









1 介绍
年份:2024
会议: 2024CVPR
Wen H, Pan L, Dai Y, et al. Class Incremental Learning with Multi-Teacher Distillation[C]//Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition. 2024: 28443-28452.
本文提出的算法是“Class Incremental Learning with Multi-Teacher Distillation (MTD)”,其核心原理是通过权重置换、特征扰动和多样性正则化技术来寻找多个具有不同机制的教师模型,以增强对新知识的兼容性并减少灾难性遗忘。该算法属于基于知识蒸馏的类别,因为它通过蒸馏策略将多个教师模型的知识传递给学生模型,以实现类别增量学习。
2 创新点
- 多教师蒸馏方法(MTD):提出了一种新的多教师蒸馏方法,用于类别增量学习(CIL),通过找到多个具有不同机制的教师来提高对新知识的兼容性。
- 权重置换:采用权重置换技术将基本模型的参数从一个低损失区域转移到另一个低损失区域,以实现教师模型之间的多样性。
- 特征扰动:对置换后的分支输入进行特征扰动,通过添加从正态分布中采样的扰动,来打破置换参数与原始参数之间的等价性,增加模型的多样性。
- 多样性正则化:提出多样性正则化技术,通过最小化教师嵌入之间的绝对余弦相似度,进一步增强教师模型的多样性。
- 小分支表示:为了减少时间和内存消耗,每个教师被表示为模型中的一个小分支,大部分特征提取层在教师之间共享。
- 与现有CIL蒸馏策略的适应性:将MTD方法与现有的类别增量学习蒸馏策略相结合,并在多个基准测试中展示了显著的性能提升。
- 实验验证:通过在CIFAR-100、ImageNet-100和ImageNet-1000等数据集上的广泛实验,验证了MTD方法在类别增量学习中的有效性。
3 相关研究
- 记忆回放(Memory Replay):
- 存储每个旧类别的代表性样本,并在新任务中回放它们。
- 文献:[iCaRL] [37], [Mnemonics] [26], [CIM] [30]
- [iCaRL] [37] - Sylvestre-Alvise Rebuffi, Alexander Kolesnikov, Georg Sperl, and Christoph H Lampert. iCaRL: Incremental Classifier and Representation Learning. In Proceedings of the IEEE conference on Computer Vision and Pattern Recognition, pages 2001–2010, 2017.
- [Mnemonics] [26] - Yaoyao Liu, Yuting Su, An-An Liu, Bernt Schiele, and Qianru Sun. Mnemonics Training: Multi-class Incremental Learning without Forgetting. In Proceedings of the IEEE/CVF conference on Computer Vision and Pattern Recognition, pages 12245–12254, 2020.
- [CIM] [30] - Zilin Luo, Yaoyao Liu, Bernt Schiele, and Qianru Sun. Class-incremental exemplar compression for class-incremental learning. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, pages 11371–11380, 2023.
- 知识蒸馏(Knowledge Distillation):
- 从先前的模型传递知识到新模型,以减轻遗忘。
- 文献:[iCaRL] [37], [BiC] [52], [LUCIR] [17], [PODNet] [8], [GeoDL] [42], [AFC] [19], [DT-CIL] [4]
- [BiC] [52] - Yue Wu, Yinpeng Chen, Lijuan Wang, Yuancheng Ye, Zicheng Liu, Yandong Guo, and Yun Fu. Large scale incremental learning. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, pages 374–382, 2019.
- [LUCIR] [17] - Saihui Hou, Xinyu Pan, Chen Change Loy, Zilei Wang, and Dahua Lin. Learning a Unified Classifier Incrementally via Rebalancing. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, pages 831–839, 2019.
- [PODNet] [8] - Arthur Douillard, Matthieu Cord, Charles Ollion, Thomas Robert, and Eduardo Valle. PODNet: Pooled Outputs Distillation for Small-Tasks Incremental Learning. In European Conference on Computer Vision, pages 86–102. Springer, 2020.
- [GeoDL] [42] - Christian Simon, Piotr Koniusz, and Mehrtash Harandi. On learning the geodesic path for incremental learning. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, pages 1591–1600, 2021.
