






目前你见过的所有神经网络(比如密集连接网络和卷积神经网络)都有一个主要特点,那就是它们都没有记忆。它们单独处理每个输入,在输入与输入之间没有保存任何状态。对于这样的网络,要想处理数据点的序列或时间序列,你需要向网络同时展示整个序列,即将序列转换成单个数据点。例如,你在 IMDB 示例中就是这么做的:将全部电影评论转换为一个大向量,然后一次性处理。这种网络叫作前馈网络(feedforward network)。与此相反,当你在阅读这个句子时,你是一个词一个词地阅读(或者说,眼睛一次扫视一次扫视地阅读),同时会记住之前的内容。这让你能够动态理解这个句子所传达的含义。生物智能以渐进的方式处理信息,同时保存一个关于所处理内容的内部模型,这个模型是根据过去的信息构建的,并随着新信息的进入而不断更新。
循环神经网络(RNN,recurrent neural network)采用同样的原理,不过是一个极其简化的版本:它处理序列的方式是,遍历所有序列元素,并保存一个状态(state),其中包含与已查看内容相关的信息。实际上,RNN 是一类具有内部环的神经网络。在处理两个不同的独立序列(比如两条不同的 IMDB 评论)之间,RNN 状态会被重置,因此,你仍可以将一个序列看作单个数据点,即网络的单个输入。真正改变的是,数据点不再是在单个步骤中进行处理,相反,网络内部会对序列元素进行遍历。
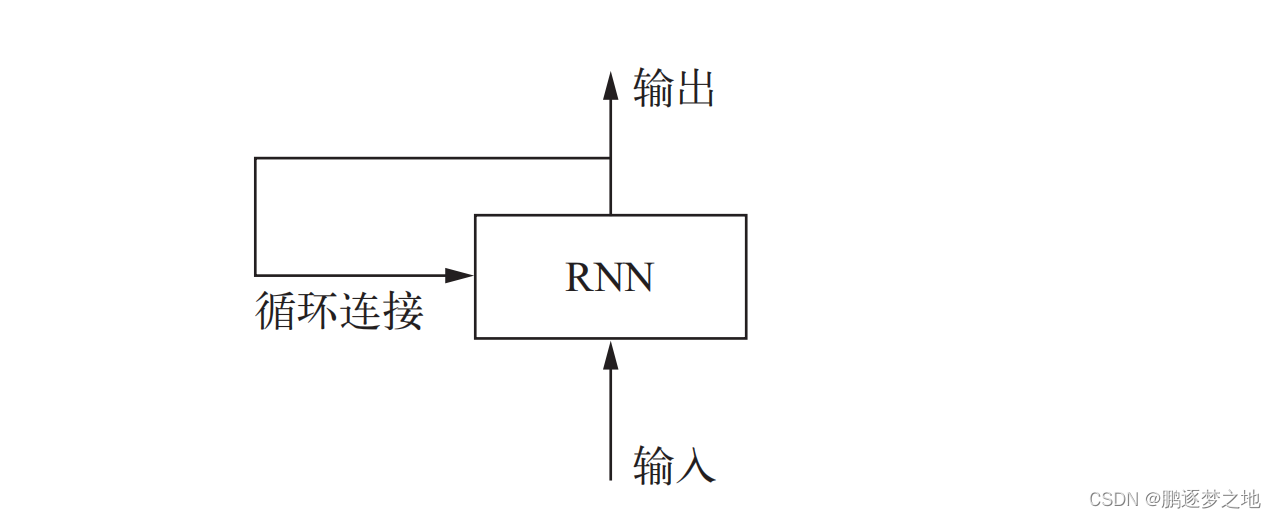
一、循环神经网络(RNN)中的环与状态
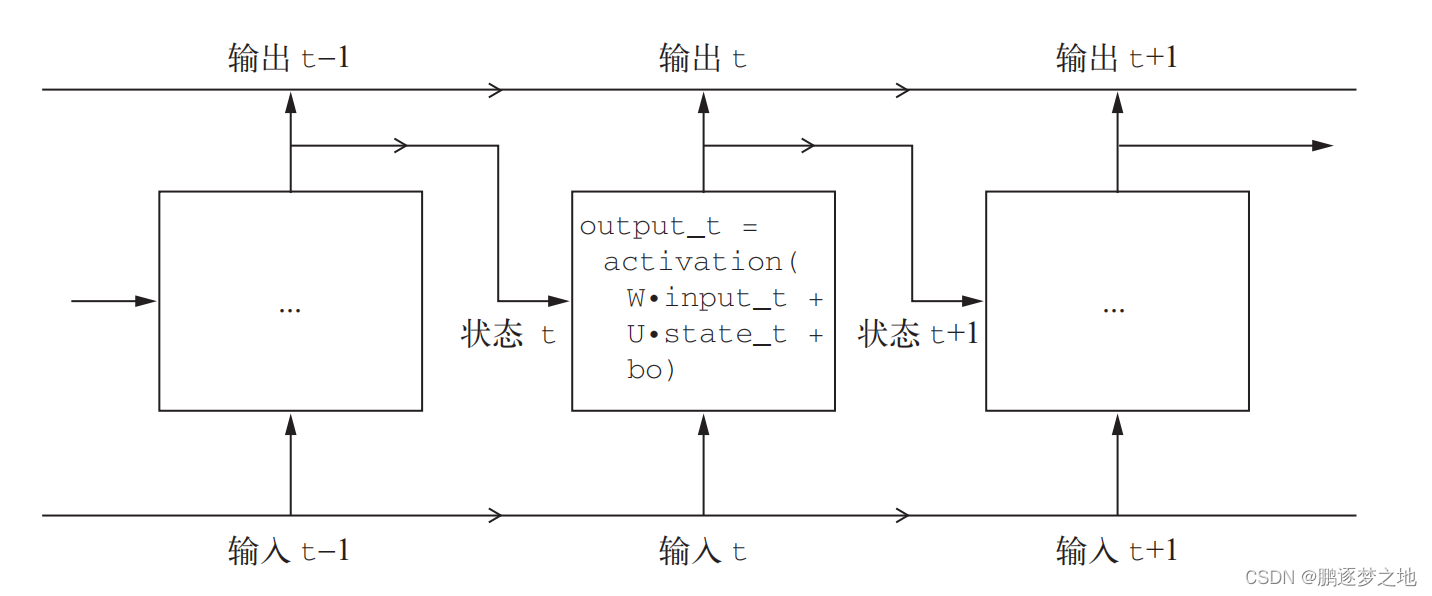
循环神经网络的输入是一个张量序列,我们将其编码成大小为 (timesteps, input_features)的二维张量。它对时间步(timestep)进行遍历,在每个时间步,它考虑 t 时刻的当前状态与 t时刻的输入[形状为 (input_ features,)],对二者计算得到 t 时刻的输出。然后,我们将下一个时间步的状态设置为上一个时间步的输出。对于第一个时间步,上一个时间步的输出没有定义,所以它没有当前状态。因此,你需要将状态初始化为一个全零向量,这叫作网络的初始状态(initial state)。
RNN 伪代码
state_t = 0
for input_t in input_sequence:
output_t = activation(dot(W, input_t) + dot(U, state_t) + b)
state_t = output_t如上图伪代码所示,最开始学习的密集连接网络只有output_t=activation(W,input_t)+b,但在循环神经网络中加入了dot(U,state_t),同时将当前时间输出的状态结果作为下一时间状态的输入。
简单 RNN 的前向传播编写一个简单的 Numpy实现
import numpy as np
timesteps = 100 # 输入序列的时间步数
input_features = 32 # 输入特征空间的维度
output_features = 64 # 输出特征空间的维度
inputs = np.random.random((timesteps, input_features)) # 输入数据:随机噪声,仅作为示例
state_t = np.zeros((output_features,)) # 初始状态:全零向量
W = np.random.random((output_features, input_features))
