







目录
2.1改变针对于每个样本的损失函数:广义Wasserstein Dice损失
Title:Generalized Wasserstein Dice Score,Distributionally Robust Deep Learning,and Ranger for brain tumor segmentation:BraTS 2020 challenge
摘要-Abstract
训练深度神经网络包含4个主要成分的优化问题:即深度神经网络的设计,每个样本的损失函数,总体的损失函数,以及优化器。最近对于脑肿瘤分割方法的开发,往往只是关注了神经网络的架构设计,而对于其他三个方面关注的较少。本文不对网络进行进一步的修改使用3D UNet,但尝试使用非标准的单样本损失函数,广义 Wasserstein Dice损失,非标准总体损失函数,对应于分布鲁棒优化,以及一个非标准优化器Ranger(广义Wasserstein Dice损失是每个样本的损失函数,它允许利用BraTs中标记的肿瘤区域的层次结构。分布鲁棒优化是经验风险的最小化概括,它解释了数据集中存在代表性不足的子域。Ranger是广泛使用的Adam优化器的推广,其在小批量和嘈杂的标签时更稳定)
方法:改变深度神经网络优化的三个主要成分
深度神经网络的训练包括以下优化问题,用公式表示为
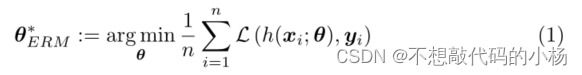
其中h是参数为的深度神经网络,L是平滑的逐像素损失函数,(xi,yi)是训练数据集。Xi代表输入的四种模态数据,Yi是真实手动风格标签
2.1改变针对于每个样本的损失函数:广义Wasserstein Dice损失
广义的Wasserstein Dice Loss是Dice Loss的泛化,用于多类分割,可以利用层次结构。
当体素的标记不明确或神经网络难以正确预测时,广义的Wasserstein Dice损失旨在支持语义上更合理的错误。形式上,ground-Truth类概率图p和预测的类概率图之间的广义Wasserstein Dice损失定义为
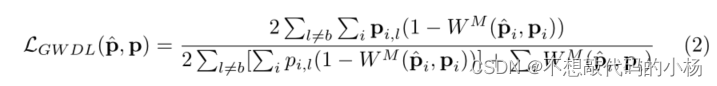
其中是在体素i处预测的
和真实标签Pi之间的Wasserstein距离。M是距离矩阵,将最大标签距离设置为1,对应于背景类与所有其他类之间的距离。类之间的距离反映了肿瘤区域,肿瘤类之间的距离都小于1,因为它们具有更多的共同点。广义的Wasserstein Dice损失允许通过考虑所有类间关系同时优化BraTS数据集中标记的重叠区域和非重叠区域
2.2改变优化问题:分布鲁棒优化(DRO)
DRO旨在通过明确考虑训练数据集分布中的不确定性来提高神经网络的泛化能力。例如在BraTs数据集中,我们不知道不同的的数据采样中心是否具有相同的表示。这可能导致深度神经网络在训练数据集中代表性不足的子域上表现不佳。DRO模块旨在通过鼓励神经网络在整个训练数据集上更一致的执行来缓解这个问题。
具体来说,DRO由最大值-最小化问题定义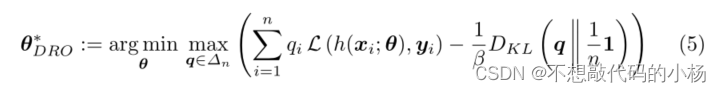
在式子中引入了一个新的未知的概率向量参数q,1/n1代表均匀概率向量,Dkl是KL散度。式子中的Dkl(...)是一个正则化项,它度量q和均匀概率向量1/n1之间的不相似度,对应于给每个样本分配相同的权重1/n。
2.3更改优化器:Ranger
Ranger是一种用于训练深度神经网络的优化器,它由深度学习优化领域的两个最新贡献组合而成RAdam和lookhead优化器。
RAdam是Adam优化器的改进版,旨在减少Adam在训练早期自适应学习率的方差,Lookhead是指数移动平均法的推广,旨在加速神经网络的其他优化器的收敛。Lookhead需要为深度神经网络的权重保留两组值。一组快速权重,一组慢速权重。LookHead可以看做是一个可以与任何深度学习优化器结合的包装器。
2.4深度神经网络的集成
本小节主要讨论使用不同的深度学习优化算法对分割进行集成的作用。不同的深度学习优化算法可以提供相似的良好分段,它们可能有不同的偏差,并会犯不同的错误。在这种情况下,不同模型的集成可以使优化方法的选择导致的不一致平均化,从而提高分割性能和鲁棒性。
总结:本文使用分布式鲁棒优化,广义Wasserstein Dice Loss和Ranger 优化器可以提高nnUnet的分割平均性和鲁棒性,这三个特征是互补的,通过整合三个神经网络实现了最佳分割性能。















 563
563











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









