







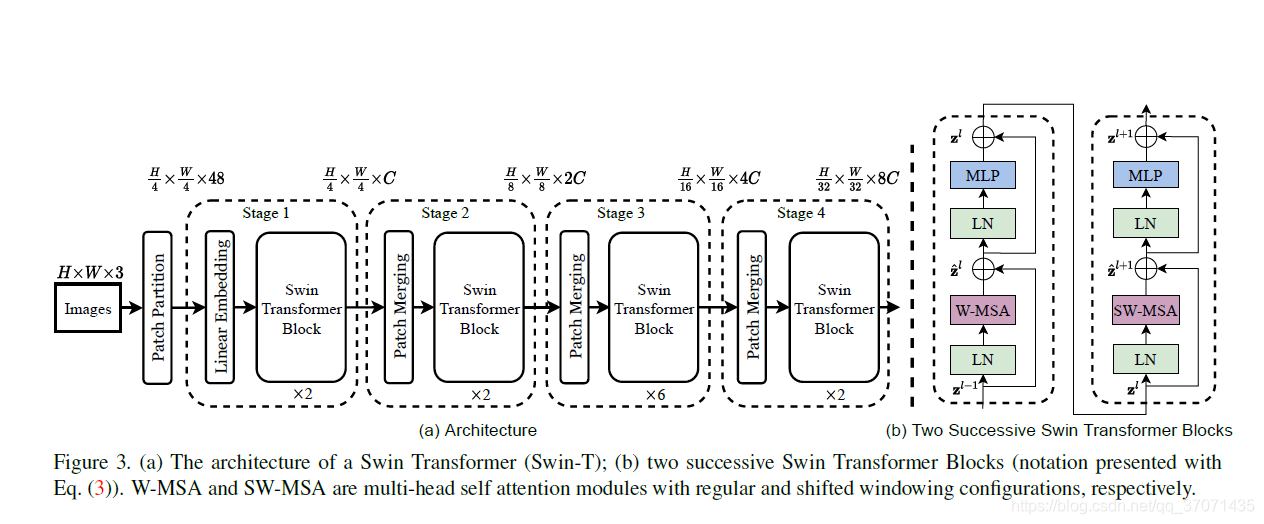
Overall Architecture
Image
输入image的大小为三维矩阵:H W 3。H为Height,W为Width,3为通道channel,这里指的是RGB。图中只以一个image为例,也就是batch_size = 1。
Patch Partition
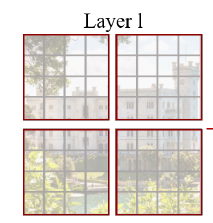
一张图片读入后表示为像素矩阵,需要先对图片进行patch partition处理,将图片的最小单位从像素转变为patch。论文中所给的示例为一个patch由4*4个pixel构成,即patch partition模块用包含4*4个像素的patch来对像素矩阵进行分割,并一个patch中的像素值合成一个向量。输入的像素矩阵经过处理后变为![]() 的三维矩阵,其中H/4 * W/4表示patch的数量,48为channel,由3*4*4得来。
的三维矩阵,其中H/4 * W/4表示patch的数量,48为channel,由3*4*4得来。
Linear Embedding
A linear embedding layer is applied on this raw-valued feature to project it to an arbitrary dimension(denoted as C).C default 96.
代码中PatchEmbed()类中包含了Patch Partition 和Linear Embedding两个模块。具体代码含义见下面注释。
class PatchEmbed(nn.Module):
r""" Image to Patch Embedding
Args:
img_size (int): Image size. Default: 224.
patch_size (int): Patch token size. Default: 4. 4 pixel
in_chans (int): Number of input image channels. Default: 3. RGB
embed_dim (int): Number of linear projection output channels. Default: 96.
norm_layer (nn.Module, optional): Normalization layer. Default: None
"""
def __init__(self, img_size=224, patch_size=4, in_chans=3, embed_dim=96, norm_layer=None):
super().__init__()
#img_size -> tuple(img_size,img_size) 即(224,224)
img_size = to_2tuple(img_size)
patch_size = to_2tuple(patch_size)
patches_resolution = [img_size[0] // patch_size[0], img_size[1] // patch_size[1]]
self.img_size = img_size
self.patch_size = patch_size
self.patches_resolution = patches_resolution
#图片中的patch个数
self.num_patches = patches_resolution[0] * patches_resolution[1]
#input channel default RGB:3
self.in_chans = in_chans
#output channel
self.embed_dim = embed_dim
#in_chans:3 out_chans:96 即输入一个图片的三个通道 经过4*4的卷积核和步长为4后输出channel为96
self.proj = nn.Conv2d(in_chans, embed_dim, kernel_size=patch_size, stride=patch_size)
#默认经过embedding后进行标准化norm layer
if norm_layer is not None:
self.norm = norm_layer(embed_dim)
else:
self.norm = None
def forward(self, x):
# batch channel height width
B, C, H, W = x.shape
# FIXME look at relaxing size constraints
#判断输入图片格式是否符合模型
assert H == self.img_size[0] and W == self.img_size[1], \
f"Input image size ({H}*{W}) doesn't match model ({self.img_size[0]}*{self.img_size[1]})."
#将图片进行embed flatten将数组从括号中的维度开始将后面的所有数降为一维
# 这里x为B C PH PW 4维
#经过flatten变为B C PH*PW 3维 再经过transpose调换维度 变为B PH*PW C
x = self.proj(x).flatten(2).transpose(1, 2) # B Ph*Pw C
#标准化
if self.norm is not None:
x = self.norm(x)
return x
#理论计算复杂度
def flops(self):
#用patch的数量来进行计算
Ho, Wo = self.patches_resolution
# 图片patch的数量 网络输入输出通道 每个patch内含有的pixel
flops = Ho * Wo * (self.embed_dim * self.in_chans) * (self.patch_size[0] * self.patch_size[1])
#如果未进行标准化 则再加上
if self.norm is not None:
flops += Ho * Wo * self.embed_dim
return flopsPatch Merging
实现了patch合并,使得channel*4,在经过卷积网络进行降维,使得channel/2。