- [AFC] [19] - Minsoo Kang, Jaeyoo Park, and Bohyung Han. Class-incremental learning by knowledge distillation with adaptive feature consolidation. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, pages 16071–16080, 2022.
- [DT-CIL] [4] - Yoojin Choi, Mostafa El-Khamy, and Jungwon Lee. Dual-teacher class-incremental learning with data-free generative replay. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, pages 3543–3552, 2021.
- 动态结构(Dynamic Structure):
- 为每个任务分配一个子网络或一个独立的新网络。
- 文献:[AANet] [27]
- [AANet] [27] - Yaoyao Liu, Bernt Schiele, and Qianru Sun. Adaptive Aggregation Networks for Class-incremental Learning. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, pages 2544–2553, 2021.
4 算法
4.1 算法原理
- 多教师蒸馏框架:算法基于知识蒸馏策略,通过从多个教师模型中蒸馏知识来训练学生模型。这些教师模型具有不同的机制,能够提供多样化的知识,有助于学生模型学习新任务时保留旧任务的知识。
- 权重置换(Weight Permutation):为了在教师模型之间创建参数的多样性,算法采用权重置换技术。权重置换可以将模型参数从一个低损失区域移动到另一个低损失区域,从而生成具有不同响应机制的教师模型。
- 特征扰动(Feature Perturbation):在权重置换的基础上,算法对每个教师模型的输入特征进行扰动,通过添加从正态分布中采样的噪声来进一步增加教师模型的多样性。
- 多样性正则化(Diversity Regularization):算法引入多样性正则化技术,通过最小化教师模型嵌入之间的余弦相似度来增强教师之间的差异性,促使教师模型在特征空间中更加正交。
- 小分支结构:为了减少时间和内存消耗,每个教师模型被表示为模型中的一个小分支,共享大部分特征提取层,只有特定的预测分支包含不同的参数。
- 优化策略:算法在类平衡微调阶段优化分支参数,同时对原始模型和分支应用分类损失、之前知识蒸馏损失和当前知识蒸馏损失,以及多样性正则化损失。
- 知识蒸馏:在每个任务学习完成后,使用教师模型的平均输出对新的学生模型进行蒸馏,以保留之前任务的知识。
- 性能提升:通过上述技术,MTD算法能够在学习新任务的同时减少对旧任务知识的遗忘,从而在多个数据集上实现显著的性能提升。
4.2 算法步骤
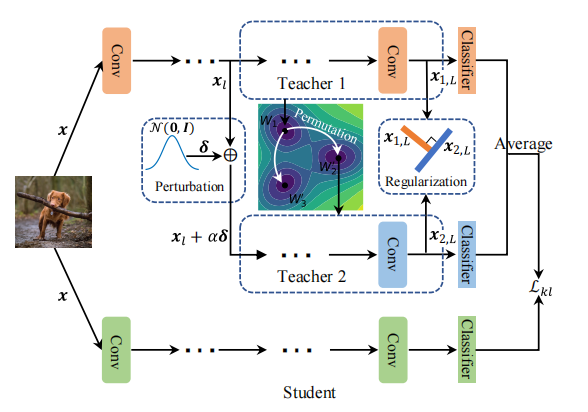
通过在基础模型上应用一系列操作来生成多个具有不同机制的教师模型,这些教师模型能够提供多样化的知识,帮助学生模型在类别增量学习中更好地适应新任务,同时保留旧任务的知识。
- 初始化基本模型:
- 从一个基本的分类模型开始,该模型用于后续生成多个教师模型。
