的分布以及示例:

数据来源:
招募了40个人:来自Upwork(美国一个招募合同工的网站),ScaleAI(数据标注公司 )

筛选人员标准:

3中提到的1-7Likert 评分(Likert scales)是一种常用的心理测量工具,用于量化个体对某一主题或问题的态度、观点和意见。
Likert 评分方法采用一种有序的量表形式,通常包括五个或七个等级,分别是“强烈同意”、“同意”、“中立”、“不同意”和“强烈不同意”。参与者需要在量表上选择一个最符合他们观点的选项。
标注网页:
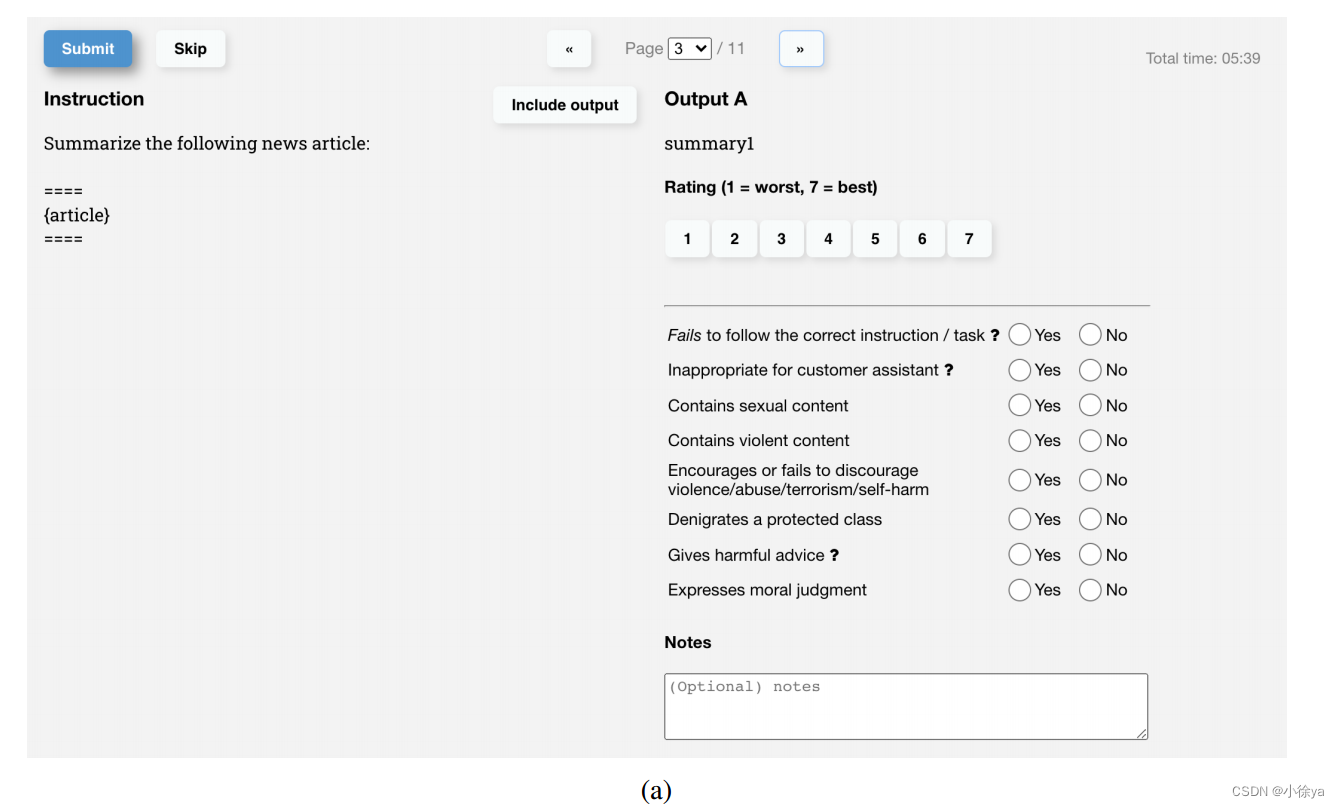