U = np.random.random((output_features, output_features)) # 创建随机的权重矩阵
b = np.random.random((output_features,))
successive_outputs = []
for input_t in inputs: # input_t 是形状为 (input_features,) 的向量
output_t = np.tanh(np.dot(W, input_t) + np.dot(U, state_t) + b) # 由输入和当前状态(前一个输出)计算得到当前输出
successive_outputs.append(output_t) # 将这个输出保存,到一个列表中
state_t = output_t # 更新网络的状态,用于下一个时间步
final_output_sequence = np.stack(successive_outputs, axis=0) # 最终输出是一个形状为 (timesteps, output_features) 的二维张量 总之,RNN 是一个 for 循环,它重复使用循环前一次迭代的计算结果,仅此而已。
当然,你可以构建许多不同的RNN,它们都满足上述定义。这个例子只是最简单的RNN表述之一,RNN 的特征在于其时间步函数。
output_t = np.tanh(np.dot(W, input_t) + np.dot(U, state_t) + b)
二、长短期记忆(LSTM,long short-term memory)
在循环神经网络中的LSTM层是上面简单的循环层的一种变体,它增加了一种携带信息跨越多个时间步的方法。假设有一条传送带,其运行方向平行与你所处理的序列。序列中的信息可以在任意位置跳上传送带,然后被传送到更晚的时间步,并在需要时原封不动地跳回来。这实际就是LSTM的原理:它保存信息以便后面使用,从而防止较早期的信号在处理过程中逐渐消失。
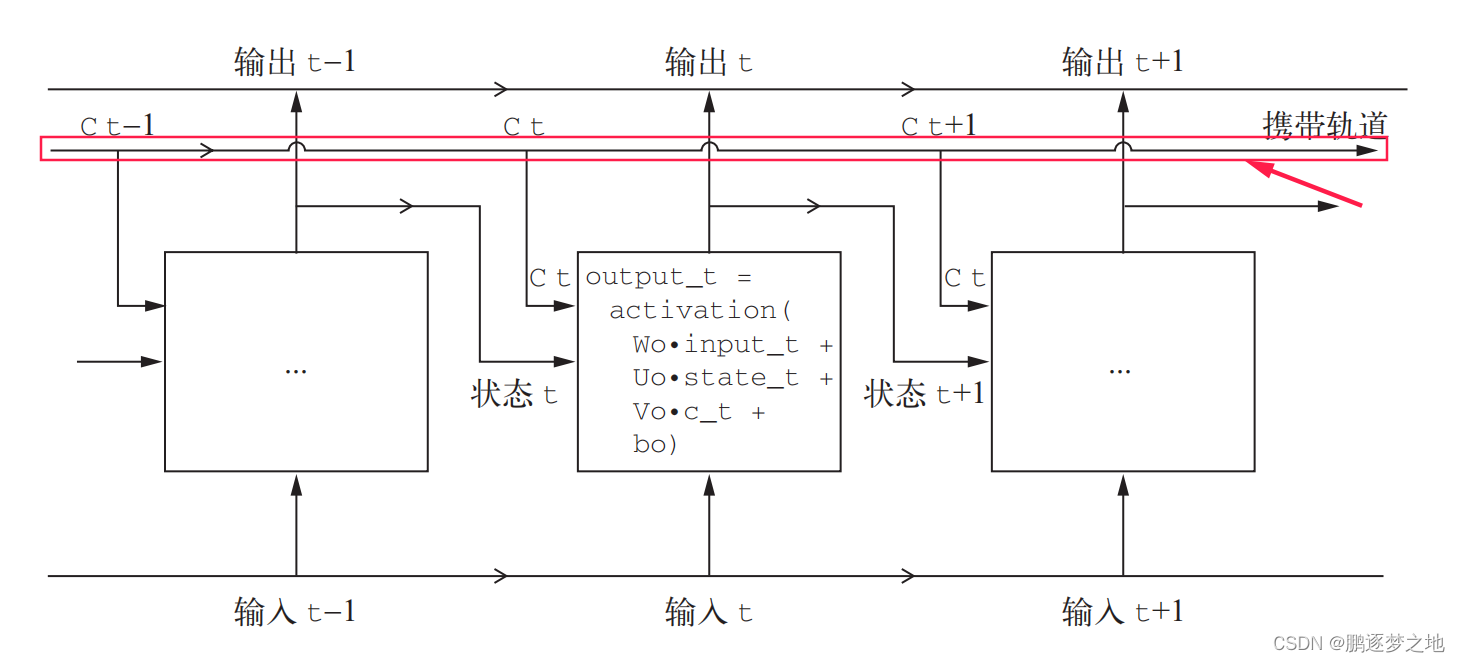 output_t = activation(dot(state_t, Uo) + dot(input_t, Wo) + dot(C_t, Vo) + bo)
output_t = activation(dot(state_t, Uo) + dot(input_t, Wo) + dot(C_t, Vo) + bo)
在LSTM层中添加了额外的数据流,其中携带者跨越时间步的信息。它在不同的时间步的值叫做Ct,其中C表示携带(Carry)。这些信息将会对单元产生以下影响:它将与输入连接和循环链接进行运算(通过一个密集变换,即与权重矩阵作点积,然后加上一个偏置,在应用一个激活函数),从而影响下一个时间步的状态(通过一个激活函数和一个乘法运算)。从概念上来看,携带数据流是一种调节下一个输出和下一个状态的方法。
三、循环神经网络实现IMDB电影评论分类
注:IMDB数据集可以直接使用keras库里相关接口直接下载,下载keras无需下载gpu版本,只是单纯使用其中的数据集,不会再keras环境中训练模型。下载命令如下:
pip install tensorflow -i https://pypi.tuna.tsinghua.edu.cn/simple
pip install keras -i https://pypi.tuna.tsinghua.edu.cn/simple
完整代码如下
import torch
import torch.nn as nn
