







1 网络的前馈方式
深度前馈神经网络,简称前馈神经网络,指的是具有前馈特征的一类神经网络模型。最具有代表性的是多层感知机(MLP)模型。
前馈神经网络模型是向前的,在模型的输出和模型本身不存在链接,也就不构成反馈。当然前馈神经网络也可以被扩展成包含反馈链接的循环网络(RNN)。
前馈神经网络实现了统计与泛化的函数近似机。
神经网络模型中相邻两层单元键的连接方式分为:
- 全连接方式:网络当前层的单元与网络上一层的每个单元都存在连接。
- 稀疏连接方式:网络当前层的单元只与网络上一层的部分单元存在连接。
全部使用全连接方式的网络,通常称为全连神经网络。MLP是一个全连神经网络。
2 向前传播算法:TensorFlow矩阵乘法实现
计算向前传播的结果需要3部分信息:神经网络的输入+神经网络的连接结构+每个神经元中的参数。
import warnings
warnings.filterwarnings("ignore")
import tensorflow as tf
# 输入。参与矩阵相乘运算,需要直接(shape=)或间接指明矩阵形状
x = tf.constant([0.9, 0.85], shape=[1, 2])
# 设置权重变量
w1 = tf.Variable(tf.constant([[0.2, 0.1, 0.3], [0.2, 0.4, 0.3]],
shape=[2, 3], name="w1"))
w2 = tf.Variable(tf.constant([0.2, 0.5, 0.25], shape=[3, 1], name="w2"))
# 偏置项参数
b1 = tf.constant([-0.3, 0.1, 0.2], shape=[1, 3], name="b1")
b2 = tf.constant([-0.3], shape=[1], name="b2")
# 初始化全部变量
init_op = tf.global_variables_initializer()
a = tf.matmul(x, w1)+b1
y = tf.matmul(a, w2)+b2
with tf.Session() as sess:
sess.run(init_op)
print(sess.run(y)) # [[0.15625]]
3 激活函数
如果网络中每个神经元的输出为所有输入的加权和,那最后的结果将是整个神经称为一个线性模型。将每个神经元的输出通过一个非线性函数,那么整个神经网络的模型也就不再是线性的了。这个非线性的函数我们通常称之为“激活函数”。
【深度学习】(二)神经网络:激活函数、MNIST
tensorflow中常用的激活函数
a2 = tf.nn.relu(tf.matmul(x, w1)+b1)
y2 = tf.nn.relu(tf.matmul(a2, w2)+b2)


线性模型加入激活函数解决线性不可分问题。用于划分区域的白色隔离边不再是一条直线,而是组成了一个封闭的图形。
4 多层网络解决异或运算
XOR函数(逻辑异或)对两个二进制值进行运算,恰好有一个1时返回1。
Exclusive or数据集中样本分布符合异或运算规则,坐标同为正/负蓝色;坐标值一正一副黄色。
单层神经网络无法模拟异或运算功能