训练时候与评估时候标准不一致!
During training and evaluation, our alignment criteria may come into conflict: for example, when a user requests a potentially harmful response. During training we prioritize helpfulness to the user (not doing so requires making some difficult design decisions that we leave to future work; see Section 5.4 for more discussion). However, in our final evaluations we asked labelers prioritize truthfulness and harmlessness (since this is what we really care about)
尽管任务有二义性的存在,但是对于这个team而言,大概就是你觉得好的地方我觉得也不差。

模型:
SFT:

RM:
175B的模型LOSS会爆炸

为什么选择k=9而不是k=4?
损失函数:Pairwise Ranking Loss

最小化Loss等价于最大化RM
RL:
在强化学习中,模型叫做policy。

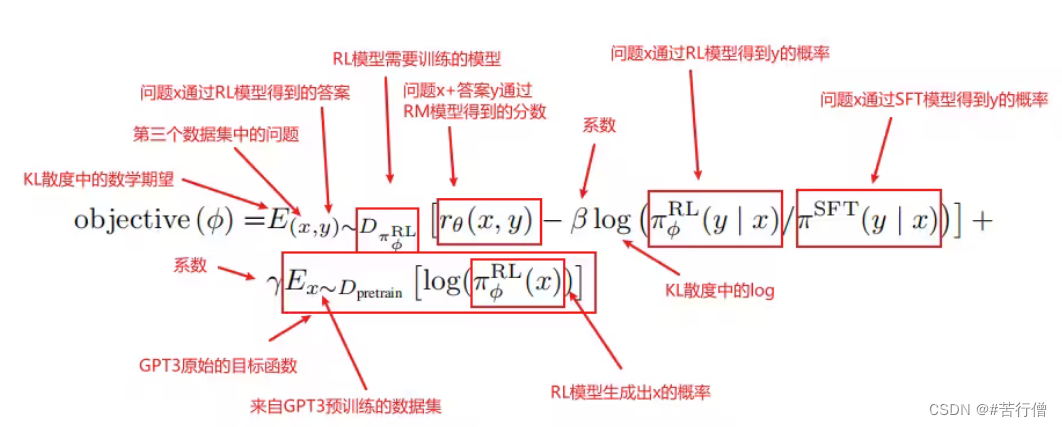
-
输入x是第三个数据集里的prompt,而输出y则是强化学习的SFT模型的输出。y会随着模型参数的更新而不一样,这里有区别与监督学习,监督学习中,训练多个epoch时同一个x对应的y是一样的,但强化学习中同样的x对应的y是会随着模型更新而变化的。
PPO:对上面这个函数做梯度下降
-
PPO的主要思想。 强化学习的模型称为策略模型,又称为策略。其中rθ是RM,为了确保RM打分不至于被过度优化,增加了个log项,那是KL散度,为了保证PPO学习出的强化学习SFT的预测不至于偏离原SFT模型的预测太多,因为RL就是用SFT模型初始化的。这就是PPO的主要思想。
-
语言模型预训练项。 另外地,InstructGPT在PPO的loss基础上加上了预训练损失,为了防止强化学习SFT模型只对打分这个任务过度拟合,导致泛化性能损失,所以加上了预训练语言模型的损失来确保模型在公开NLP数据集上的表现。加上了这一项,PPO就变为了PPO-ptx。
有了loss就能反向传播更新模型参数了。
KL散度:全称 Kullback-Leibler 散度,是一种用于度量两个概率分布之间相似性的指标。它来源于信息论,可用于衡量真实分布与拟合分布之间的差异。
为什么要训练这个r-setae?
人工标注的是排序而不是y(最佳答案)
给定当前的模型,生成多个输出,人类对于这些输出的排序
在每一次模型更新的时候,生成一些答案,找人来标顺序,再算梯度,对模型进行更新,如此迭代。r-setae就是来替代这个人的。
4 Results

