







换入换出
- 即:虚拟地址个数大于物理内存时,就要换入换出(比如 32 位系统,物理内存只有 2G,那么就要换入换出,因为分配了 4G 个存储单元(1M 个页),但只有 2G 个物理存储单元(500K 个物理页)
- 如果虚拟内存都可以映射到物理内存上,那么虚拟内存这个思想就没有存在的必要了。
- 这个换入换出时机发生在缺页中断,之所以会缺页是因为要 get_new_page 没有时,会选物理页换入磁盘,然后将该物理页对应的页表项标志为不在内存(页表项最后一位),那么 MMU 在对虚拟地址进行 IO 时,就会有缺页异常,从而导致缺页中断,这时会根据缺页的物理地址,再把缺的页换入内存,然后修改该页对应的页表项,改为新的物理页号
换入换出
-
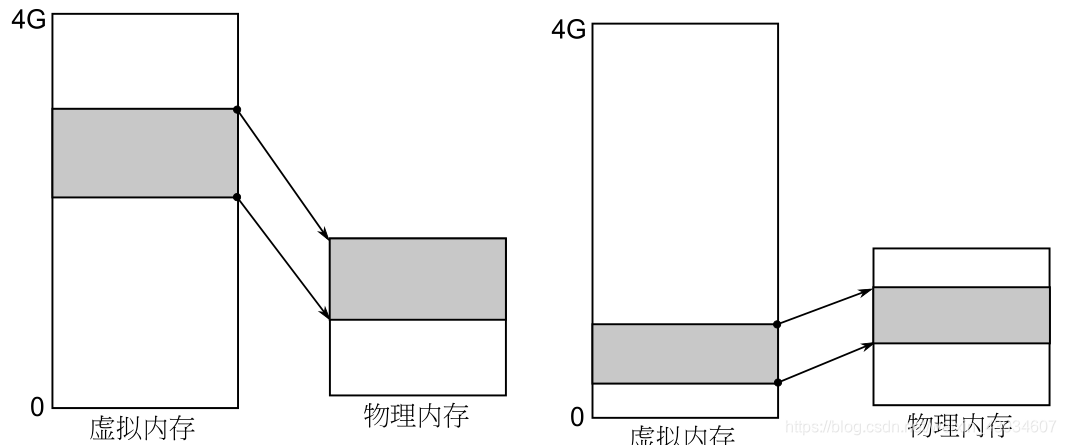
虚拟内存就是操作系统给进程提供的一个规整的其长度总为 4G(32 位机器)的地址空间,用户可以随意访问这个空间中的任何一个地址(即操作系统给了段基值,然后基址寻址的范围是4G)。但是由于实际的物理内存可能比 4G 要小,所以 4G 的虚拟内存不可能全部映射到物理内存上,这就会产生换入换出场景。
-
首先访问左图中阴影部分的那段虚存区域,虚存区域和物理内存建立了关联,现在又要访问右图阴影部分的那段虚存区域,由于物理内存空间不足,需要首先将物理内存中的某些关联释放掉(换出),在物理内存中腾出的地方上和右图中的虚存区域建立关联(换入)。
页面换入实现
请求调页
- 在MMU 发现虚拟页面在页表项中的有效位为 0 时开始,会向CPU 发出缺页中断。操作系统进行内存换入
- 这个中断处理中操作系统会去磁盘上找到这个虚拟页,并将这个虚拟页从磁盘上读进来。当然在读进来之前先要找到一个空闲的物理内存页框,再将那个虚拟页读到空闲页框以后,虚拟页面就和物理页框建立关联了,再更新页表来记下这个映射关系。
- 中断处理返回以后,会重新执行那条被中断的指令,因为刚才执行指令的中途发生了中断。所以执行指令时,再去查段表、页表,显然都会是有效的,可以顺利得到物理地址,指令顺利执行,换入过程全部完成。
实现的代码从缺页中断处理程序开始
- 在系统启动的中断初始化中有这样的设置,14 号中断就是缺页中断,数字 14是由计算机硬件电路决定的,除了查手册以外没有什么可说的
void trap_init(void)
{
set_trap_gate(14, &page_fault);
}
page_fault
page_fault:
# 首先取出导致页面错误的类型,要判断页面是没有映射呢还是越权读写。
# 这个错误类型会被压到内核栈中,命令 xchgl %eax,(%esp) 会将这个错误类型取出来赋给 EAX 寄存器
xchgl %eax,(%esp)
# CR2 寄存器中存放着另一个非常重要的信息 出现内存读写错误的虚拟地址,如果是缺页,CR2 中存放的就
# 是发生缺页时的虚拟地址,进而知道到底缺了哪个虚拟页。
movl %cr2, %edx