使用含隐藏层的网络解决异或问题
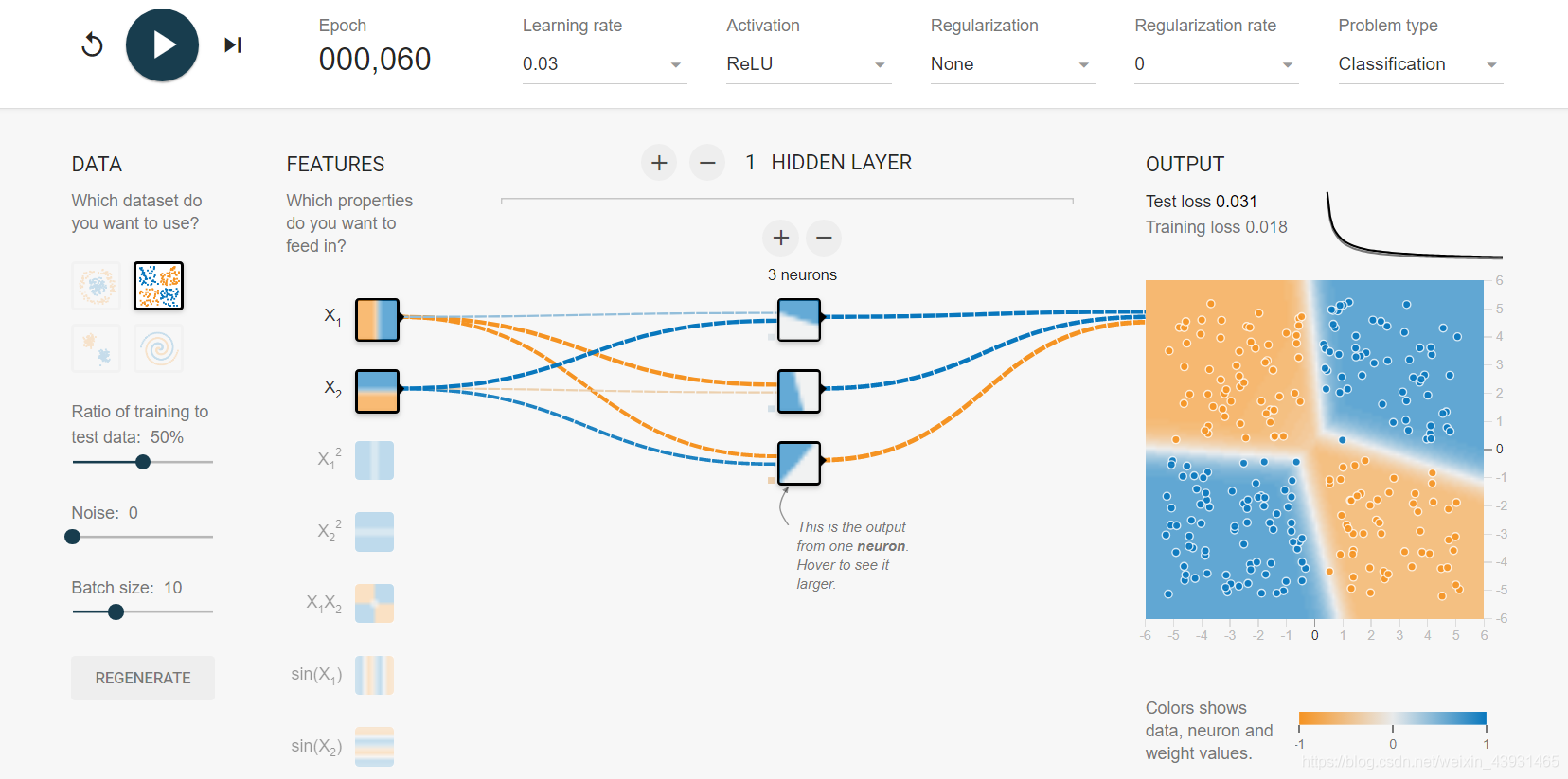
在隐藏层的每个单元中都有了颜色区域的划分。这些隐藏单元可以被认为是从输入特征中抽取的一些更高维特征,网络组合这些提取出的特征来完成具体的功能。
5 损失函数
损失函数(Loss)用来描述对问题的求解精度(预测答案和真实答案之间的距离)。Loss越小,偏差越小,模型越精确。
两个经典损失函数:交叉熵损失函数;均方差损失函数。
5.1 交叉熵损失函数
TensorFlow没有将交叉熵损失的过程单独封装到一个函数里,但是提供了一些可以平装成交叉熵损失的函数。
import warnings
warnings.filterwarnings("ignore")
import tensorflow as tf
a = tf.constant([1.0, 2.0, 4.0, 8.0])
with tf.Session() as sess:
print(tf.clip_by_value(a, 2.5, 6.5).eval()) # 限定数值范围。[2.5 2.5 4. 6.5]
print(tf.log(a).eval()) # 依次求取对数。[0. 0.6931472 1.3862944 2.0794415]
print(tf.reduce_mean(a).eval()) # 矩阵中元素求和后计算平均值。3.75
# 交叉熵损失函数
cross_entropy = -tf.reduce_mean(y_*tf.log(tf.clip_by_value(y, 1e-10, 1.0)))
其中y_代表标签保存的真实答案向量。
方法:
- eval()函数:用来执行一个字符串表达式,并返回表达式的值。
- clip_by_value():将一个张量中的数值限定在一个给定的范围。通过设置参数clip_value_min和参数clip_value_max。
- log():依次求取对数。
- reduce_mean() :矩阵中元素求和后计算平均值。
"*"和matmul()函数的区别:*相乘指的是矩阵中对应元素的相乘,而matmul()函数实现的是数学中的矩阵相乘。
5.2 交叉熵和Softmax回归
Softmax回归用于将神经网络向前传播得到的结果编程概率分布提供给交叉熵损失函数。
TensorFlow提供了nn.softmax()函数来实现Softmax回归。
并且提供了交叉熵和softmax函数的封装统一:cross_entropy = tf.nn.softmax_cross_entropy_with_logits(y, y_)
模拟二元线性回归问题

5.3 自定义损失函数
使用损失函数的目的是为了描述网络给出的预测答案和真实答案之间的“距离”,基于此loss = tf.reduce_sum(tf.where(tf.greater(y, y_)*a, (y_-y)*b))。其中a,b是常量系数。
greater()函数输入两个维度相同的张量,比较第一个张量和第二个张量中相同位置处每一个元素的大小。若第一个张量大返回True,否则False。
where()函数有三个参数,第一个为选择条件根据,布尔型,为True时函数选择第二个参数中相同位置处的值,否则选择第三个参数中相同位置处的值。
例如,令一件商品的成本价为5元,其利润为2元。
每少预测一个商品就少挣2元,多预测一个就损失5元。此时a=2,b=5。f(y,y’)在y>y’时等于a(y-y’),否则为b(y’-y)。















 4613
4613











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