1、本文主要做2方面的实验来证明RLHF的有效性: ①人工评测Output,打分维度如下;

②公开NLP数据集的评测,主要关注truthfulness,toxicity,bias;
人工评测Output实验结果
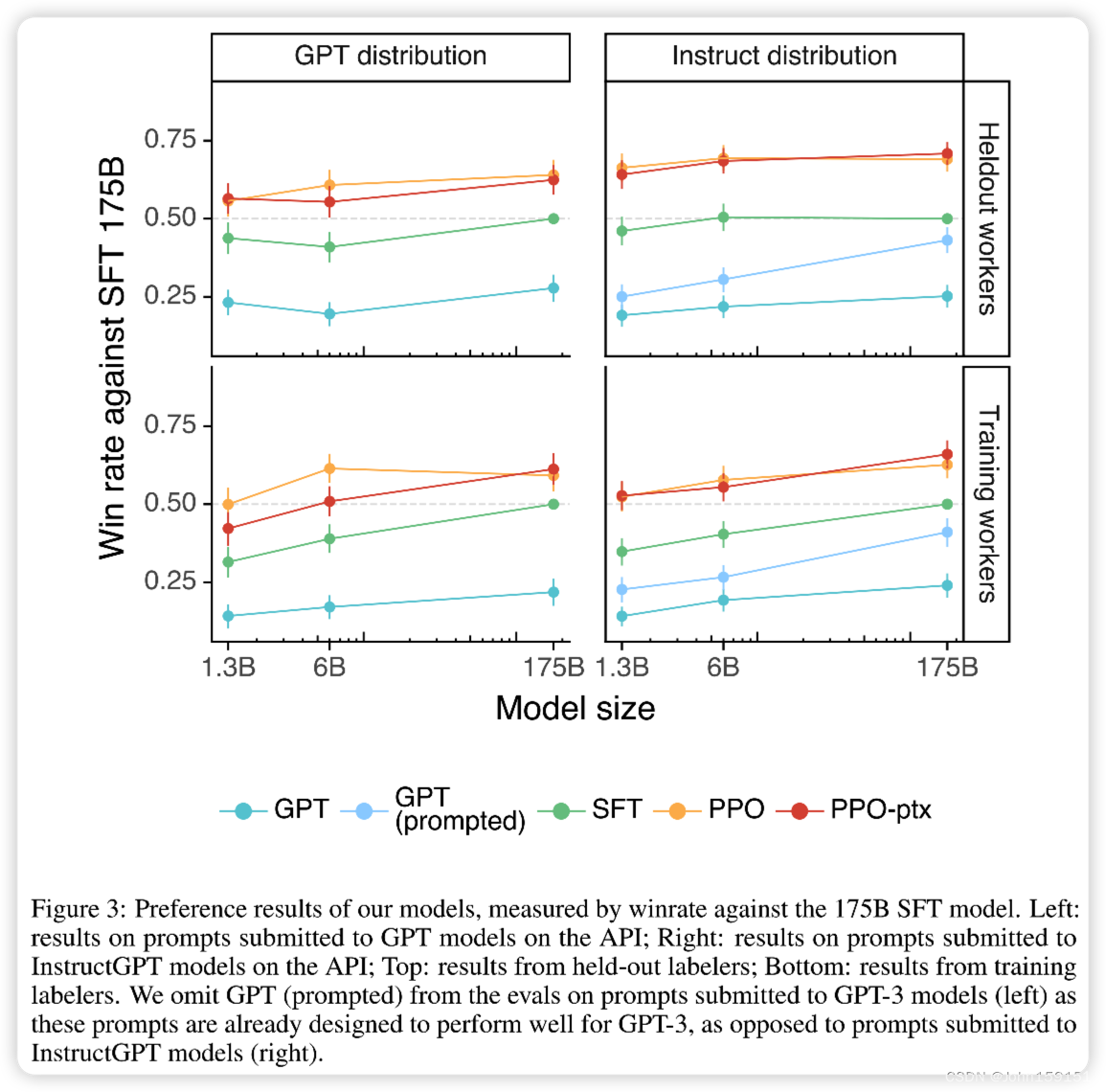
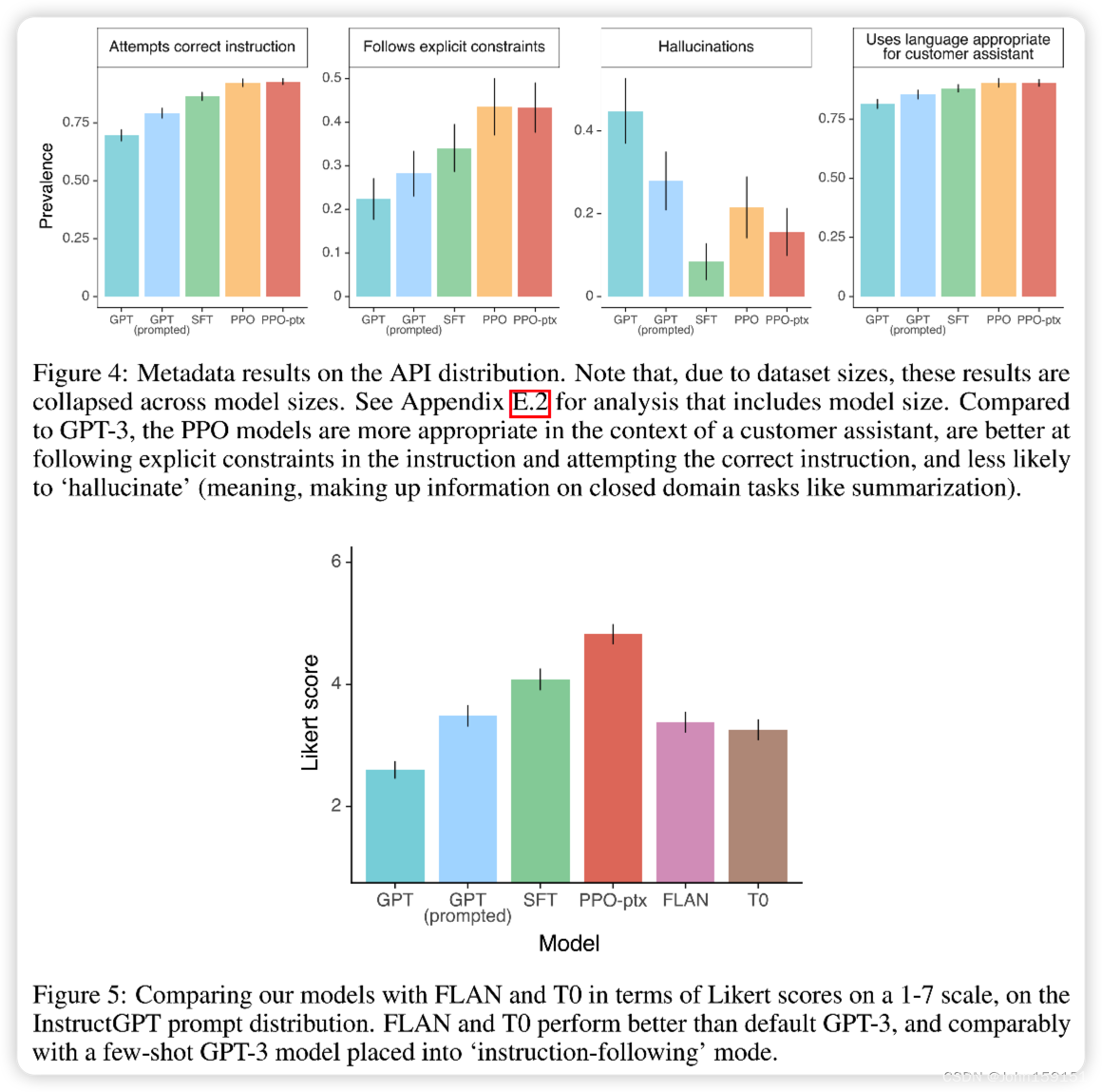
公开NLP数据集的实验结果
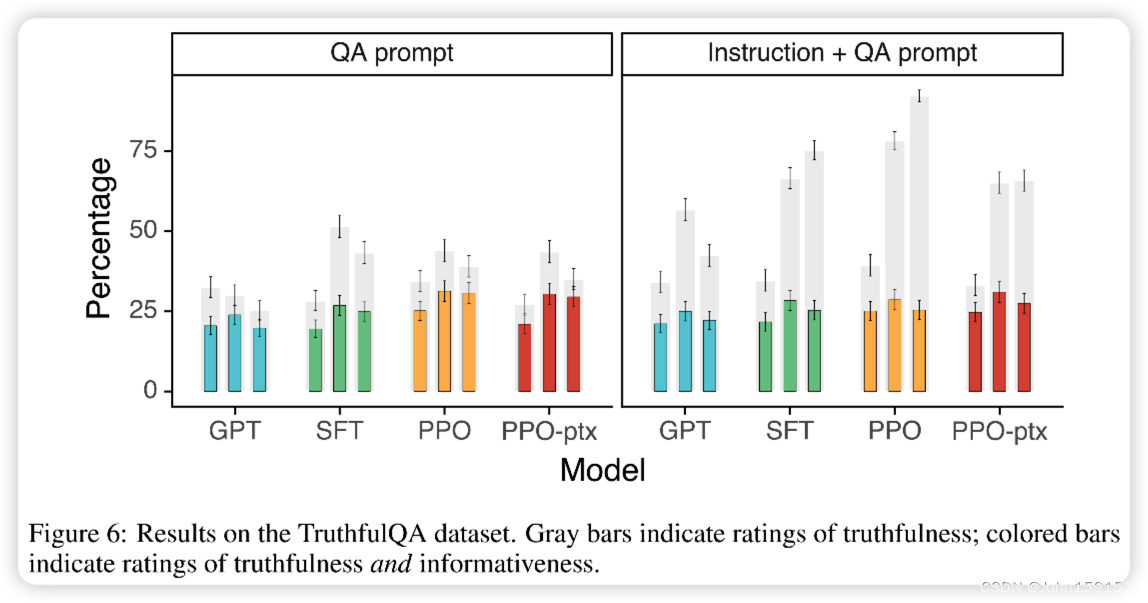