# 给后面的 call do_no_page 传递参数
pushl %edx
pushl %eax
# 根据寄存器 EAX 的值来决定到底如何处理这个中断
testl $1, %eax
jne 1f
# 对应缺页
call do_no_page
jmp 2f
# 对应写保护,即写一个只读页,上一章论述的写时复制就是靠这个函数来处理的
1: call do_wp_page 2:
······
iret
do_no_page(页换入的核心工作)
// 参数 address就是用栈传进来的出现缺页的虚拟地址。
void do_no_page(unsigned long error_code, unsigned long address)
{
// 算出被换出页的索引(页目标和页表的索引),然后找到页表项
address &= 0xfffff000;
// 获得空闲物理内存页框,在 mem_map 数组中找到一个值为 0 的项
page = get_free_page();
// 启动磁盘读写来读取虚拟页面的内容
bread_page(page, current->executable->i_dev, nr);
// 用来填写页目录项和页表项,完成映射
put_page(page, address);
}
页面换出算法
页面换出
- get_free_page 需要在物理内存中找到一个空闲页框,但这个空闲内存页框不一定总能找到。
- 所以更符合实际的做法应该是,如果能找到空闲物理内存页框就直接使用,否则就要从现有的已映射物理内存页框中换出一页。
评价一个换出算法优劣的指标
- 缺页次数作为评价指标,因为页面换出是请求调页中的一个基本环节,尽量少的页面换入会提高请求调页的性能(缺页处理的代价很大,要读写磁盘)。
常规算法
FIFO 页面置换/淘汰算法
- FIFO 是选择最先进入的页面淘汰
OPT 淘汰算法
- 淘汰在未来最远才使用的页面,即最优页面淘汰算法,因为选择未来最远使用的页面进行淘汰是最明智的选择
- 虽然 OPT 页面淘汰算法是最好的页面淘汰算法,导致最少的缺页次数,但是 OPT 算法却有一个很大的缺陷:OPT 算法需要知道未来的页面访问情况。通常,我们是不可能知道未来要访问哪个虚拟地址的
LRU 页面淘汰算法
- 淘汰在历史上最长时间没被访问的页面
- 和 OPT 的结果差不多,因为程序局部性原理
LRU 算法实现
-
方案一:给每个页面打上时间戳以记录页面访问情况,缺页时选择时间戳最小的页面淘汰。
-
方案一存在的问题:时间戳的更新和维护太麻烦了。
- 首先需要弄明白时间戳信息应该存放在哪里。通常都要放在该虚拟页对应的页表项上,但时间戳的值可能会很大,造成页表长度增大;即使页表项再大,也可能出出现时间戳溢出的情况,时间戳溢出时又该怎么判断哪一页最近更少使用呢?