import torch.optim as optim
import torch.nn.functional as F
from torch.utils import data
from keras.datasets import imdb
from keras.utils import pad_sequences
from tqdm import tqdm
Max_words = 10000
Max_len = 200
Embed_size = 128
Lstm_hid_size = 128
Dropout = 0.2
batch_size_trian = 64
batch_size_eval = 200
batch_size_test = 200
device = torch.device("cuda" if torch.cuda.is_available() else 'cpu')
#下载IMDB数据集,同时将数据集中的文本信息转成向量
(x_train, y_train), (x_test, y_test) = imdb.load_data(num_words=Max_words)
x_train = pad_sequences(x_train, maxlen=Max_len, padding='post', truncating='post')
x_test = pad_sequences(x_test, maxlen=Max_len, padding='post', truncating='post')
trainset = data.TensorDataset(torch.LongTensor(x_train), torch.LongTensor(y_train))
testset = data.TensorDataset(torch.LongTensor(x_test), torch.LongTensor(y_test))
train_size = len(trainset)
indices = list(range(train_size))
# 划分索引
split = int(0.8 * train_size)
train_indices, val_indices = indices[:split], indices[split:]
# 创建训练集和验证集的子集
trainset_subset = torch.utils.data.Subset(trainset, train_indices)
evalset_subset = torch.utils.data.Subset(trainset, val_indices)
# 创建数据加载器
train_loader = data.DataLoader(trainset_subset, batch_size=batch_size_trian, shuffle=True)
eval_loader = data.DataLoader(evalset_subset, batch_size=batch_size_eval, shuffle=False)
test_loader = data.DataLoader(testset, batch_size=batch_size_test)
# 定义模型
class RNN(nn.Module):
def __init__(self, vocab_size, embedding_dim, hidden_dim, output_dim, n_layers, dropout):
super(RNN, self).__init__()