The first patch merging layer concatenates the features of each group of 2*2 neighboring patches,and applies a linear layer on the 4C-dimensional concatenated features.This reduces the number of tokens by a multiple of 2*2 = 4(2*downsampling of resolution),and the output dimension is set to 2C.
class PatchMerging(nn.Module):
r""" Patch Merging Layer.
Args:
input_resolution (tuple[int]): Resolution of input feature. feature map的size
dim (int): Number of input channels.
norm_layer (nn.Module, optional): Normalization layer. Default: nn.LayerNorm
"""
def __init__(self, input_resolution, dim, norm_layer=nn.LayerNorm):
super().__init__()
self.input_resolution = input_resolution
self.dim = dim
#input channel:4*dim output channel:2*dim 降维
self.reduction = nn.Linear(4 * dim, 2 * dim, bias=False)
self.norm = norm_layer(4 * dim)
def forward(self, x):
"""
x: B, H*W, C
"""
H, W = self.input_resolution
B, L, C = x.shape
#检验输入是否符合模型
assert L == H * W, "input feature has wrong size"
#判断高 宽是否为偶数
assert H % 2 == 0 and W % 2 == 0, f"x size ({H}*{W}) are not even."
#reshape
x = x.view(B, H, W, C)
#0::2 表示从0开始step为2,一直取完
x0 = x[:, 0::2, 0::2, :] # B H/2 W/2 C
x1 = x[:, 1::2, 0::2, :] # B H/2 W/2 C
x2 = x[:, 0::2, 1::2, :] # B H/2 W/2 C
x3 = x[:, 1::2, 1::2, :] # B H/2 W/2 C
#cat为接合张量 -1表示最内侧的那一维 如0,1,2,3 则-1表示3 这里表示xi张量按照C这一维度进行接合
x = torch.cat([x0, x1, x2, x3], -1) # B H/2 W/2 4*C
x = x.view(B, -1, 4 * C) # B H/2*W/2 4*C
# 标准化
x = self.norm(x)
x = self.reduction(x)
return x
#一些额外的信息
def extra_repr(self) -> str:
return f"input_resolution={self.input_resolution}, dim={self.dim}"
#计算复杂度
def flops(self):
H, W = self.input_resolution
flops = H * W * self.dim
flops += (H // 2) * (W // 2) * 4 * self.dim * 2 * self.dim
return flops
Swin Transformer Block
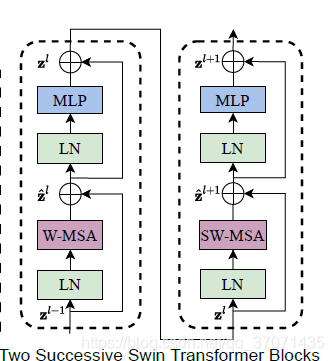
LN LayerNorm
A LayerNorm layer is applied before each MSA module and each MLP,and a residual connection is applied after each module.
MLP Muti-Layer Perception
就是一个两层fc网络
class Mlp(nn.Module):
"""
Muti-Layer Perception ,MLP
就是一个两层fc网络
in_features:
hidden_features:
out_features:
act_layer: activation function
"""
def __init__(self, in_features, hidden_features=None, out_features=None, act_layer=nn.GELU, drop=0.):
"""
GELU(x)=x∗Φ(x)
"""
super().__init__()
#若未输入out_features hidden_features则输入输出维度一样
out_features = out_features or in_features
hidden_features = hidden_features or in_features
#两个fc网络
self.fc1 = nn.Linear(in_features, hidden_features)
self.act = act_layer()
self.fc2 = nn.Linear(hidden_features, out_features)
#随机赋0 防止过拟合
self.drop = nn.Dropout(drop)
def forward(self, x):
x = self.fc1(x)
x = self.act(x)
#随机赋0
x = self.drop(x)
x = self.fc2(x)
x = self.drop(x)
return xW-MSA and SW-MSA
W-MSA and SW-MSA are multi-head self attention modules with regular and shifed windowing configurations,respectively.
这里的multi-head self attention 请见其他文章。下面主要介绍window_partition,shifted window partition and window_attention
这一部分借鉴
 最低0.47元/天 解锁文章
最低0.47元/天 解锁文章



















 709
709

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