- 更为严重的问题,每次页面淘汰时都要比较页表项中的时间戳,内存中会存放很多虚拟页面,这个比较算法的代价会很大。可能需要使用一些复杂的数据结构,如用堆来帮助系统尽快找到时间戳最小的页面,但这样的数据结构维护代价太大,且每次页面访问时都需要维护。
-
方案二:页码栈也可以用来实现 LRU
- 想法很简单,每次访问某个虚拟页面时,就将这个页面浮动到栈顶。
- 这样栈中的页面就具有这样的特点:靠近栈顶的页面就是最近经常访问的,而被压在栈底的页面就是最近很少使用的。显然,采用页面栈以后,每次虚拟页面访问都要调整页面在栈中的位置;如果出现了缺页,就选择位于栈底的那个页面进行淘汰。
- 页码栈可以采用指针链表数据结构,这样在页码栈修改时,只需要修改 O(1) 数量的指针即可。
-
方案二问题:工作效率还是低
- 从算法角度,O(1) 的算法大概是我们能给出的最漂亮的算法了,但即使这个 O(1) 算法只造成了几次指针读写,但每次页面访问都要跟着这几次指针读写,即每次地址访问都要额外伴随几次内存访问,内存的读写效率会降低很多,整个计算机系统的工作效率也会降低很多。
clock 算法
分析总结上面给出的两种 LRU 算法的精确实现 时间戳算法和页码栈算法,可以得出这样一些结论:
- (1)要实现 LRU 必须用信息来记录页面使用情况,这样才能找到最近最少使用的页面进行淘汰,相应的需要在每次地址访问时进行信息维护。
- (2)如果用软件方式来维护这个页面访问信息,造成每次地址访问又额外增加多次地址访问的情况,严重降低内存使用效率。最好能用硬件实现来维护这一信息,这和采用 MMU 进行地址翻译的想法是一致的。
- (3)因为每次虚拟页面访问都是从 MMU 通过地址翻译找到页表项开始的,所以可不可以也将这个记录虚拟页面使用情况的信息记录在页表项中?看起来可以,但不应该存放如时间戳这样复杂的数,是否可以在页表项中存放一个很简单的数来近似时间戳,然后根据这个简单的数来近似判断“最近最少使用”。
clock 算法有很多变形,但所有 clock 算法的基础都是页表项中一个近似时间戳的信息访问位:
- 用一位二进制数 0、1 来近似时间戳,如果页面被访问了,就将这一位设置为 1,所以这一位通常被称为是访问位
SCR 算法
- 首先将分配给进程的所有页框(即页表项)组织成环形线性表,产生缺页时,就从当前的线性表指针(一直停在上一次缺页处理完以后的位置)处开始进行环形扫描
- 如果扫描到的虚拟页面其 R 位为 1,则将 R 位修改为 0,指针向后移动;
- 如发现扫描位置虚拟页面的 R 位为 0,就将该页淘汰换出。
- 由于每个页面在换出之前多给了一次机会,即 R 位从 1 变成 0 的那次机会,所以该算法也常被称为是二次机会算法,简称 SCR(Second Chance Replacement)。
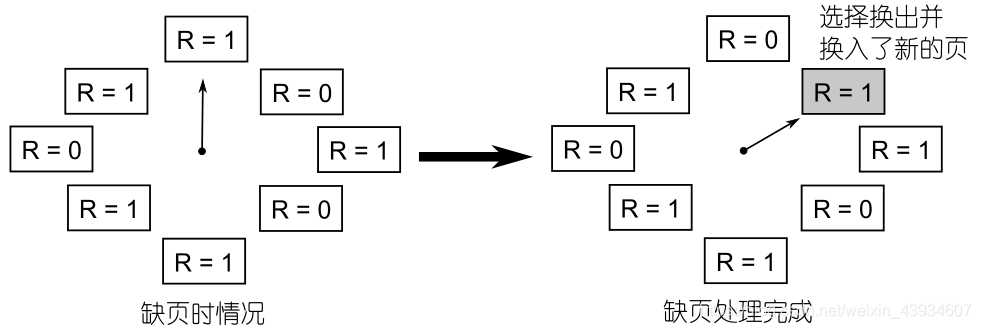