self.embedding = nn.Embedding(vocab_size, embedding_dim)
self.rnn = nn.LSTM(embedding_dim, hidden_dim, n_layers, dropout=dropout, batch_first=True,bidirectional=True)
self.fc1 = nn.Linear(hidden_dim*2, hidden_dim)
self.fc2=nn.Linear(hidden_dim,2)
self.dropout = nn.Dropout(dropout)
def forward(self, text):
embedded = self.dropout(self.embedding(text))
x,_= self.rnn(embedded)
x=F.relu(self.fc1(x))
x=F.avg_pool2d(x,(x.shape[1],1)).squeeze()
x=self.fc2(x)
return x
model = RNN(Max_words, Embed_size,Lstm_hid_size, 1, 2 ,Dropout)
# 定义损失函数和优化器
criterion = nn.CrossEntropyLoss()
optimizer = optim.Adam(model.parameters())
# 定义迭代器
device = torch.device('cuda' if torch.cuda.is_available() else 'cpu')
model = model.to(device)
criterion = criterion.to(device)
def train(epoch, epochs):
# 训练模型
train_loss = 0
model.train()
pbar = tqdm(total=len(train_loader), desc=f'Epoch {epoch + 1}/{epochs}', mininterval=0.3)
for batch_idx, (data, target) in enumerate(train_loader): # 批次,输入数据,标签
data = data.to(device)
target = target.to(device)
optimizer.zero_grad() # 清空优化器中的梯度
output = model(data) # 前向传播,获得当前模型的预测值
loss = criterion(output, target) # 真实值和预测值之前的损失
loss.backward() # 反向传播,计算损失函数关于模型中参数梯度
optimizer.step() # 更新模型中参数
# 输出当前训练轮次,批次,损失等
train_loss += loss.item()
'''torch.save(network.state_dict(), './model.pth')
torch.save(optimizer.state_dict(), './optimizer.pth')'''
pbar.set_postfix(**{'train loss': train_loss / (batch_idx + 1)})
pbar.update(1)
return train_loss / (batch_idx + 1)
def eval(epoch, epochs):
# 测试模型
model.eval()