2、作者对InstructGPT在其泛化性上的表现感到吃惊,尤其在非英语任务上和coding任务上,这两部分在训练数据集中占得比例很少,却也能表现的很好;
3、InstructGPT常见的错误 ①问题中带有错误的前提,模型会将这个前提错误地认为是真的;-->训练集中没有错误的前提数据; ②回答过于转弯抹角,显示出模型在乱说话;-->可能跟RM数据集的标注有关,乱说话比不说话得分高; ③问题含有较多限制条件,会导致模型效果下降; 作者提出可以加入对抗性数据集,能降低这些错误。
4、本文对于alignment的一些经验 ①相对于pre-train,alignment的cost不多且可接受; ②InstructGPT的泛化性强,比如在非英语任务上和coding任务上; ③可以降低Fine-tune带来的效果降低问题; ④alignment在实际应用上验证有效;
5、InstructGPT的表现受限于标注者的观点和价值取向;
5 Discussion


Limitations:


后续研究计划:

比较也不一定是提供对齐信号的最有效方式。
![]()
主要是怎么定义Alignment,本文是通过helpful,honest,harmless三个层面来体现Alignment。
总结:
InstructGPT就是在GPT-3的再训练中增加了人工标注数据,将标注数据与强化学习相结合,使得模型的生成结果更符合人类的期望,也即论文中的提到的使模型更有帮助性,同时由于人工标注的数据在真实性、无害性方面有保证,因此一定程度上帮助模型生成具有真实性和无害性的内容。














 2712
2712











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