SCR 算法就退化成为 FIFO 算法
- 如果所有页的 R 位都为 1,缺页处理时扫描指针会从当前位置扫描一遍,并将所有页的 R 位都置为 0,然后淘汰掉当前扫描指针处的那个页面,扫描指针后移
- 当再次出现缺页时,由于时间间隔较长,所有页的 R 位又都被置为 0,经过同样的扫描以后,换出的又是扫描指针指向的那个页面,扫描指针继续后移。
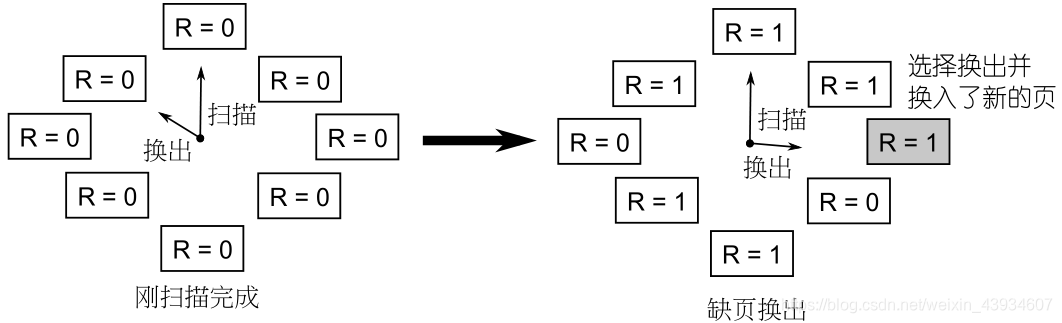
需要对“最近”有一个合适的估计:拆分扫描指针(定期扫描,只清零不换出)和换出指针(缺页时只换出,不清零)
-
再引入一个扫描指针,该指针定期的扫描所有页面,并将所有页面中的 R 位都清为 0。
-
当缺页发生时,用换出指针扫描页面,如果页面的 R 位仍然为 0,就进行淘汰换出,此时换出指针只负责换出,不会对页面的 R 位清 0。
页框分配与置换
应该给进程分配多少个物理页框?
- 所有页面淘汰算法都是:发生缺页时,选择某个页进行淘汰。那什么是发生了缺页?
- 分配给进程的所有物理页框都被用完以后又来了一个新的页面请求,但是通过虚拟地址找到页表项后,有效位为 0 ,就会发生缺页
- 分配物理页框方法加上页面淘汰换出算法,再加上页面换入,整个换入换出机制就可以运转了,虚拟内存子系统也就建立起来了
- 从进程自身角度而言,分配给进程的物理页框个数是越多越好
- 但是物理内存的总容量是有限的,不可能给进程分配太多的物理页框数量,因为如果给每个进程分配的物理页框数量太多,系统能支持的并发进程数量就会很少,计算机工作效率就会降低。
- 从操作系统的角度出发,应该给每个进程分配尽量少的物理页框数量,这样进程多可以更充分利用 CPU
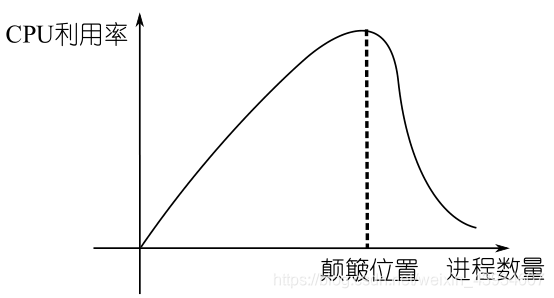
- 随着进程个数的增加,起先 CPU 利用率会上升,这是并发带来的效果。但是当进程个数增大到一定程度以后,CPU 的利用率会急剧下降。因为此时分配给进程的物理页框数量不够,导致频繁的缺页,而一旦缺页就需要通过磁盘读写进行换入换出,所以磁盘要频繁工作。
- 磁盘工作的目的是将页面换入,只有换入页面以后 CPU 才能继续在当前进程上取指执行,所以在换入/换出过程中当前进程无法执行。如果所有进程都要这样频繁地换入换出,CPU 自然就无事可干了,CPU 利用率必然急剧下降。
系统颠簸/抖动
- 内存页和磁盘之间频繁地换入换出,这个现象通常被形象地称为系统颠簸/抖动(Thrashing)。
- 根本原因就是给进程分配的物理页框数量太少,少到没有覆盖住当前进程执行时的那个局部。
- 由于没有覆盖住局部,导致换出去的页面又马上被程序访问,需要换入;
- 当然将需要的页面换入又造成某个马上会被再次访问页面换出,如此不断往复 ······ 系统颠簸就开始了。