pbar = tqdm(total=len(eval_loader), desc=f'Epoch {epoch + 1}/{epochs}', mininterval=0.3)
eval_loss = 0
with torch.no_grad(): # 仅测试模型,禁用梯度计算
for batch_idx, (data, target) in enumerate(eval_loader):
data = data.to(device)
target = target.to(device)
output = model(data)
eval_loss += criterion(output, target).item()
pbar.set_postfix(**{'eval loss': eval_loss / (batch_idx + 1)})
pbar.update(1)
return eval_loss / (batch_idx + 1)
def model_fit(epochs):
best_loss = 1e7
for epoch in range(epochs):
train_loss = train(epoch, epochs)
eval_loss = eval(epoch, epochs)
print('\nEpoch: {}\tTrain Loss: {:.6f}\tEval Loss: {:.6f}'.format(epoch + 1, train_loss, eval_loss))
if eval_loss < best_loss:
best_loss = eval_loss
torch.save(model.state_dict(), 'imdb_model.pth')
def test():
# 如果已经训练好了权重,模型直接加载权重文件进行测试#
model_test = model
model_test.load_state_dict(torch.load('imdb_model.pth'))
model_test.eval()
test_loss = 0
correct = 0
criterion=nn.CrossEntropyLoss(reduction='sum')
with torch.no_grad():
for data, target in test_loader:
output = model_test(data)
test_loss += criterion(output, target).item()
pred = output.data.max(1, keepdim=True)[1]
correct += pred.eq(target.data.view_as(pred)).sum()
test_loss /= len(test_loader.dataset)
print('\nTest set: Avg. loss: {:.4f}, Accuracy: {}/{} ({:.0f}%)\n'.format(
test_loss, correct, len(test_loader.dataset),
100. * correct / len(test_loader.dataset)))
if __name__=="__main__":
#model_fit(100)
test()最终测试结果如下

















 780
780

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