- 权重置换(Weight Permutation):
- 对基本模型的权重进行置换,以创建不同的低损失区域参数配置,形成多个教师模型的初始参数。权重置换是指重新排列神经网络中层的权重矩阵的元素。由于权重矩阵通常是二维的,置换可以通过列的重新排序来实现。
- 对于每一层,随机选择一个置换矩阵,从而生成不同的教师模型。如果需要找到 n个教师模型,可以对初始模型的权重进行 n−1次随机置换(因为初始模型本身作为一个教师模型)
- 特征扰动(Feature Perturbation):
- 对每个置换后的分支(即教师模型)的输入特征进行扰动,通过添加从正态分布中采样的噪声来增加输入的多样性。
- 特征扰动的目的是为了打破权重置换后教师模型之间的等价性,使得每个教师模型在相同的输入下产生不同的响应,从而增加模型的多样性。特征扰动是通过在输入特征上添加噪声来实现的。具体来说,是向从原始模型中桥接过来的特征添加从正态分布中采样的扰动。
- 扰动后的教师模型需要在累积的记忆数据上进行优化,以保持预测质量的同时增加多样性。这通常涉及到分类损失、知识蒸馏损失和多样性正则化损失的联合优化。
- 多样性正则化(Diversity Regularization):
- 多样性正则化(Diversity Regularization)的实现过程涉及在模型训练阶段引入一个额外的正则化项,该正则化项旨在最小化不同教师模型输出嵌入之间的余弦相似度。具体来说,对于每对教师模型,计算它们在倒数第二层输出的嵌入向量的余弦相似度,并通过优化过程使这些相似度的绝对值最小化,从而促使教师模型在特征空间中彼此正交,增加模型间的多样性。这一过程通过在总损失函数中添加一个以余弦相似度为基础的惩罚项来实现,该惩罚项的系数可以调整以平衡多样性与模型性能之间的关系。
- 优化策略:
- 优化策略的实现过程包括在类平衡微调阶段同时优化原始模型和多个教师分支的参数,通过最小化包含分类损失、之前知识蒸馏损失、当前知识蒸馏损失以及多样性正则化损失的综合目标函数。这个过程确保了教师模型在保持预测质量的同时增加多样性,并且能够将累积的知识有效地传递给学生模型,以提高类别增量学习的性能。具体来说,原始模型和每个教师分支都会在累积的记忆数据上进行微调,其中分类损失帮助模型正确分类旧任务,知识蒸馏损失促使教师模型的输出与之前任务的输出保持一致,多样性正则化损失则增强教师模型之间的差异性,最终通过调整这些损失的权重来平衡不同目标。
- 知识蒸馏:
- 在每个任务学习完成后,使用教师模型的平均输出对新的学生模型进行蒸馏,以保留之前任务的知识。
6 思考
(4)图4 的作用
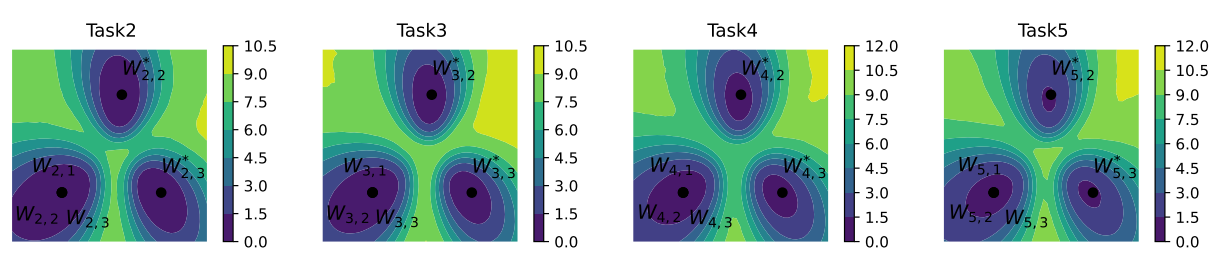
通过“Oracle”方法找到的参数在子空间中的损失景观(loss landscape),提供了一个直观的方式来观察不同教师模型在参数空间中的位置以及它们对应的性能(损失值)。通过这种可视化,研究者可以更好地理解不同教师模型之间的关系,以及它们如何影响模型在增量学习任务中的表现。
- 通过损失景观,可以观察到参数空间中存在多个低损失区域,这些区域代表了模型可能的最优或接近最优的参数配置。这些低损失区域可能被高损失的区域所隔离,即所谓的“高损失山脊”。
- Oracle”方法生成的参数 分布在不同的低损失区域,这表明通过不同的随机种子初始化可以产生多样化的模型参数,这些参数在损失景观中处于不同的位置。


















 1634
1634

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