- 解决系统颠簸也并不难,只要计算出当前执行的进程需要多大的局部,并保证分配该进程的物理页框数量大于其局部即可
- 如果系统的空闲内存不足,就将某些进程挂起,将其换出到磁盘上,腾出地方来保证分配给每个进程的物理页框个数足够覆盖其局部。
局部置换:工作集模型(Working-Set Model)
-
工作集模型的核心是统计进程在最近一个历史(时间)窗口 ∆ 中访问了哪些页,这些页形成的集合就被称为是工作集,同时这个集合也就用来近似进程当前执行的那个局部,同时这个集合也就用来近似进程当前执行的那个局部
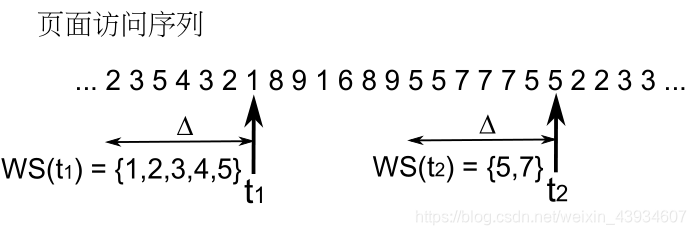
-
工作集模型的关键在于恰当地的设定 ∆,如果 ∆ 太大,工作集会覆盖多个局部,造成内存的浪费;如果 ∆ 太小,工作集又可能覆盖不住局部,造成系统颠簸。在实际系统中,∆ 通常是要随着某些系统参数而自适应调整的
- 如果发现最近一段时间系统整体缺页率偏高,则应该将 ∆ 增大,因为缺页增多很可能是由于没有很好地覆盖局部而造成的。
- 反之可以将 ∆ 调小,这样就可以腾出一些内存空间,让更多的进程进入内存,增大并发度。
全局置换
-
还可以换一个角度来解决进程物理页框个数分配问题,那就是不针对进程分配物理页框,而是将所有物理页框统一管理、全局分配。
- 如果某个进程需要物理页框时,操作系统会去一个全局空闲物理页框链表中取出一个空闲物理页框进行分配
- 同时操作系统会定期地对分配给所有进程的所有页面进行 clock扫描,发现最近一段时间没有被访问的页面,就将其换出到磁盘上,并将对应的物理页框释放到空闲页框链表中。
-
全局置换:clock 算法将所有进程的所有页面组织成环形链表进行全局扫描和全局置换。
- 现在不用为每个进程单独计算需要分配的物理页框数量了,所有进程都去一个全局资源池中获取内存资源。
全局置换缺点
-
如果一个进程可进程的局部大,这个进程将比其他进程获取更多的内存资源。使颠簸变得更加严重。
- 而且进程可以故意设计编码来抢占内存
-
例如:定义一个 1024 行 1024 列的数组 A,数组中的每个元素都是 4 个字节。
main() { long A[1024][1024]; for(j= 0; j<1024; j++) for(i = 0; i<1024; i++) A[i][j] = 0; }- 在数据结构中,二维数组通常都是按行存储的,所以数组 A 的每一行占用一个页面。
- 按照给出的循环方式进行数据访问,每访问一个数组元素以后,都会访问到下一页,产生缺页并从全局空闲物理页框链表中获得一个空闲页。
- 由于最近(假设最近是执行1024 次数组项修改的时间)所有页面都被访问过,所以这些页面都不会被淘汰出去。

















 8861
8861

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









